刚开始学习爬虫的时候大概了解了一下scrapy,但是后面在工作中并没有使用scrapy,所以就忘记了大概的用法。最近想重新学习一下scrapy,就想爬一下煎蛋的妹子图练一下手,但是在实际操作的时候,发现请求返回的内容里面并没有图片的链接:
但是我们打开控制面板后,可以看到图片的url:
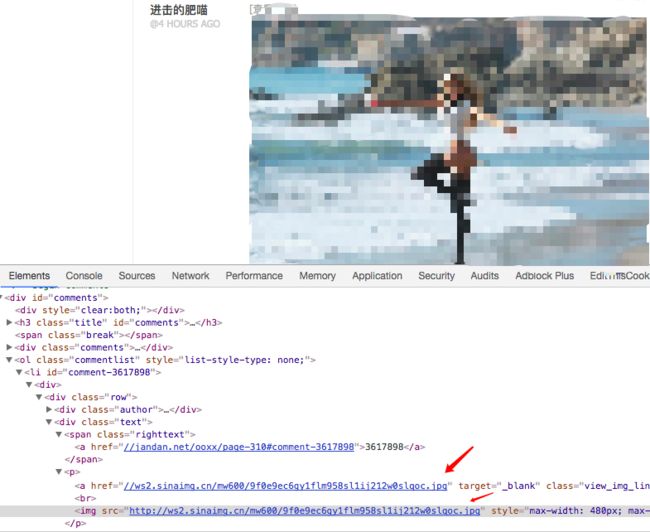
所以我一开始以为它是异步加载的,但是查看网络传输的时候并没有看到它后续请求,所以就想着图片的地址会不会已经在返回的页面里,只是后续通js把它解析出来,所以再次回到返回的页面查看,发现了一个比较重要的东西,img-hash:
 6fadiP6jpEOinbyOjDMf5F1MT01mhMHpB0oC562st3bqZwhPR+OhO+YvbyrNqKyKMmBNGSDh7Gk0I+B+zcKmrgCm3n1M0bXlNjhOjdDps9/hCO039Uo2+w
6fadiP6jpEOinbyOjDMf5F1MT01mhMHpB0oC562st3bqZwhPR+OhO+YvbyrNqKyKMmBNGSDh7Gk0I+B+zcKmrgCm3n1M0bXlNjhOjdDps9/hCO039Uo2+w
可以看出它一开始是一个空白的图片,然后在onload的时候会调用jandan_load_img方法加载图片,而img-hash就很有可能保存着图片的url
然后全局搜索jandan_load_img这个方法,可以发现它在一个js里面:http://cdn.jandan.net/static/min/xxxxxxxxxxxxxxxxxxxxxxx.js(在实际操作中名字不一定相同,但是路径都是一样的)。我们对这个函数下断点:
可以看到e就是img-hash,经过S45fAAhlWwSoItVgdyMFW4jIPId52kxV方法调用后返回的就是图片的url,我们再看一下这个函数:
function S45fAAhlWwSoItVgdyMFW4jIPId52kxV(n, k, x, f) {
var k = k ? k : "DECODE";
var x = x ? x : "";
var f = f ? f : 0;
var g = 4;
x = md5(x);
var w = md5(x.substr(0, 16));
var u = md5(x.substr(16, 16));
if (g) {
if (k == "DECODE") {
var t = n.substr(0, g)
} else {
var b = md5(microtime());
var d = b.length - g;
var t = b.substr(d, g)
}
} else {
var t = ""
}
var r = w + md5(w + t);
var m;
if (k == "DECODE") {
n = n.substr(g);
m = base64_decode(n)
} else {
f = f ? f + time() : 0;
tmpstr = f.toString();
if (tmpstr.length >= 10) {
n = tmpstr.substr(0, 10) + md5(n + u).substr(0, 16) + n
} else {
var e = 10 - tmpstr.length;
for (var p = 0; p < e; p++) {
tmpstr = "0" + tmpstr
}
n = tmpstr + md5(n + u).substr(0, 16) + n
}
m = n
}
var h = new Array(256);
for (var p = 0; p < 256; p++) {
h[p] = p
}
var q = new Array();
for (var p = 0; p < 256; p++) {
q[p] = r.charCodeAt(p % r.length)
}
for (var o = p = 0; p < 256; p++) {
o = (o + h[p] + q[p]) % 256;
tmp = h[p];
h[p] = h[o];
h[o] = tmp
}
var l = "";
m = m.split("");
for (var v = o = p = 0; p < m.length; p++) {
v = (v + 1) % 256;
o = (o + h[v]) % 256;
tmp = h[v];
h[v] = h[o];
h[o] = tmp;
l += chr(ord(m[p]) ^ (h[(h[v] + h[o]) % 256]))
}
if (k == "DECODE") {
if ((l.substr(0, 10) == 0 || l.substr(0, 10) - time() > 0) && l.substr(10, 16) == md5(l.substr(26) + u).substr(0, 16)) {
l = l.substr(26)
} else {
l = ""
}
} else {
l = base64_encode(l);
var c = new RegExp("=","g");
l = l.replace(c, "");
l = t + l
}
return l
