Hadoop2.2集群搭建与配置 例子WordCount成功运行
对于初学者来说,Hadoop的搭建与配置有两个核心:
- HDFS(hadoop distribute file system ,hadoop 分布式文件系统)
hdfs是整个hadoop生态的基础,它具有很多优点和特性,不再多提,我们的目的是让hdfs在我们的集群上跑起来。 - Yarn(Yet Another Resource Negotiator,另一种资源协调者)
反正是一次大改版出现的事物,从那以后不再有jobTracker这样的东西了。简而言之yarn把jobTracker的工作分解了,为的就是不让老版本的namenode压力过大而进行的重新设计优化。
读者应该自行了解过上面两项内容,这里不再赘述,我们直接进行集群的配置与搭建。
Hadoop集群的搭建
1. 准备工作
我使用的是三台物理设备,包括一台我常用的笔记本电脑和一个老旧笔记本电脑和树莓派3b+组成的三节点集群,我现在经常用的电脑作为主节点(namenode),旧笔记本和树莓派作为slave(datanode)。
linux发行版本的选择: 我在两台笔记本上选择的是xubuntu,我觉得这个界面挺清爽的,centOS也是推荐使用的发行版本,树莓派就是安装官方的操作系统Raspbian就好了,不过有点不爽的就是官方发布的只有32位,树莓派3b+是arm64啊喂。(只好凑合用)
说明: 我会用namenode来代表主节点,如无明确说明,datanode将代表两个从节点,datanode2代表从节点2(树莓派),并且如无说明我们都默认在主节点上执行命令。虽然习惯不好,但是我都是默认用root来操作。XD
于是就有了下图。

系统安装不是本文的重点,最好能在安装系统时直接设定好主机名省的在修改。然后配置IP,这点我也不是很懂,反正IPv4手动配置就完了。
使用 ifconfig和env来检查自己的ip和主机名是否正确
不重启修改linux主机名的方法:
vim /etc/sysconfig/network
#修改
HOSTNAME=主机名
#然后执行命令
hostname -b 主机名
紧接着我们配置一下hosts这个文件,这个文件的作用是在本地将主机名解析成ip地址我的hosts内容是这样的,使用如下vim编辑文件 /etc/hosts
vim /etc/hosts
...
127.0.0.1 localhost
192.168.1.103 lijiale-namenode
192.168.1.104 lijiale-datanode
192.168.1.105 lijiale-datanode2
具体作用就是当你想要ssh连接一台节点时,ssh 192.168.1.103与ssh lijiale-namenode的效果是一样的。
接下来我们会发现在使用命令ssh时会出现一些问题,比如connection refused,或者是你明明输入的正确密码却就是不给你通过。但是这些都可以百度解决,不是本文的主要内容。
解决了ssh的问题后,我们是可以直接用ssh 主机名来远程访问一个节点的,这时候就介绍一个非常方便的命令scp,具体事宜大家可以man一下看看,它就是基于ssh协议实现的,所以你必须要先搞定ssh服务。
你可以将它理解为命令cp的加强版,它允许我们将文件远程复制到其他节点上,我们就用这个命令来将刚刚我们编辑好的hosts文件直接发送给两个datanode
我们在namenode上执行命令(如无说明我们都默认在主节点上操作)
scp /etc/hosts lijiale-datanode:/etc/hosts
scp /etc/hosts lijiale-datanode:/etc/hosts
你会发现每次执行上述命令时都会要求你输入目标节点的密码,这是因为我们集群之间还没有实现免密码登录,这肯定是不行的,接下来我们就实现集群搭建的第一个难题,集群间的ssh免密登陆。
2.集群间ssh免密登陆(关键)
到目前为止好像都还没hadoop什么事,一直在捣鼓linux,别急啦准备工作是必须的,你当然可以跳过这一步。但是相信我,如果你跳过这步直接进行后面的内容,以后你输密码会输到你崩溃的。
我突然觉得有必要写一篇关于ssh的学习总结。(我也有些迷。)
大概描述一下接下来的操作在干什么:
所谓免密登陆,靠的就是密钥验证, 公钥和私钥都是成对出现的。 当我拿着私钥去访问拥有私钥对应公钥的计算机时,我就可以直接登陆而无需密码验证。
所以我们做的事情就是在每台机器上生成这样一对密钥,再把每台机器上的公钥都集中在一个文件中,最后再分发到每台机器上。这样每台机器在互相访问时,都能找到自己私钥对应的公钥,所以就都可以免密码登录了。
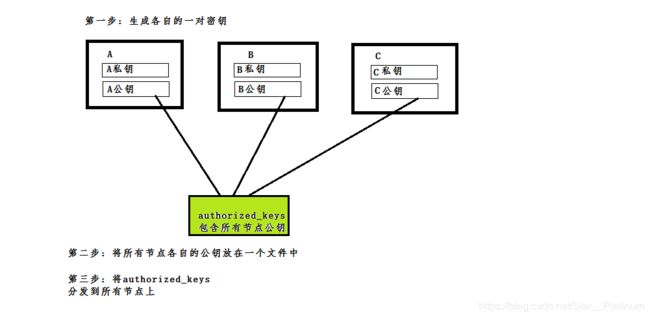
