solidity高级编程——内联汇编
文档https://solidity-cn.readthedocs.io/zh/develop/assembly.html
Solidity定义了一个汇编语言,可以不同Solidity一起使用,也可以嵌入到Solidity源码中,以内联汇编的方式使用。
1 内联汇编(Inline Assembly)
内联汇编,一种接近于EVM底层的语言,允许与Solidity结合使用。由于EVM是栈式的,所以有时定位栈比较麻烦,Solidty的内联汇编为我们提供了下述的特性,来解决手写底层代码带来的各种问题:
- 允许函数风格的操作码:
mul(1, add(2, 3))等同于push1 3 push1 2 add push1 1 mul - 内联局部变量:
let x := add(2, 3) let y := mload(0x40) x := add(x, y) - 可访问外部变量:
function f(uint x) { assembly { x := sub(x, 1) } } - 标签:
let x := 10 repeat: x := sub(x, 1) jumpi(repeat, eq(x, 0)) - 循环:
for { let i := 0 } lt(i, x) { i := add(i, 1) } { y := mul(2, y) } - switch语句:
switch x case 0 { y := mul(x, 2) } default { y := 0 } - 函数调用:
function f(x) -> y { switch x case 0 { y := 1 } default { y := mul(x, f(sub(x, 1))) } }
2 示例合约字节编码
pragma solidity >=0.4.22 <0.6.0;
library GetCode {
function at(address _addr) public view returns (bytes o_code) {
assembly {
// 取得代码的大小,这需要汇编
let size := extcodesize(_addr)
// 分配输出字节数组
// 也可以不使用汇编完成——o_code = new bytes(size)
o_code := mload(0x40)
// new "memory end" including padding
mstore(0x40,add(o_code, and(add(add(size, 0x20), 0x1f), not(0x1f))))
// 存储长度在内存中
mstore(o_code, size)
// 实际取得代码,这需要汇编
extcodecopy(_addr, add(o_code, 0x20), 0, size)
}
}
}
contract A{
address public owner;
constructor() public{
owner = msg.sender;
}
}
contract B{
address public owner;
constructor() public{
owner = msg.sender;
}
function getSize(address _addr) public view returns (bytes){
return GetCode.at(_addr);
}
}
部署A\B后调用B.getSize()传入A的地址。
得到:
0x608060405260043610603f576000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff1680638da5cb5b146044575b600080fd5b348015604f57600080fd5b5060566098565b604051808273ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16815260200191505060405180910390f35b6000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff16815600a165627a7a7230582045e9440f7298080f79b54079f1f0648fdfc85261140f85661a906fcbcc122c2e0029
查看编辑器,对比bytecode
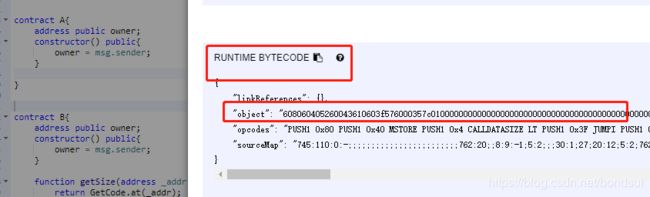
在优化器无法生成高效代码的情况下,内联汇编也可能更有好处。请注意,由于编译器无法对汇编语句进行相关的检查,所以编写汇编代码肯定更加困难; 因此只有在处理一些相对复杂的问题时才需要使用它,并且你需要明确知道自己要做什么。
3 示例内联汇编降低gas消费
所有部署合约,或者调用合约执行指令的操作,都以消耗gas为代价。内联汇编,类底层虚拟机语言,可节省部分gas消费。
例子:计算uint数组 之和
pragma solidity >=0.4.22 <0.6.0;
library VectorSum {
// 因为目前的优化器在访问数组时无法移除边界检查,
// 所以这个函数的执行效率比较低。
function sumSolidity(uint[] _data) public view returns (uint o_sum) {
for (uint i = 0; i < _data.length; ++i)
