【Kettle 入门 Windows10 CentOS7】Kettle-8.2.0 入门基础 2019.10.31
Pentaho·Data Integration - Kettle
- 简介
- 软件背景
- Kettle 水壶简介
- 特点
- 资源
- PDI 构架
- PDI 客户端
- PDI 服务器
- 核心概念
- Transformation
- Job
- 变量
- Kitchen命令行选项
- 部署
- Windows
- Linux
- 集群部署
- 案例
- 1. RDBMS --> RDBMS Trans
- 2. R --> R Job
- 3. Hive --> HDFS Trans
- 4.HDFS --> HBase Trans
- 资源库/存储库
- Database Repository
- File Repository
- 调优
简介
软件背景
2017 Hitachi Data Systems 日立数据系统公司 和 Hitachi Insight Group、Pentaho 三家公司合并至一家新公司—— Hitachi Vantara。顺带一提,日立集团涉及的领域十分广阔,对于计算机存储方面尤为出名,所以他们对于数据方面的扩展也不令人惊讶,应该说是理所当然。
Kettle 为早先的开源项目名称,后来被Pentaho收购,现在的全称为 Pentaho 平台体系中的 Pentaho Data Integration,也就是 数据集成。下文均使用 Kettle 作为简称。为什么使用 Kettle 软件,很简单,穷B不配用付费的产品,hhh。Kettle 是 Pentaho 产品体系中的 免费 完全开源的一环,用用是不收费的。
最后扩展一下 Pentaho 平台体系。Pentaho解决了阻碍组织从海量数据中获取价值的障碍。该平台简化了准备和混合任何数据的过程,并提供了一系列工具,可轻松分析,可视化,探索,报告和预测。Pentaho具有开放性,可嵌入性和可扩展性,其设计旨在确保团队中的每个成员(从开发人员到业务用户)都可以轻松地将数据转化为价值。
主要产品分为2大部分:数据集成Data Integration,商业分析Business Analytics,以及完整的部署安装售后故障服务。
Kettle 水壶简介
Pentaho Data Integration Pentaho 数据集成 (PDI),通过可视化工具来简化编写代码的过程,使可以更快地向分析者交付清理就绪的数据,这样可以减少时间和复杂性。不需要编写SQL或Java或Python代码,组织可以立即从他们的数据中获得真正的价值,这些数据可以来自文件系统、关系数据库、Hadoop等等,这些数据位于云计算或本地环境中。
简答来说:Kettle 水壶 是一款开源,分布式的 ETL数据清洗 工具,纯java编写,可视化操作不用写代码,可在Window、Linux 等诸多平台上运行,数据抽取高效稳定。
PDI客户端(也称为 Spoon 勺子)是一个桌面应用程序,使您能够构建转换以及安排和运行作业。
PDI客户端的常见用途包括:
- 不同数据库和应用程序之间的数据迁移
- 充分利用云,集群和大规模并行处理环境,将大量数据集加载到数据库中
- 数据清理的步骤范围从非常简单到非常复杂的转换
- 数据集成,包括利用实时ETL作为Pentaho Reporting的数据源的能力
- 内置支持缓慢变化的尺寸和替代密钥创建的数据仓库(如上所述)
如果团队需要 ETL(提取,转换和加载)协作环境,Kettle也提供了Pentaho存储库,用于共享 协作 PDI 脚本。
特点
1.开源免费,2.跨平台纯Java编写,3.数据抽取高效稳定,4.图形化操作无编码,5.全面覆盖数据库、数仓,6.定时工作流
资源
Hitachi Vantara 公司中文官网:https://www.hitachivantara.com/zh-cn/home.html
Pentaho 平台主页:https://www.hitachivantara.com/zh-cn/products/big-data-integration-analytics.html
Data Integration Kettle 新闻主页:https://community.hitachivantara.com/s/article/data-integration-kettle
Pentaho 系列产品下载地址: https://sourceforge.net/projects/pentaho/files/
