高性能MySQL之运行机制
-
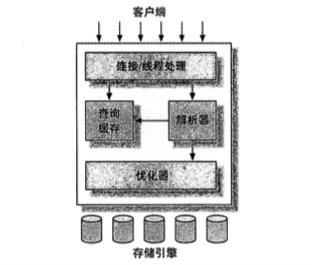
最上层:链接处理,授权认证,安全等处理
-
第二层:查询解析、分析、优化、缓存以及内置函数(如:日期,时间,数学和加密函数)
-
第三层:包含了存储引擎,存储引擎负责数据的存储和提取。
链接管理和安全性
每一个客户端链接都在MySQL服务器进程中拥有一个多线程,在CPU中轮询运行,服务器会负责缓存线程,因此不需要为每一个新建的链接创建或者销毁线程。
MySQL5.5以后支持线程池插件,可以使用池中少量的线程来服务大量的连接。
客户端连接到MySQL之后,服务器会对其进行认证,认证基于用户名,密码和原始主机信息,如何使用了SSL连接,还可以使用证书认证。一旦连接成功,服务器会继续验证客户端的权限。
通常我们通过一个用户名和密码外加一个数据库的地址连接数据库,连接数据库的指令可能如下:
mysql -u username -h 192.168.1.100 -p *****当我们链接MySQL-Server时,他可能会检查我们的用户名密码,除此之外还会检查我们的主机地址,通过主机地址判断是否允许我们登录,比如大部分小型站点会把MySQL和站点文档放置在一个服务器,而且MySQL拒绝了localhost之外的所有连接(不允许远程连接),其次我们还可以在MySQL内设置用户的权限,比如仅允许select(只读)。
优化与执行
MySQL会解析查询,并创建内部数据结构,然后进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引等。
对于SELECT语句,MySQL内部会有一个Query Cache,如果这个缓存内能够找到对应的查询,MySQL则会省去解析和优化工作,直接返回结果。
并发控制
MySQL共有两个层面的并发控制,服务器层与存储引擎层。
读写锁
当有多个连接同时修改一个数据库的某一个表的某一行的时候,会发生什么结果是不确定的。
这有点类似于多线程编程下的线程同步和死锁,事实上MySQL问题的本质似乎也就在这里。
解决这类问题的方法就是并发控制,MySQL在处理这类并发操作的时候可以实现一个由两种类型的锁组成的索系统来解决问题。这两种类型的锁一般被称为共享锁和排它锁。
共享锁是互不阻塞的,也就是多个用户可以同时读取一个资源,所以也叫做读锁。
排它锁是一个写锁会阻塞其他写入和读取操作,只有这样才能保证同一时间只会存在呢一个连接在想数据库内写入,所以也被称作写锁。
粒度锁
一种提高共享资源并发性的方式就是让锁定得对象更具有选择性。尽量只锁定需要修改的部分数据,而不是所有资源。更理想的方式是,只会对要修改的数据片进行精确的锁定。
那么,理论上锁定的资源越小,锁定范围越精确,那么并发性能就会越高。但是事实上,创建一个数据锁也会造成系统的开销,如果系统通过大量的时间来管理锁,而不是存取数据,系统的性能反而会降低。
表锁
粒度锁的精确度是根据需求来决定的,很多时候我们都是在寻找精度和锁开销之间的一个平衡点。
表锁是MySQL中基本的锁策略,并且是开销最小的策略。当用户在对一张表进行写操作之前,首先获得写锁,于是,它阻塞了其他链接的读取和写入操作,只有写锁接触的时候,其他链接才能获得读锁。
不仅如此,MySQL还设置了锁的优先级,在操作列队中MySQL可能会把写入操作插入到读取操作之前。
那么,可以想象一下MySQL的后台实现,可能表锁的是这样是实现的(仅仅是本人猜想):
//下面的代码类似于伪代码,没有参考MySQL源码 //仅仅是本人为了为了理解MySQL表锁的臆测: struct table_lock { /*一个表锁的结构体*/ char* table_name; char* host; }; //实例化一个链接 int* instance = getInstance(); //当执行读取操作的时候,可能需要传递一个table_name instance->readTable(table_name) { //读取操作时候首先要获取表锁的所有权 table_lock.name = table_name; table_lock.host = instance; }
行级锁
行级锁可以最大程度的支持并发处理(同时也带来了最大的锁开销)。行级锁只在存储引擎中实现。
行级锁比表锁更加精确,他把锁的对象精确到了对象的某一行,但也就意味着需要创建更多的锁。
事务
事务其实就是一个独立的工作单元。如果数据库引擎能够完成事务中的每一项操作,那么全组的SQL语句都会被执行,如果任何一条语句因为崩溃或者其他原因无法执行,那么所有语句都不执行。
最简单的例子就是我们银行的转账系统,一个转账操作实际上是从用户账户表里减去对A的账户余额进行修改,同时再去修改B的账户余额,最后再在记录表被记录下这一条操作。SQL语句大致如下:
START TRANSACTION; SELECT balance FROM checking WHERE customer_id = 1010001; UPDATE checking SET balance = balance-200.00 WHERE customer_id = 1010001; UPDATE checking SET balance = balance+200.00 WHERE customer_id = 1010002; INSERT INTO record VALUES('1010001', '1010002', 200.00); COMMIT;这个时候如果执行到第三条语句的时候发现1010002这个账户已经被冻结了,无法接受转账,这个时候按照正常的逻辑,数据库内部10010001这个用户平白无故的就少去了200元,但是10010002并没有收到。
使用事务就完美的解决了这个问题,如果一条语句执行失败,没关系,最终没有commit之前,MySQL是不会进行写入操作的。
ACID
那么有一个专业的名词来描绘这种需求,他叫做ACID:
A—atomicity(原子性):一个事务必须被视为一个不可分割最小工作单元,事务中的操作只要有一个失败则全部回滚(可以理解为,一件事情,要么全做,有一点调点不具备那么全部都不做。)
C—Consistency(一致性):在一个转账事务中,A账户的减少必定对应着B账户的增加,这个状态转换的过程必须保持一致,那么这就是事务的一致性。
I—Isolation(隔离性):通常来说,一个事物所做的修改在最终提交之前,对其他事务是不可兼得。也就是说,事务内部的操作是不会被外部所看到的,只有最终提交之后,我们才能在银行系统中看到两个账户金额的变化(这个时候如何还有一个事务在执行同样的转账操作,那么们是相互隔离的,这看起来并不严谨,事实这里还设计一个隔离级别的问题,这个以后再谈)。
D—durability(持久性):一旦失误提交,所有的修改会永久的保存在数据库中,即使系统崩溃,服务器被损坏,只要硬盘还在,数据就依旧存在。
事务的ACID看起来很简单,但是在应用逻辑中要实现这一点非常难,因为还有相当一部分涉及到用户体验的考虑,你必须保证数据同步的问题,保证数据的一致性和持久性同时还要让用户觉察不到这么复杂的工作。而且,事务所做的操作正如锁一样,需要更多的系统资源,你还需要更强的CPU、更大的内存和更多的磁盘空间。
原文地址