微服务应用开发进阶①链路追踪Zipkin
简介
Zipkin 是一款开源的分布式实时数据追踪系统,由基于 Google Dapper 的论文设计而来,由 Twitter 公司提供开源实现,主要功能是聚集来自各个异构系统的实时监控数据,和微服务架构下的接口直接的调用链路和系统延时问题。
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案,集成了Zipkin 。
应用场景: 1、可以知道在那个环节耗时长,解决系统并发瓶颈
2、在旧、复杂系统,根据调用链路优化架构
3、可以简单收集调用信息和报错,协助运维
架构和总览

收集方式:http、kafka、rabbbitmq、activeMq、scribe (日志收集系统)
Facebook的日志收集系统https://github.com/facebook/scribe
存储方式:in Memory、mysql、cassandra、es
流程和概念

##基本单元Span、一次链路调用;多个span组成调用链
traceId:64位或128位,全局唯一,
parentId:父spanid,64位,根span的parentId为空
id:spanid,64位,tranceId内唯一
name:方法名
serviceName:服务名
timestamp:自1970-1-1 00:00:00 UTC的微秒
duration:开始span到结束span的时间,单位微秒
annotations:记录事件,value有一些预定义的值,例如客户端发送(cs),客户端接收(cr),服务端接收(sr),服务端发送(ss)等
tags:记录附加数据SpringCloud2.x简单集成zipkin
下载和启动zipkinServer 默认存储在内存中
# 容器
docker run -d -p 9411:9411 openzipkin/zipkin
# java
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
## Running from Source
github下载源码编译
### 下载指定版本
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec配置zipkinClient 默认使用http的传输方式
### http的方式只需要这个包即可 包含spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-starter-zipkin
spring:
sleuth:
web:
client:
enabled: true
sampler:
probability: 1.0 # 将采样比例设置为 1.0,也就是全部都需要。默认是 0.1
zipkin:
base-url: http://localhost:9411/ # 指定了 Zipkin 服务器的地址
访问http://127.0.0.1:9411/zipkin/ ,如图
Zipkin + Kafka + Cassandra
对cassandra不了解的可以看我cassandra的博客 cassandra博客目录
启动Server
启动zipkinServer连上kafka和cassandra
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=cassandra3 --CASSANDRA_KEYSPACE=zipkin_test --CASSANDRA_CONTACT_POINTS=localhost:9042 --KAFKA_BOOTSTRAP_SERVERS=locahost:9092zipkin-server报错,topic不存在,可能自动创建被关闭了,那我们创建一个topic zipkin(默认topic)
[Producer clientId=producer-1] Error while fetching metadata with correlation id 7 : {zipkin=UNKNOWN_TOPIC_OR_PARTITION}配置zipkinClient
SpirngCloud2.x的变化!!!
相比上面的包,我们需要增加kafka的依赖,网上很多说要引入spring-cloud-sleuth-stream;
但是官网不推荐使用并且不支持,正常情况下必然是无法配置成功的,相关的依赖你咋都下来不下来咯。
最终只需要引入以下两个包
org.springframework.cloud
spring-cloud-starter-zipkin
org.springframework.cloud
spring-cloud-stream-binder-kafka
配置文件如下:启用zipkin采集方式为kafka
spring:
kafka:
producer:
max-request-size: 10485760
bootstrap-servers: localhost:9092
request-required-acks: 1
retries: 5
batch-size: 16384
linger: 1
buffer-memory: 134217728
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
sleuth:
sampler:
probability: 1.0
web:
client:
enabled: true
zipkin:
sender:
type: kafka
# base-url: http://localhost:9411测试源码和zipkinClient配置实例: https://github.com/zhouxiaohei/zipkin-test-demo

serviceb调用servicea,产生调用链和依赖;servicec和serviceb雷同,只是从HTTP传输换成kafka传输;
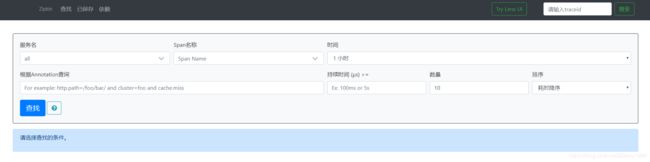
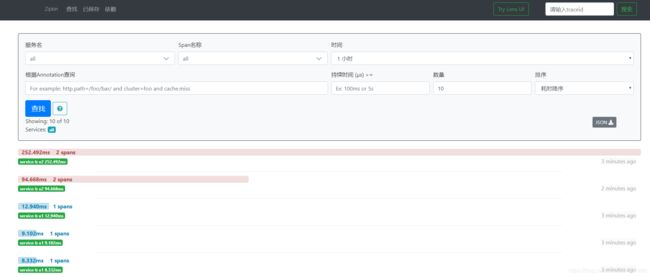
如图,可以看到http请求失败显示为红色;serviceb调用servicea产生了两个完整的span

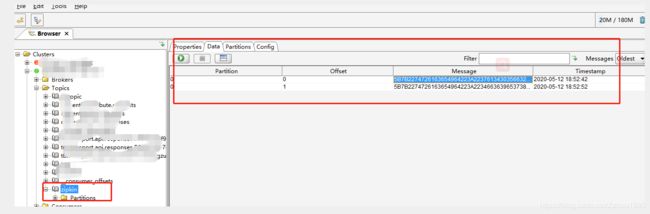
如果换成servicec调用servicea,通过kafka工具我们能看到有kafka消息,类似如下图
生成调用链依赖
如下图所示,我们会发现一个问题,在in Memory的使用方式中,我们自动生成调用链,但是在cassandra中调用链没有了;

其实除了in Memory的方式,其他存储方式我们都需要使用官方zipkin-dependencies去定时生成调用链
## 下载子项目zipkin-dependencies
##方法1-2-3 官网最新、中央仓库指定版本、docker
curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin.dependencies:zipkin-dependencies:LATEST zipkin-dependencies.jar
https://search.maven.org/remote_content?g=io.zipkin.dependencies&a=zipkin-dependencies&v=LATEST
docker run openzipkin/zipkin-dependencies
Zipkin Dependencies默认分析的是当天的数据,可以通过命令参数的方式让Zipkin Dependencies分析指定日期的数据
运行命令:
STORAGE_TYPE=cassandra3 CASSANDRA_KEYSPACE=zipkin_test CASSANDRA_CONTACT_POINTS=localhost:9042 java -jar zipkin-dependencies-2.2.0.jar OK,到这里我们的链路追踪就完成了,如果觉得有用就点个赞或者关注,支持一下吧~
下一篇博客地址,简单分析了zipkinServer数据结构ZipkinServer存储Cassandra数据分析