Kettle 2019.10.30最新稳定版“:https://sourceforge.net/projects/pentaho/files/latest/download?aliId=137249511
Kettle 文档:https://help.pentaho.com/Documentation/8.3/Products/Pentaho_Data_Integration
Kettle 位于 Pentaho系列产品下载地址的 Pentaho x.x / client-tools 路径下的 pdi-ce-x.x.x.x-xx.zip,如下
https://sourceforge.net/projects/pentaho/files/Pentaho 8.3/client-tools/pdi-ce-8.3.0.0-371.zip/download
PDI 构架
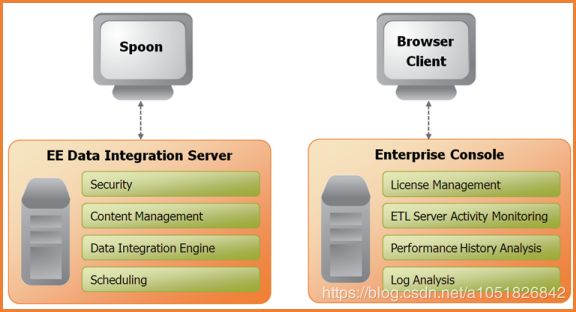
PDI(kettle)是基于 BS 架构实现的服务。
组成:
| 名称 | 描述 |
|---|---|
| Spoon | 通过图形接口,用于编辑作业和转换的桌面应用 / 客户端应用程序【GUI】。 |
| Pan | 一个独立的命令行程序,用于执行由Spoon编辑的转换(Transformation)【命令行】。 |
| Kitchen | 一个独立的命令行程序,用于执行由Spoon编辑的作业(Job)【命令行】。 |
| Carte | Carte是一个轻量级的Web容器,用于建立专用、远程的ETL Server。 |
PDI 客户端
Spoon 勺子 是构建 ETL Jobs 和 Transformations 的设计工具( GUI方式 )。Spoon 以拖拽方式图形化界面进行设计,能够通过 spoon 调用专用的数据集成引擎或者集群。Spoon 还可以为 Jobs 和 Transformations 设计调度时间表。
Pan 与 Kitchen 可以视为 Spoon 执行器,均可执行 由Spoon编辑的 Job 文件,Pan 还可以执行 Transformation 文件。
PDI 服务器
Data Integration Server(Carte) 是一个专用的ETL Server,它的主要功能有:
| 功能 | 描述 |
|---|---|
| 执行 | 通过Pentaho Data Integration引擎执行ETL的作业或转换 |
| 安全性 | 管理用户、角色或集成的安全性 |
| 内容管理 | 提供一个集中的资源库,用来管理ETL的作业和转换。资源库包含所有内容和特征的历史版本。 |
| 时序安排 | 在spoon设计者环境中提供管理Data Integration Server上的活动的时序和监控的服务 |
核心概念
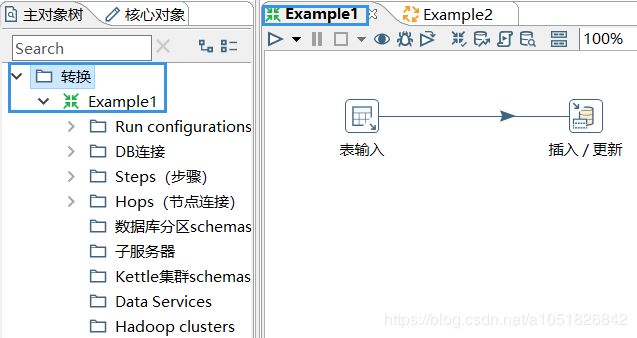
Transformation
转换,Transformation 是由一系列 step(步骤)图形化组件组成的逻辑工作网络。 本质上,是对数据的操作。
例如:step1从文本文件中读取数据,step2过滤,然后step3排序,最后step4将数据加载到数据库。
steps: Transformation构成的基础模块,包含了140多个,它们按照不同功能进行分类: 输入类、输出类、脚本类。每个不同的Step完成某种特定的功能。将这些特定功能的Step组合起来,我们可以制作出一个 Transformation 对象。
Hops:连接 Steps的数据通道(图形化界面中的 有向线) 使得元数据从一个步骤传递到另一个步骤。但实际上并非如此,步骤之间的顺序不是 Transformation 执行的顺序。当执行一个转换时,每个Step都以自己的线程启动,并不断的接受和推送数据。注意:所有的Step都是同时开启的,也就是,我们无法在第一个Step设置变量,然后在后面的Step中使用。
Transformation文件的扩展名为.ktr
Job
Jobs(工作)基于工作流模型(时间调度)的,协调一个或多个数据源、Transformation 执行过程 及其 各个转换间的相关依赖性的ETL活动——可以简单理解为 包含多个转换的,且带有时间调度设定的 转换集合,有向图结构。
ETL Job文件的扩展名为.kjb
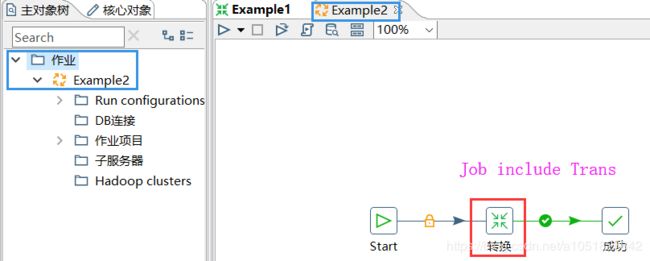
二者区别:
- Transformation是Job的组成部分。
- Job的每一个步骤都需要等待前面的步骤执行完毕后,才会执行——控制依赖。而Transformation则是全部启动,每个step都是一个单独的线程