}
这个函数除了将hash值解析出url(DECODE)之外,似乎还可以将进行加密操作(ENCODE),但是我只需要解密部分的功能,所以在重写的时候只需要实现解密部分的功能就好了
python实现如下:
# 由于函数的x是会更新的,所以这里原来的代码不通用,具体请看下面的实现
更新
decrypt()方法中的x参数更新了:
当初测试时在两个新的会话中,x的值是一样的,所以我就以为它是不变的,但是现在看来它是会周期性更新,所以需要从js中匹配出它的值_pat = re.compile('f\.remove\(\);var c=.+?\(e,"(.+?)"\)'),js地址可以从html中解析出。

# python2 & python3
import base64
import re
import requests
import sys
from hashlib import md5
from lxml import etree
_pat_x = re.compile('f\.remove\(\);var c=.+?\(e,"(.+?)"\)')
if sys.version_info[0] == 2: # python2
to_int = ord
else: # python3
to_int = int
page_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.8',
'Host': 'jandan.net',
'Upgrade-Insecure-Requests': '1',
'Referer': 'http://jandan.net',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
}
js_headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.8',
'Host': 'cdn.jandan.net',
'Referer': 'http://jandan.net',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
}
def decrypt(n, x):
"""
:param n: img-hash
:param x: x from js
:return:
"""
g = 4
x = md5(x.encode('utf8')).hexdigest()
w = md5(x[:16].encode('utf8')).hexdigest()
u = md5(x[16:].encode('utf8')).hexdigest()
t = n[:g]
r = w + md5((w + t).encode('utf8')).hexdigest()
n = n[g:]
m = base64.b64decode(n + (4 - len(n) % 4) * '=')
h = list(range(256))
q = [ord(r[i % 64]) for i in range(256)]
o = 0
for p in range(256):
o = (o + h[p] + q[p]) & 0xFF
h[p], h[o] = h[o], h[p]
l = ''
v = 0
o = 0
for p in m:
v = (v + 1) & 0xFF
o = (o + h[v]) & 0xFF
h[v], h[o] = h[o], h[v]
l += chr(to_int(p) ^ (h[(h[v]+h[o]) & 0xFF]))
l = l[26:]
if not l.startswith('http:'):
l = 'http:' + l
return l
def get_x(js_url):
"""
:param js_url: js_url from page
:return:
"""
js = requests.get(js_url, js_headers)
x = _pat_x.search(js.text).group(1)
return x
def request_url(url):
resp = requests.get(url, headers=page_headers)
doc = etree.HTML(resp.content)
js_url = doc.xpath('//script[contains(@src, "cdn.jandan.net/static/min")]/@src')[0]
if not js_url.startswith('http:'):
js_url = 'http:' + js_url
x = get_x(js_url)
hash_images = doc.xpath('//*[@class="img-hash"]/text()')
image_urls = []
for item in hash_images:
url = decrypt(item, x)
image_urls.append(url)
return image_urls
if __name__ == '__main__':
image_urls = request_url('http://jandan.net/ooxx')
for url in image_urls:
print(url)