接下来这样就等于实现了免密登陆。
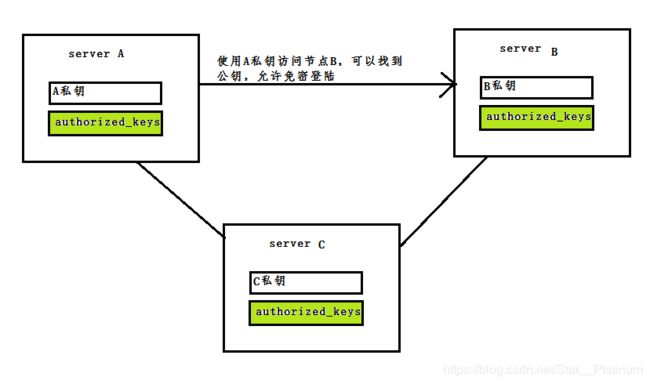
由上图可以很清楚的明白免密登陆的原理。
如果理解了上面所说的,接下来的动作也就很容易明白了。
-
生成密钥
每个节点都要执行如下命令ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa执行后你会看到一个奇怪的矩形,反正我也不懂,你只需要知道这是独一无二的就行。
这时
/root/.ssh目录下会有两个文件id_rsa.pub和id_rsa,这显然就是我们要的公钥(.pub)和私钥了。 -
生成含有本地公钥的authorized_keys文件
这一步就是关键了,这是我们上图中绿色标注的文件,系统中本身是有这样一个文件 的。远程主机将请求登录的用户的公钥保存在登陆后的用户主目录下的$HOME/.ssh/下,而我们一直用root操作,所以操作目录理所应当为/root/.ssh/
执行如下命令:cd /root/.ssh/ cat id_rsa.pub >>authorized_keys chmod 600 authorized_keys如果你理解了上面说的,你就应该知道,这一步我们将自己的公钥保存在了authorized_keys文件中,这样一来我们就能免密登陆我自己。
ssh localhost #正常情况下此时是不需要输入密码的同样的操作,我们需要在另外两个机器上进行,并且验证它们都可以免密码登录自己。
-
生成含有所有节点公钥的authorized_keys文件
到这一步我们已经成功了大半,如题所说,我们需要将各个节点的公钥集中在一起, 好在有现成的命令可以用。我们先将所有节点的公钥集中在主节点的authorized_keys上。 需要分别在两台从节点上执行命令:
#在lijiale-datanode节点执行命令 ssh-copy-id -i /root/.ssh/id_rsa.pub lijiale-namenode #在lijiale-datanode2节点执行命令 ssh-copy-id -i /root/.ssh/id_rsa.pub lijiale-namenode大功告成,你会发现现在任何一个节点访问主节点时都不需要密码,因为主节点的authorized_keys中,已经保存了三个公钥了。
-
分发authorized_keys
现在的主节点上的authorized_keys文件就像一个万能牌,它放在哪,去哪就不需要密码。
继续在主节点使用scp覆盖剩余两个从节点的authorized_keys。scp /root/.ssh/authorized_keys lijiale-datanode:/root/.ssh/authorized_keys scp /root/.ssh/authorized_keys lijiale-datanode2:/root/.ssh/authorized_keys
至此,节点的ssh免密码通信配置完成。
3.Hadoop的安装
Linux下软件的安装向来比较简单,解压就完了。
我们需要的安装包如下:
- hadoop-2.2.0-x64.tar.gz
- JDK1.8(有的操作系统安装时自带jdk)
这里附上hadoop-2.2.0-x64.tar.gz的资源链接
链接:https://pan.baidu.com/s/1MOStB3zHaXb69gH9B-alTw
提取码:y8ps
我的安装路径如下:
Hadoop2.2解压在/home/hadoop/hadoop2.2
jdk解压在/usr/local/jdk1.8
小提示:解压出来的文件名很长,这里可以改的短一点方便后面的配置少打点字。
hadoop-2.2.0-x64.tar.gz在解压出来后并不完美,除了我们要将它改名为hadoop2.2以图方便外,还要在它下面手动创建以下文件夹(新版本可能不再需要这么干,毕竟我这是2.2版本)为了更清晰的展示它的目录结构,这里我就用命令行创建
mkdir /home/hadoop/hadoop2.2/hdfs
mkdir /home/hadoop/hadoop2.2/hdfs/name
mkdir /home/hadoop/hadoop2.2/hdfs/data
mkdir /home/hadoop/hadoop2.2/logs
mkdir /home/hadoop/hadoop2.2/tmp
接下来就需要将hadoop命令写入环境变量,如果你系统中没有安装Java,那你还需要配置以下jdk的环境变量。
使用vim打开profile文件
vim /etc/profile
在profile后追加如下内容
export JAVA_HOME=/usr/local/jdk1.8
export ClASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export HADOOP_HOME=/home/hadoop/hadoop2.2
export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
export HADOOP_LOG_DIR=/home/hadoop/hadoop2.2/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
注意 : .都不能少,一字不落的写在文件最后。
profile文件很关键,要是不小心改坏了系统也会瘫痪,所以必须谨慎操作。
4.Hadoop的配置文件
我们需要修改的配置文件有8个,它们都在/home/hadoop/hadoop2.2/etc/hadoop下,我将它们分为三类
- 环境变量导入
- hadoop-env.sh
- mapred-env.sh
- yarn-env.sh
- 关键配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- slave标识文件
- slaves
其中环境变量导入下面的三个文件,其实内容不需要变化太多,你会发现里面的JAVA_HOME都是被注释的,你只需要取消注释(删去#)将你的JAVA_HOME写到后面即可(“=”后不要加空格)。这里就不在给出修改后的配置文件
关键配置文件中很多都是空的,那是Hadoop要求用户必须做出的配置选项,下面依次列出我的配置文件(内含注释)。
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://lijiale-namenode:9000/value>
<description>设定 主结点的主机名以及端口description>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/hadoop2.2/tmpvalue>
<description>存储临时文件的目录description>
property>
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>lijiale-namenode:50070value>
<description>NameNode地址和端口description>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>lijiale-datanode:50090value>
<description>SecondNameNode 地址和端口description>
property>
<property>
<name>dfs.replicationname>
<value>3value>
<description>设定HDFS存储文件的副本数,默认为3description>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/hadoop/hadoop2.2/hdfs/namevalue>
<description>namenode用来持续存储命名空间和交换日志的本地文件系统路径description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/hadoop/hadoop2.2/hdfs/datavalue>
<description>DataNode在本地存储块文件目录的列表description>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///home/hadoop/hadoop2.2/hdfs/namesecondaryvalue>
<description>设置secondarynamenode存储临时镜像的本地文件系统路径,如果这是一个用逗号分隔的文件列表,则镜像将会冗余复制到所有目录description>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
<description>是否允许网页浏览HDFS文件description>
property>
<property>
<name>dfs.stream-buffer-sizename>
<value>131072value>
<description>默认是4KB,作为Hadoop缓冲区,用于Hadoop读HDFS的文件和写HDFS的文件,还有map的输出都用到这个缓冲区容量,对于现在的硬件,可以设置128KB(131072),甚至是1MB(太大了map和readuce任务可能会内存溢出)description>