变量
根据作用范围,定义为2类:环境变量,Kettle变量
环境变量:在所有使用JVM允许的Application中可见。使用Set environment variables设定。唯一问题是,如果在同一个PDI Server 中执行多个 Job 同时使用/改变一个 环境变量时,可能会产生冲突。
Kettle变量:用于在一个小的动态范围内,存储少量信息——局部变量, 作用范围在一个Job或转换,也可以是 父工作、祖父工作 或 根工作,使用 Set variable。
Kitchen命令行选项
kitchen.bat | kitchen.sh -options | /options 均可。
-option=? | -option:? | -option ? 均可。
/rep : Repository name 资源库名(任务所在库)
/user : Repository username 帐号
/pass : Repository password 密码
/job : The name of the job to launch 任务名
/dir : The directory (dont forget the leading /)
/file : The filename (Job XML) to launch 任务文件路径
/level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 日志级别
/logfile : The logging file to write to 日志写出路径
/listdir : List the directories in the repository 列出资源库中的目录s
/listjobs : List the jobs in the specified directory 列出指定目录下的任务s
/listrep : List the available repositories 列出可获取的资源库
/norep : Do not log into the repository 不记录日志在资源库中
/version : show the version, revision and build date 显示版本
/param : Set a named parameter =. For example -param:FOO=bar 设置参数
/listparam : List information concerning the defined parameters in the specified job 列出参数信息
/export : Exports all linked resources of the specified job. The argument is the name of a ZIPfile. 导出所有与指定任务关联的资源为一个ZIP文件
执行实例:
kitchen.bat /norep -file=D:/kettledata/mysal2orcle.kjb >> kitchen_%date:~0,10%.log
解析:Kitchen执行器 执行 路径为D:/kettledata/mysal2orcle.kjb的任务,将结果输出到 kitchen_%date:~0,10%.log 文件中
部署
Windows
提前准备:8.2版本,pdi-ce-8.2.0.0-342.zip【已安装Java 1.8】
一般情况下,均是在 Windows环境下,进行ETL Job编写,然后连接至远程Carte Server执行。
1.安装JDK 1.8版本,2.解压 pdi-ce-8.2.0.0-342.zip 至合适路径,3.双击 Spoon.bat 启动图形化界面。
Linux
提前准备:8.2版本,pdi-ce-8.2.0.0-342.zip【已安装Java 1.8】
1.安装包上传到服务器解压。2.偷懒》将Windows下的 当前用户家目录下的 .kettle目录拷贝至linux的当前用户家目录下。
命令实例:运行数据库资源库中的转换:
./pan.sh -rep=my_repo -user=admin -pass=admin -trans=stu1tostu2 -dir=/
-rep:资源库名称,-user:资源库用户名,-pass:资源库密码,-trans:运行转换名称,-dir:转换文件所在资源库目录
集群部署
1.修改 data-integration/pwd 目录下的配置文件.
