记录向 | 爬虫 | 裁判文书爬取(java)
任务:爬取某地方法院的裁判文书,并将内容抽取出来保存在excel中
爬虫小白,用最简单粗暴的方法爬虫,研究要爬虫的网页源代码结构,用正则表达式抽取出自己想要的内容
我爬取的地方法院的裁判文书网址链接样式如下
地方法院的网址:s_url = "http://xxxxx.xxxxxxxxxx.xxx"
列举裁判文书具体链接的url:m_url = s_url + /paper/more/……
每一篇裁判文书的url:d_url = s_url + /paper/detail/……
抽取m_url的方法
private static void matchMoreLink(ArrayList search_list,String input){
//The function that match links that contains paper links and add it to the search list
//arg0:arraylist that contains the links
//arg1:web page content
Pattern pattern =Pattern.compile("href=\"/paper/more/.*?\"");
Matcher matcher=pattern.matcher(input);
while(matcher.find()){
String l=matcher.group().replace("href=","");
l=l.replaceAll("\"","");
//System.out.println(l+"\n");
l=s_url+l;
if(!search_list.contains(l)) {
//If the link don't in the search list, add it to the list
search_list.add(l);
}
}
}
抽取d_url的方法
private static void matchDetailLink(HashSet set,String input,StringBuffer result) {
//The function that match paper links and add to the set and StringBuffer
//arg0:set that contains paper links
//arg1:web page content
//arg2:StringBuffer for storing the string of links
Pattern pattern =Pattern.compile("href=\'/paper/detail/.*?\'");
Matcher matcher=pattern.matcher(input);
while(matcher.find()){
String l=matcher.group().replace("href=","");
l=l.replaceAll("'","");
l=s_url+l;
if(!set.contains(l)) {
result.append(l+"\n");
set.add(l);
}
}
}使用数组列表存储所有爬下来的m_url,使用集合存储所有爬下来的d_url
由于在这些网页中不仅有许多裁判文书的具体链接,还有一些通向另外的m_url的链接,存在数组列表中,然后按列表顺序t通过m_url爬取下更多的m_url和d_url,判断爬下来的m_url是否已经在list中有,没有就追加在末尾,判断爬下来的d_url是否已经在set中有,没有就加入
(这样做很粗糙,列表和数组的大小有限,没有很多链接的情况下没有什么问题,如果链接太多就不行了,大概查询了解决方法,可以使用数据库、限制爬虫层数等,反正只是先爬下裁判文书的链接,也可以限制一下爬虫层数,将d_url保存在文件中,然后去重之后再根据d_url去爬取裁判文书,去重方法就很多啦,链接去重也比内容去重简单多了)
将列表中的m_url都爬取完之后,也就获得了网站所有的d_url,也就是所有裁判文书的链接
(由于不一定能一次爬取完毕,为了能够多次爬取,可以将爬取过的d_url保存在文件中)
获取了d_url之后,就是通过d_url获取裁判文书内容,但是可能是访问太快或者频繁访问时网站就会使用重定向,不是直接给你返回网页内容,而是给了另一个链接

据说这是反爬虫的一种,可以加好几层,但是还好这个网站只要再顺着给出的链接就可以到达真正的内容页
private static String getHrefContent(String input) throws Exception {
//The function that match the real content and return the content
//arg:The content from the web page that use dynamic output jump
Pattern pattern =Pattern.compile("window.location.href='.*?'");
Matcher matcher=pattern.matcher(input);
String url=null;
if(matcher.find()) {
url=matcher.group().replace("window.location.href=", "");
url=url.replaceAll("'", "");
}
return getPage(url);
}内容页的反爬可能是最难的地方
根据d_url获取的网页源代码的用于显示裁判文书内容的部分是一段javascript代码

百度了一下,得使用javascript获取内容
参考了这篇文章https://blog.csdn.net/u012979457/article/details/80053033