o_sum += _data[i];
}
// 我们知道我们只能在数组范围内访问数组元素,所以我们可以在内联汇编中不做边界检查。
// 由于 ABI 编码中数组数据的第一个字(32 字节)的位置保存的是数组长度,
// 所以我们在访问数组元素时需要加入 0x20 作为偏移量。
function sumAsm(uint[] _data) public view returns (uint o_sum) {
for (uint i = 0; i < _data.length; ++i) {
assembly {
o_sum := add(o_sum, mload(add(add(_data, 0x20), mul(i, 0x20))))
}
}
}
// 和上面一样,但在内联汇编内完成整个代码。
function sumPureAsm(uint[] _data) public view returns (uint o_sum) {
assembly {
// 取得数组长度(前 32 字节)
let len := mload(_data)
// 略过长度字段。
//
// 保持临时变量以便它可以在原地增加。
//
// 注意:对 _data 数值的增加将导致 _data 在这个汇编语句块之后不再可用。
// 因为无法再基于 _data 来解析后续的数组数据。
let data := add(_data, 0x20)
// 迭代到数组数据结束
for
{ let end := add(data, mul(len, 0x20)) }
lt(data, end)
{ data := add(data, 0x20) }
{
o_sum := add(o_sum, mload(data))
}
}
}
}
contract Demo2{
uint[] public numbers;
constructor() public {
for(uint i=0;i<10;i++){
numbers.push(i);
}
}
// solidity
function sum1() public view returns(uint){
return VectorSum.sumSolidity(numbers);
}
// solidity+ 汇编
function sum2() public view returns(uint){
return VectorSum.sumAsm(numbers);
}
// 存内联汇编
function sum3() public view returns(uint){
return VectorSum.sumPureAsm(numbers);
}
}
部署合约后分别执行3个函数
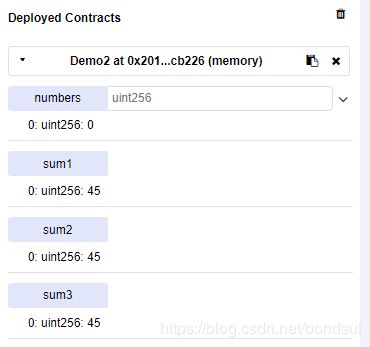
分别查看下交易信息:debug3个输出
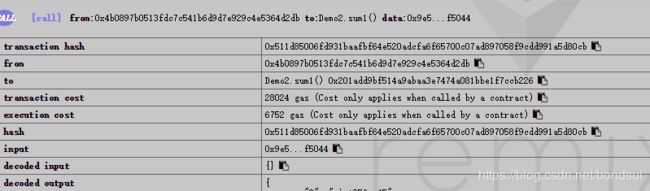
sum1:28024-6752=21272
transaction cost 28024 gas (Cost only applies when called by a contract)
execution cost 6752 gas (Cost only applies when called by a contract)
sum2: 27600-6328=21272
transaction cost 27600 gas (Cost only applies when called by a contract)
execution cost 6328 gas (Cost only applies when called by a contract)
sum3: 27414-6142=21272
transaction cost 27414 gas (Cost only applies when called by a contract)
execution cost 6142 gas (Cost only applies when called by a contract)
说明:
transaction cost指的是将交易送至ethereum blockchain所耗费的cost,是基于data size的大小,部署合约时就是基于合约內容的大小.
execution cost指的是虚拟机(VM)执行所需的cost,而在部署合约时,会去执行建構子以及一些初始化的工作
28024-6752=21272
var getGasUsedOutput = function (result, vmResult) {
var $gasUsed = $('');
var caveat = lookupOnly ? '(caveat)' : '';
if (result.gasUsed) {
var gas = result.gasUsed.toString(10);//Transaction cost
$gasUsed.html('Transaction cost: ' + gas + ' gas. ' + caveat);
}
if (vmResult.gasUsed) {
var $callGasUsed = $('');
var gas = vmResult.gasUsed.toString(10);//Execution cost
$callGasUsed.append('Execution cost: ' + gas + ' gas.');