<slaveserver>
<name>mastername>
<hostname>hadoop102hostname>
<port>8080port>
<master>Ymaster>
<username>clusterusername>
<password>clusterpassword>
slaveserver>
<masters>
<slaveserver>
<name>mastername>
<hostname>hadoop102hostname>
<port>8080port>
<username>clusterusername>
<password>clusterpassword>
<master>Ymaster>
slaveserver>
masters>
<report_to_masters>Yreport_to_masters>
<slaveserver>
<name>slave1name>
<hostname>hadoop103hostname>
<port>8081port>
<username>clusterusername>
<password>clusterpassword>
<master>Nmaster>
slaveserver>
<masters>
<slaveserver>
<name>mastername>
<hostname>hadoop102hostname>
<port>8080port>
<username>clusterusername>
<password>clusterpassword>
<master>Ymaster>
slaveserver>
masters>
<report_to_masters>Yreport_to_masters>
<slaveserver>
<name>slave2name>
<hostname>hadoop104hostname>
<port>8082port>
<username>clusterusername>
<password>clusterpassword>
<master>Nmaster>
slaveserver>
2.xsync分发整个安装目录至 hadoop103 hadoop104
3.分别启动进程:carte.sh hadoop102 8080、carte.sh hadoop103 8081、carte.sh hadoop104 8082
4.访问Web页面:http://hadoop102:8080
案例
1. RDBMS --> RDBMS Trans
MySQL–》MySQL
需求:将stu1的数据按id同步到stu2,stu2有相同id则更新数据
# 表1
create database kettle;
use kettle;
create table stu1(id int,name varchar(20),age int);
create table stu2(id int,name varchar(20));
insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
insert into stu2 values(1001,'wukong');
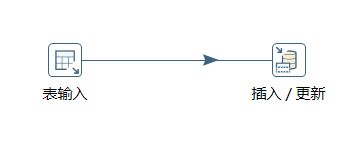
- 文件——》新建——》转换(Ctrl+N)
- 左侧核心对象·输入和输出中,拉出 表输入 和 插入/更新
- 双击 表输入 对象,填写 MySQL 配置,测试成功
- 摁住 Shift 左键点击 表输入 ——》连线至 插入 / 更新
- 双击 插入/更新 对象,点击 获取和更新字段 按钮,再填写 更新字段,查询关键字相关配置
- 保存转换(Ctrl+S),启动(F9)
- 去 mysql 查询转换运行结果【执行前,需要先将 链接 MySQL 数据库的 JDBC驱动.jar 放入 lib目录下】
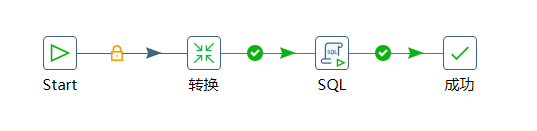
2. R --> R Job
需求:使用 Job 执行案例1的 Transformation,然后再额外在表student2中添加一条数据。
- 文件——》新建——》作业(Ctrl+Alt+N)
- 左侧核心对象·通用和脚本中,拉出 Start,Dummy(什么也不做),转换,SQL
- 双击 Start,类型选择 不需要定时
- 双击 转换,点击浏览,指定 转换文件(案例1.ktr)路径。
- 双击 SQL,数据库连接选择 已设定的 MySQL,编写 SQL脚本
- 保存转换(Ctrl+S),启动(F9)
- 去 mysql 查询转换运行结果
3. Hive --> HDFS Trans
需求:将hive表的数据输出到hdfs的一个文本文件中。
预先配置
-
修改Plugin配置,修改data-integration\plugins\pentaho-big-data-plugin\plugin.properties,
设置 active.hadoop.configuration=hdp26,并将 集群上的同名配置文件拷贝至
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下进行覆盖 -
在Spoon.bat中第119行后面添加参数
"-DHADOOP_USER_NAME=atguigu" "-Dfile.encoding=UTF-8" -
启动虚拟机相关服务:
# HDFS 分别在NN RM节点执行相应命令 start-hdfs.sh start-yarn.sh # hbase Master RegionServer start-hbase.sh # zookeeper zkServer.sh start # hiveserver2 jdbc 服务 # 不建议 hive --service hiveserver2 & hiveserver2
创建 Transformation.ktr 文件