点击圈内的链接,可以获取以下代码

对于这种eval开头的,说明还要js解密获取真正的javascript方法
http://www.cnblogs.com/dudumao/archive/2012/10/05/2712156.html
在上面的博客中GET到了解密工具,懒,直接复制下代码用解密工具解
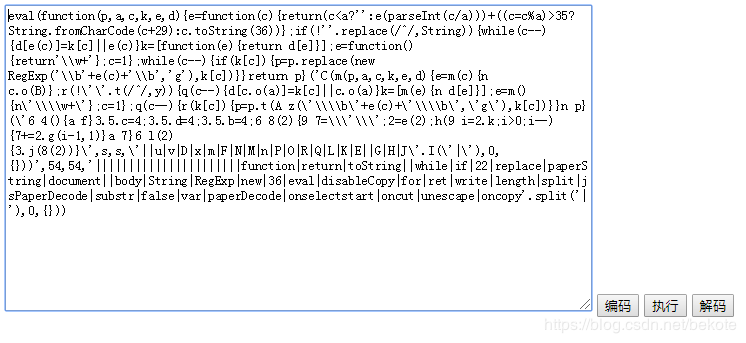
可能会不止加一重,一直点击解码,直到代码中开头没有eval
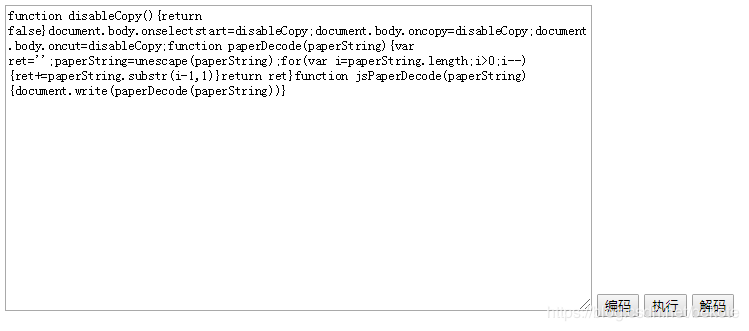
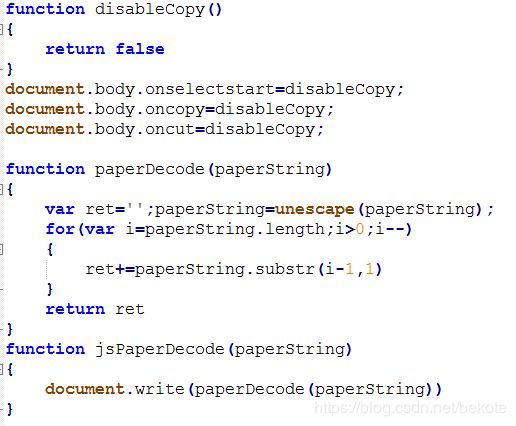
很明显paperDecode就是解密的javascript函数了
再观察一下用于显示内容的javascript函数

