数据分析EPHS(11)-详解Hive中的排序函数
本篇主要来介绍一下hive中三个常用的排序函数row_number(),rank()和dense_rank()。
1、数据
先来看一下我们的数据。我们使用spark往hive数据库中写入数据:
import spark.implicits._
val seqData = Seq(
("1班","小A","70"),
("2班","小B","84"),
("3班","小C","70"),
("1班","小D","89"),
("1班","小E","70"),
("2班","小F","90"),
("3班","小G","85"),
("3班","小H","68"),
("2班","小I","96"),
("1班","小J",null)
)
val seq2df = seqData
.toDF("class","student","score")
seq2df.write.saveAsTable("default.classinfo3")
数据结构如下:

为了方便后续的介绍,我们将几名同学的成绩设置为同样的分数。在介绍具体的函数前,咱们先简单介绍下over。
row_number(),rank()和dense_rank()都是结合over来进行使用的,over的一般结构如下:
over(partition by col1 order by col2 asc/desc)
一般来说,需要指定以下三项:
1、partition by col1,按哪列进行分组,如果不指定,则默认按全局进行排序,如果指定了一列,则首先对数据按照指定的列进行分组,然后进行组内排序。
2、order by col2,指定按哪列进行排序,这个是必须要指定的,不指定会报错。
3、asc/desc,按升序或降序进行排列,不指定的话,默认是升序。
当然,除了本文介绍的方法外,over还可以结合其他许多函数,如lag/lead/sum等,后续我们会继续介绍。
2、row_number()
使用row_number()进行排序,即使排序列取值相同,仍然会赋予不同的排名,比如我们按照全局进行降序排序:
select
*,
row_number() over(order by score desc) as rank
from
default.classinfo3
输出结果如下:
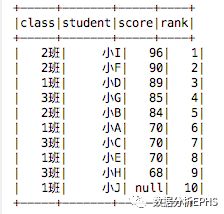
我们有以下结论:
1、可以看到小A、小C、小E的分数都是70分,但排名分别是6、7和8。
2、我们故意在数据中插入了一个null值,可以看到,按降序排的话null值的排名是最低的。如果按升序排列,那么null则会排名第一。
3、row_number()的排序从1开始,而我们上一篇介绍的posexplode是从0开始的。
然后再看下按班级排名的结果:
select
*,
row_number() over(partition by class order by score desc) as rank
from
default.classinfo3
结果如下:
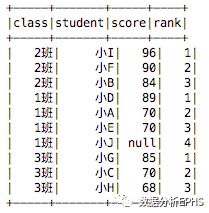
这里留一个小疑惑,对于排序列相同取值的结果,是怎么决定其对应的排名的呢?
3、rank()
再来看下rank,使用rank进行排序,如果排序列取值相同,那么其排名相同,假设有3名同学排名第1,那么下一名同学的排名直接变为第4。通过sql验证下:
select
*,
rank() over(order by score desc) as rank
from
default.classinfo3

可以看到,小A、小C和小E的排名都是第6,可怜的小H直接排名第9了。同时对于null值的排序跟row_number()相同。
4、dense_rank()
最后来看下dense_rank,使用dense_rank进行排序,如果排序列取值相同,那么其排名相同,假设有3名同学排名第1,那么下一名同学的排名是2,而非4。通过sql验证下:
select
*,
dense_rank() over(order by score desc) as rank
from
default.classinfo3
结果如下:
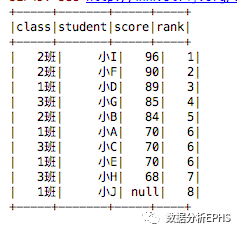
可以看到,小A、小C和小E的排名都是第6,小H排名是第7而非第9。同时对于null值的排序跟row_number()相同。