-
文件——》新建——》转换(Ctrl+N)
-
左侧核心对象拉出:输入·表输入x2,输出·文本文件输出,转换·排序记录x2·字段选择,连接·记录集连接
-
双击表输入,新建数据库连接,一般–> Hadoop Hive 2,设置完整选项。用户名为Linux用户名(或者beeline检测HiveServer2 连接时输入的用户名),密码为空。点击完成,再输入SQL语句,然后点击预览。dept与emp两表同
-
摁住shift 连接表输入与排序记录与记录集连接,对排序记录双击设置,或者不设置均可。
-
设置记录集连接,条件为 dept.no = dept.no。
-
双击字段选择,随意选择,想要看到的最终结果字段。
-
双击文本文件输出,字段选项卡——点击最小宽度,否则有可能因为 某些字段的长度太大而报错。再点文件选项卡,点击浏览,将 Location 选择为 HDFS,New一个 Hadoop Cluster,设定好 NN与RM,ZK等等,测试连接成功。出来设定文件名,及扩展名,再点击内容选项卡,将原有的分隔符删除,点击插入TAB按钮,使用
/t来分隔字段。 -
保存,运行,结果为:
deptno empno ename sal
20 7369 SMITH 800
20 7369 SMITH 800
30 7499 ALLEN 1600
30 7521 WARD 1250
30 7499 ALLEN 1600
30 7521 WARD 1250

4.HDFS --> HBase Trans
需求:读取案例3的结果——hdfs上的文件,并将sal大于1000的数据保存到hbase中
预先配置:进入HBase(hbase shell),create ‘people’,‘info’。
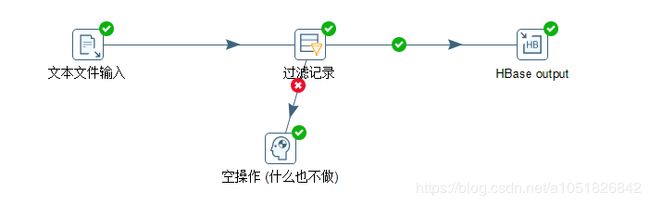
- 设置输入·文本文件输入,文件选项卡选择浏览,HDFS,选择全部文件,选择输入文件output.test;内容选项卡设置分隔符,删除分号,insert TAB,文件类型选择 CSV;字段选项卡,点击获取字段,看情况选择Minimal width,结束
- 设置流程·过滤记录 | 空操作,双击过滤记录,点击左边的黑框,选择字段,中间的黑框条件,右边的2个黑框一个是比较字段,一个是比较一个值,点击比较值黑框输入值,点击右上角+号。点击确定按钮。
- 设置Big Data·HBase output,Configure Connection选项卡,设置Hadoop Cluster为HDFS,浏览本地的HBase-site.xml文件。再点击 Create/Edit mappings,创建 HDFS文件内容至 HBase 列的映射关系,以及RowKey的映射选取,并设定为 HBase哪个表的 XXX 映射,XXX自行取名。先选取HBase Table name,在命名此 Mapping 名称,再点击 Get incoming fields 获取字段,选择Rowkey,设定Column 名称 类型,再点击Save Mapping,最后回到 配置连接选项卡,点击Get table names,选择 HBase表,再点击 Get mapping for the specifiedtable 按钮,获取这个表的Mapping文件,左侧 Mapping Name下拉选择,刚刚设定好的Mapping 名称。点击确定。结束
资源库/存储库
主要用来,跨平台,协同 生成,处理,使用 ETL Job 、Transformation。
分为2种,一种 Database Repository,数据库存储 Job与Transformation;另一种 File Repository,不需要用户名密码就可以访问,但是跨平台使用较为麻烦。
Database Repository
点击右上角Connect,Database connect 可以选择MySQL,Kettle自动创库创表,一步一步填写即可。创建完成后,点击立即连接,或者点击右上角connect选择刚刚创建的Database Repository,默认访问账号密码为admin。
连接完成后,Spoon就会关闭所有未连接时创建的 Job 与 Transformation,相当于新建一个 Spoon-Database Repo版的客户端。此时,文件 --> 打开,就是打开 Database Repository,查询MySQL中存储的 Job 与 Transformation,并且,此时新建的Job 或 Transformation 存储的话,也是存储至 MySQL 中。
File Repository
以本地文件系统创建的 Repository,过程与 Database Repository创建相同,只是跨平台使用比较麻烦。
调优
| Spoon.sh/bat 参数 | |
|---|---|
| JVM | |
| -Xmx2048m | JVM最大内存空间 |
| -Xms1024m | JVM初始化内存空间 |
| -Xmn2g | JVM年轻代内存空间,建议为3/8堆内存 |
| 提交Commit记录数 | 默认1000,可根据总数据量增加 ↑ |
| 能用SQL语句就用SQL | 尽量不使用 Kettle 的 Step 如 split field |
| update转换为delete与insert | 尽量不使用 update |
| 尽量truncate | 尽量不使用 delete |
其他:
尽量使用数据库原生函数执行装载Load ;
尽量缩小输入的数据集的大小;
尽量使用数据库连接池;
插入大量数据的时候尽量把索引删掉;