每一篇裁判文书其实只有tm[0],tm[1]的值不同,那么我们可以爬虫时把这两个值爬下来再另外解出内容
于是写一段javascript代码保存为getPaper.js,可以接受传入的tm[0],tm[1]的值,返回解出的内容
function paperDecode(paperString){
var ret='';
paperString=unescape(paperString);
for(var i=paperString.length;i>0;i--){
ret+=paperString.substr(i-1,1)
}
return ret
}
var tm=new Array(2)
html='';
show=function(a,b){
tm[0]=a;
tm[1]=b;
html+=paperDecode(tm[0]);
html+=paperDecode(tm[1]);
return html
}在java中,使用javax.script包调用getPaper.js获取内容
public static String getPaper(String input) throws Exception {
//The function that get paper from the content(source code of the web page)
//arg:the content(source code of the web page)
//The web page use javascript to encrypt the paper
String a = null,b=null,result=null;
Pattern pattern =Pattern.compile("tm\\[0\\]=\".*?\"");
Matcher matcher=pattern.matcher(input);
if(matcher.find()) {
a=matcher.group().replace("tm[0]=", "");
}
pattern =Pattern.compile("tm\\[1\\]=\".*?\"");
matcher=pattern.matcher(input);
if(matcher.find()) {
b=matcher.group().replace("tm[1]=", "");
}
//match the encrypted content code
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("javascript");
String jsFileName = "getPaper.js";
FileReader reader = new FileReader(jsFileName);
engine.eval(reader);
if(engine instanceof Invocable) {
Invocable invoke = (Invocable)engine;
result = (String)invoke.invokeFunction("show", a, b);
}
reader.close();
//use a script file(getPaper.js) to get the decrypted content
return result;
}这里踩了一个坑,使用正则匹配时表达式中的中括号前要加两个转移符(“\\")
这样子爬去下来的内容是带html标签的,可以在抽取内容的时候顺便去掉标签
在爬取文书之前先使用poi包生成excel文件(或者之间新建一个excel文件,但要注意excel类型和后续写入使用的类是对应的)
private static File getExcelFile(String filename) {
//The function that create a excel file (filename.xls)
//arg:file name of the target excel file
File file=new File(filename);
FileOutputStream fout=null;
HSSFWorkbook workbook=new HSSFWorkbook();
HSSFSheet sheet=workbook.createSheet("Paper");
sheet.setColumnWidth(0, 3*256);
sheet.setColumnWidth(1, 30*256);
sheet.setColumnWidth(2, 27*256);
sheet.setColumnWidth(3, 20*256);
sheet.setColumnWidth(4, 12*256);
sheet.setColumnWidth(5, 25*256);
sheet.setColumnWidth(6, 80*256);
HSSFCellStyle cellStyle = workbook.createCellStyle();
cellStyle.setWrapText(true);//设置自动换行
HSSFRow row=sheet.createRow(0);
HSSFCell cell;
for(int i=0;i<7;i++) {
cell=row.createCell(i);
cell.setCellType(CellType.STRING);
cell.setCellStyle(cellStyle);
}
row.getCell(0).setCellValue("No");
row.getCell(1).setCellValue("Title");
row.getCell(2).setCellValue("Time");
row.getCell(3).setCellValue("Place");
row.getCell(4).setCellValue("Type");
row.getCell(5).setCellValue("Tag");
row.getCell(6).setCellValue("content");
try {
fout=new FileOutputStream(file);
workbook.write(fout);
fout.flush();
fout.close();
System.out.println("Successfully create a excel file !");
} catch (IOException e) {
System.out.println("Fail to create a excel file");
return null;
}
finally {
if(fout!=null)
try {
fout.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return file;
}由于正文结构很简单,直接用标签把内容抽取出来就行
public static void writeExcel(String paper,File file) {
//The function that write papers into the excel file
//arg0:paper that would like to write to excel
//arg1:target excel file
String title=null,time=null,place=null,type=null,tag=null,content=null;
String html_regex = "<[^>]+>";
//regular expressions for HTML tags
Pattern pattern =Pattern.compile(".*? ");
Matcher matcher=pattern.matcher(paper);
if(matcher.find()) {
title=matcher.group();
title=title.replaceAll(html_regex, "");
}
//match the title of paper
pattern=Pattern.compile(".*? ");
matcher=pattern.matcher(paper);
if(matcher.find()) {
time=matcher.group();
time=time.replaceAll(html_regex, "");
}
//match the publish time of paper
pattern=Pattern.compile(".*?");
matcher=pattern.matcher(paper);
if(matcher.find()) {
place=matcher.group();
place=place.replaceAll(html_regex, "");
}
//match the publish place of paper
pattern=Pattern.compile(".*? ");
matcher=pattern.matcher(paper);
if(matcher.find()) {
type=matcher.group();
type=type.replaceAll(html_regex, "");
type=type.replace(" ", "");
}
//match the type of paper
pattern=Pattern.compile(".*? ");
matcher=pattern.matcher(paper);
if(matcher.find()) {
tag=matcher.group();
tag=tag.replaceAll(html_regex, "");
}
//match the tag of paper
pattern=Pattern.compile(".*?
");
matcher=pattern.matcher(paper);
StringBuffer sb=new StringBuffer();
String l;
while(matcher.find()) {
l=matcher.group().replaceAll(" ", " ");
if(l==null)continue;
sb.append(l.replaceAll(html_regex, "")+"#");
}
content=sb.toString();
//match the content of the paper
FileInputStream fin=null;
FileOutputStream fout=null;
try {
fin=new FileInputStream(file);
HSSFWorkbook workbook=new HSSFWorkbook(fin);
fin.close();
HSSFSheet sheet=workbook.getSheetAt(0);
int ri=sheet.getLastRowNum()+1;
HSSFRow row=sheet.createRow(ri);
HSSFCell cell=null;
for(int i=0;i<7;i++) {
cell=row.createCell(i);
cell.setCellType(CellType.STRING);
}
String no=String.valueOf(ri);
row.getCell(0).setCellValue(no);
row.getCell(1).setCellValue(title);
row.getCell(2).setCellValue(time);
row.getCell(3).setCellValue(place);
row.getCell(4).setCellValue(type);
row.getCell(5).setCellValue(tag);
row.getCell(6).setCellValue(content);
fout=new FileOutputStream(file);
workbook.write(fout);
fout.flush();
fout.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(fin!=null) {
try {
fin.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(fout!=null) {
try {
fout.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
//write the document to a new row of the excel file
}