$gasUsed.append($callGasUsed);
}
return $gasUsed;
};
部署合约:122780
transaction cost 545747 gas
execution cost 422967 gas
transaction cost 269488 gas
execution cost 174408 gas
4 内联汇编语法
和 Solidity 一样,Assembly 也会解析注释、文字和标识符,所以你可以使用通常的 // 和 /* */来进行注释。 内联汇编程序由 assembly { ... } 来标记,在这些大括号内可以使用以下内容(更多详细信息请参阅后面部分)。
- 字面常数,也就是
0x123、42 或 "abc" (不超过 32 个字符的字符串)
- 操作码(在“instruction style”内),比如
mload sload dup1 sstore,操作码列表请看后面
- 函数风格操作码,比如
add(1,mlod(0))
- 标签,比如
name:
- 变量声明,比如
let x := 7、let x := add(y, 3) 或者 let x (初始值将被置为 empty(0))
- 标识符(标签或者汇编局部变量以及用作内联汇编时的外部变量),比如
jump(name)、3 x add
- 赋值(在“instruction style”内),比如
3 =: x
- 函数风格赋值,比如
x := add(y,3)
- 一些控制局部变量作用域的语句块,比如
{let x := 3 { let y := add(x,1) }}
操作码
如果一个操作码需要参数(总是来自堆栈顶部)。请注意:参数顺序可以看作是在非函数风格中逆序
标有 - 的操作码不会向栈中压入(push)数据
标有 * 的操作码有特殊操作,而所有其他操作码都只会将一个数据压入(push)栈中。
在下表中,mem[a...b) 表示从位置 a 开始至(不包括)位置 b 的内存字节数,storage[p] 表示位置 p 处的存储内容。
用 F、H、B或 C 标记的操作码代表它们从 Frontier、Homestead、Byzantium 或 Constantinople 开始被引入。 Constantinople 目前仍在计划中,所以标记为 C 的指令目前都会导致一个非法指令异常。
Instruction
Explanation
stop
-
F
停止执行,与 return(0,0) 等价
add(x, y)
F
x + y
sub(x, y)
F
x - y
mul(x, y)
F
x * y
div(x, y)
F
x / y
sdiv(x, y)
F
x / y,以二进制补码作为符号
mod(x, y)
F
x % y
smod(x, y)
F
x % y,以二进制补码作为符号
exp(x, y)
F
x 的 y 次幂
not(x)
F
~x,对 x 按位取反
lt(x, y)
F
如果 x < y 为 1,否则为 0
gt(x, y)
F
如果 x > y 为 1,否则为 0
slt(x, y)
F
如果 x < y 为 1,否则为 0,以二进制补码作为符号
sgt(x, y)
F
如果 x > y 为 1,否则为 0,以二进制补码作为符号
eq(x, y)
F
如果 x == y 为 1,否则为 0
iszero(x)
F
如果 x == 0 为 1,否则为 0
and(x, y)
F
x 和 y 的按位与
or(x, y)
F
x 和 y 的按位或
xor(x, y)
F
x 和 y 的按位异或
byte(n, x)
F
x 的第 n 个字节,这个索引是从 0 开始的
shl(x, y)
C
将 y 逻辑左移 x 位
shr(x, y)
C
将 y 逻辑右移 x 位
sar(x, y)
C
将 y 算术右移 x 位
addmod(x, y, m)
F
任意精度的 (x + y) % m
mulmod(x, y, m)
F
任意精度的 (x * y) % m
signextend(i, x)
F
对 x 的最低位到第 (i * 8 + 7) 进行符号扩展
keccak256(p, n)
F
keccak(mem[p…(p + n)))
jump(label)
-
F
跳转到标签 / 代码位置
jumpi(label, cond)
-
F
如果条件为非零,跳转到标签
pc
F
当前代码位置
pop(x)
-
F
删除(弹出)栈顶的 x 个元素
dup1 … dup16
F
将栈内第 i 个元素(从栈顶算起)复制到栈顶
swap1 … swap16
*
F
将栈顶元素和其下第 i 个元素互换
mload§
F
mem[p…(p + 32))
mstore(p, v)
-
F
mem[p…(p + 32)) := v
mstore8(p, v)
-
F
mem[p] := v & 0xff (仅修改一个字节)
sload§
F
storage[p]
sstore(p, v)
-
F
storage[p] := v
msize
F
内存大小,即最大可访问内存索引
gas
F
执行可用的 gas
address
F
当前合约 / 执行上下文的地址
balance(a)
F
地址 a 的余额,以 wei 为单位
caller
F
调用发起者(不包括 delegatecall)
callvalue
F
随调用发送的 Wei 的数量
calldataload§
F
位置 p 的调用数据(32 字节)
calldatasize
F
调用数据的字节数大小