property>
configuration>
mapred-site.xml(这个文件原名为mapred-sire.xml.template,需要删掉.template后缀)
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>lijiale-namenode:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>lijiale-namenode:19888value>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>lijiale-namenodevalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager,addressname>
<value>lijiale-namenode:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>lijiale-namenode:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>lijiale-namenode:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>lijiale-namenode:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>lijiale-namenode:8088value>
property>
configuration>
slaves这个文件,只写主机名,被写入的主机名将作为从节点,对于我的集群,我的slaves文件内容为
lijiale-datanode
lijiale-datanode2
分别为我的老笔记本和树莓派主机名。
回顾一下,第3步hadoop的安装和第4步hadoop的配置,目前还都是在主节点上进行的操作,同样的操作我们需要在另外两个从节点上再来一次。所有的环境变量,目录结构,配置文件内容,对于我这三台机器来讲都是相同的。
小提示:你可以把第4步中提到的8个配置文件都提取出来,然后一起扔到/home/hadoop/hadoop2.2/etc/hadoop下全部替换即可完成第4步。
也就是说第3步,第4步分别在三台机器上完整再做一遍。 都完成后,我们终于可以进入最后一步了。
5.格式化并启动hadoop
在主节点执行命令:
hadoop namenode –format
如果看到有返回 Exiting with status: 0就证明格式化成功。
接着启动hdfs和yarn
主节点依次执行命令:
start-dfs.sh
start-yarn.sh
执行完毕后在各个节点执行命令 jps如能分别看到如下结果则证明hdfs和yarn已经在你的集群上跑起来了。
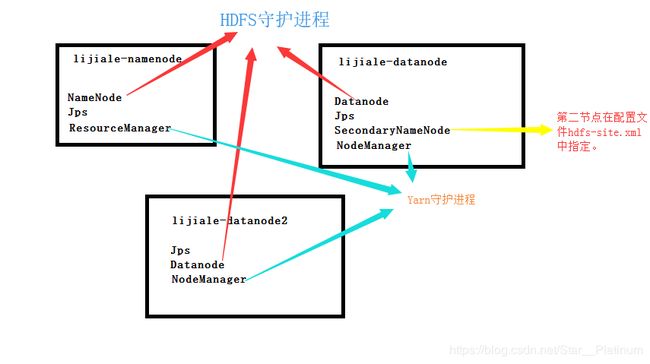
之所以没用实际操作截图是因为,我觉的这样画图的方式更加直观,也加深了我的理解。
接下来我们就能跑一个hadoop自带的词频统计程序了
Wordcount 运行(英文)
它是Hadoop自带的一个集群验证程序,可以对英文进行词频统计。
HDFS是一套独立于操作系统的文件系统,在被格式化后其实就是一个空的/,
因为hadoop生态下的所有软件几乎都是基于HDFS运作的,WordCount案例也不例外,我们需要先将一份文件提交到HDFS上中,在这之前创建文件夹等操作其实都无太大变化。
#在HDFS上创建文件夹,用于存放待统计的文件
hdfs dfs -mkdir /data
hdfs dfs -mkdir /data/wordcount #这里应该有参数可以递归创建,我没有仔细查过
#output文件夹用于存放输出结构
hdfs dfs -mkdir /output
#向HDFS上传待统计文件
hdfs dfs -put /home/hadoop/hadoop2.2/etc/hadoop/core_site.xml
#运行wordcount案例 执行如下命令
hadoop jar /home/hadoop/hadoop2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount
我亲测成功执行了。
可以在浏览器中输入lijiale-namenode:8080找到作业成功运行的记录。
如果觉得太快了感受不到程序在跑的快乐,那就可以放多个文件,重新执行上述命令,但是要记得手动删除目录/output/wordcount否则会报错。