calldatacopy(t, f, s)
-
F
从调用数据的位置 f 的拷贝 s 个字节到内存的位置 t
codesize
F
当前合约 / 执行上下文地址的代码大小
codecopy(t, f, s)
-
F
从代码的位置 f 开始拷贝 s 个字节到内存的位置 t
extcodesize(a)
F
地址 a 的代码大小
extcodecopy(a, t, f, s)
-
F
和 codecopy(t, f, s) 类似,但从地址 a 获取代码
returndatasize
B
最后一个 returndata 的大小
returndatacopy(t, f, s)
-
B
从 returndata 的位置 f 拷贝 s 个字节到内存的位置 t
create(v, p, s)
F
用 mem[p…(p + s)) 中的代码创建一个新合约、发送 v wei 并返回 新地址
create2(v, n, p, s)
C
用 mem[p…(p + s)) 中的代码,在地址 keccak256( . n . keccak256(mem[p…(p + s))) 上 创建新合约、发送 v wei 并返回新地址
call(g, a, v, in, insize, out, outsize)
F
使用 mem[in…(in + insize)) 作为输入数据, 提供 g gas 和 v wei 对地址 a 发起消息调用, 输出结果数据保存在 mem[out…(out + outsize)), 发生错误(比如 gas 不足)时返回 0,正确结束返回 1
callcode(g, a, v, in, insize, out, outsize)
F
与 call 等价,但仅使用地址 a 中的代码 且保持当前合约的执行上下文
delegatecall(g, a, in, insize, out, outsize)
F
与 callcode 等价且保留 caller 和 callvalue
staticcall(g, a, in, insize, out, outsize)
F
与 call(g, a, 0, in, insize, out, outsize) 等价 但不允许状态修改
return(p, s)
-
F
终止运行,返回 mem[p…(p + s)) 的数据
revert(p, s)
-
B
终止运行,撤销状态变化,返回 mem[p…(p + s)) 的数据
selfdestruct(a)
-
F
终止运行,销毁当前合约并且把资金发送到地址 a
invalid
-
F
以无效指令终止运行
log0(p, s)
-
F
以 mem[p…(p + s)) 的数据产生不带 topic 的日志
log1(p, s, t1)
-
F
以 mem[p…(p + s)) 的数据和 topic t1 产生日志
log2(p, s, t1, t2)
-
F
以 mem[p…(p + s)) 的数据和 topic t1、t2 产生日志
log3(p, s, t1, t2, t3)
-
F
以 mem[p…(p + s)) 的数据和 topic t1、t2、t3 产生日志
log4(p, s, t1, t2, t3, t4)
-
F
以 mem[p…(p + s)) 的数据和 topic t1、t2、t3 和 t4 产生日志
origin
F
交易发起者地址
gasprice
F
交易所指定的 gas 价格
blockhash(b)
F
区块号 b 的哈希 - 目前仅适用于不包括当前区块的最后 256 个区块
coinbase
F
当前的挖矿收益者地址
timestamp
F
从当前 epoch 开始的当前区块时间戳(以秒为单位)
number
F
当前区块号
difficulty
F
当前区块难度
gaslimit
F
当前区块的 gas 上限
字面常量
你可以直接键入十进制或十六进制符号来作为整型常量使用,这会自动生成相应的 PUSHi 指令。 下面的代码将计算 2 加 3(等于 5),然后计算其与字符串 “abc” 的按位与。字符串在存储时为左对齐,且长度不能超过 32 字节。
assembly { 2 3 add "abc" and }
函数风格
你可以像使用字节码那样在操作码之后键入操作码。例如,把 3 与内存位置 0x80 处的数据相加就是
mstore(0x80, add(mload(0x80), 3))
等价于
3 0x80 mload add 0x80 mstore
访问外部变量和函数
通过简单使用它们名称就可以访问 Solidity 变量和其他标识符。
对于内存变量,这会将地址而不是值压入栈中。 存储变量是不同的,因为存储变量的值可能不占用完整的存储槽,因此其“地址”由存储槽和槽内的字节偏移量组成。 为了获取变量 x 所使用的存储槽,你可以使用 x_slot,并用的 x_offset 获取其字节偏移量。
这个特性使用起来还是有点麻烦,因为在调用过程中堆栈偏移量发生了根本变化,因此对局部变量的引用将会出错。
pragma solidity ^0.4.11;
contract C {
uint b;
function f(uint x) public returns (uint r) {
assembly {
r := mul(x, sload(b_slot)) // 因为偏移量为 0,所以可以忽略
}
}
}
注解:
如果你访问一个实际数据位数小于 256 位的数据类型(比如 uint64、address、bytes16 或 byte), 不要对这种类型经过编码后未使用的数据位上的数值做任何假设。尤其是不要假设它们肯定为 0。 安全起见,在某个上下文中使用这种数据之前,请一定先将其数据清空为 0,这非常重要:uint32 x = f(); assembly { x := and(x, 0xffffffff) /* now use x */ } 要清空有符号类型,你可以使用 signextend 操作码。
汇编局部变量声明
let 指令将创建一个为变量保留的新数据槽,并在到达块末尾时自动删除。 你需要为变量提供一个初始值,它可以只是 0,也可以是一个复杂的函数表达式。
contract C {
function f(uint x) public view returns (uint b) {
assembly {
let v := add(x, 1)
mstore(0x80, v)
{
let y := add(sload(v), 1)
b := y
} // y 会在这里被“清除”
// b := add(y, v) // 编译错误
b := add(b, v)
} // v 会在这里被“清除”
}
}
赋值
{
let v := 0 // 作为变量声明的函数风格赋值
let g := add(v, 2)
}
控制结构
if:没有“else”部分;如果需要多种选择,你可以考虑使用“switch”
function testif(uint x) public pure returns (uint b) {
b=x+1;
assembly {
if eq(x, 0) {
b := 99
}
}
}
switch:Case 列表里面不需要大括号,但 case 主体需要。
contract Demo4{
uint public a=1;
uint public b=11;
uint public c=22;
uint public d=33;
function testswitch(uint x) public view returns(uint r){
assembly{
x := add(x,sload(0)) // 输入参数加第0个storage的值
switch mod(x,3)
case 1 {
r := sload(1)
}
case 2 {
r := sload(2)
}
default {
r := sload(3)
}
}
}
}
for
// 和上面一样,但在内联汇编内完成整个代码。
function sumPureAsm(uint[] _data) public view returns (uint o_sum) {
assembly {
let len := mload(_data)
let data := add(_data, 0x20)
for { let end := add(data, mul(len, 0x20)) }
lt(data, end)
{ data := add(data, 0x20) }
{
o_sum := add(o_sum, mload(data))
}
}
}
函数
函数可以在任何地方定义,并且在声明它们的语句块中可见。函数内部不能访问在函数之外定义的局部变量。这里没有严格的 return 语句。
如果调用会返回多个值的函数,则必须使用 a,b:= f(x) 或 let a,b:= f(x) 的方式把它们赋值到一个元组。
将输入的值都加1后返回
function testfunc(uint a1,uint a2) public pure returns (uint r1,uint r2) {
assembly {
r1,r2 := addOne(a1,a2)
function addOne(a, b) -> aa,bb {
aa := add(a,1)
bb := add(b,1)
}
}
}
//幂运算函数。
{
function power(base, exponent) -> result {
switch exponent
case 0 { result := 1 }
case 1 { result := base }
default {
result := power(mul(base, base), div(exponent, 2))
switch mod(exponent, 2)
case 1 { result := mul(base, result) }
}
}
}
5 内联汇编注意
与 EVM 汇编语言相比,Solidity 能够识别小于 256 位的类型,例如 uint24。为了提高效率,大多数算术运算只将它们视为 256 位数字, 仅在必要时才清除未使用的数据位,即在将它们写入内存或执行比较之前才会这么做。这意味着,如果从内联汇编中访问这样的变量,你必须先手工清除那些未使用的数据位。
Solidity 以一种非常简单的方式管理内存:在 0x40 的位置有一个“空闲内存指针”。如果你打算分配内存,只需从此处开始使用内存,然后相应地更新指针即可。
内存的开头 64 字节可以用来作为临时分配的“暂存空间”。“空闲内存指针”之后的 32 字节位置(即从 0x60 开始的位置)将永远为 0,可以用来初始化空的动态内存数组。
在 Solidity 中,内存数组的元素总是占用 32 个字节的倍数(是的,甚至对于 byte[] 都是这样,只有 bytes 和 string 不是这样)。 多维内存数组就是指向内存数组的指针。动态数组的长度存储在数组的第一个槽中,其后才是数组元素。
静态内存数组没有长度字段,但很快就会增加,这是为了可以更好地进行静态数组和动态数组之间的转换,所以请不要依赖这点。