parser目录下包含如下几个文件,核心文件在于path.js。
-
directive.js:
parseDirective -
expression.js:
parseExpression -
path.js:
getPath, setPath, parsePath -
template.js:
parseTemplate, cloneNode, parseTemplate text.js:
parseText,
tokensToExp,
compileRegex
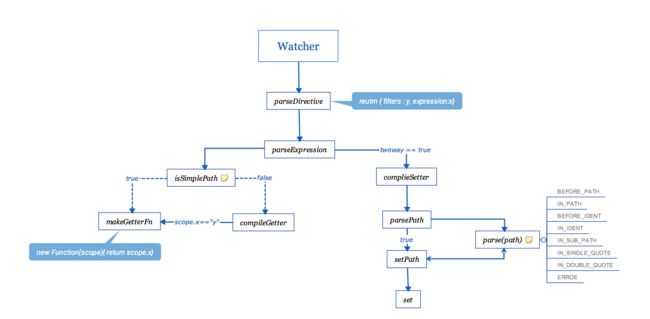
parser工作流程图
函数解读:
- parseDirective: 判断表达式中是否存在过滤器,如果存在提取出来
- parseExpression: 负责将表达式添加getter 和 setter方法
- makeGetterFn:将简单字符串表达式添加scope作用域并转化为function返回
- compileGetter:将复杂字符串表达式进行正则替换并在变量后添加scope作用域
例: status == "todo" 返回 scope.status == "todo" - compileSetter:将parse函数生成数组遍历并将最后一个属性作为最后的key
[path.js] 通过parse函数对 a.b.c 进行逐个字节扫描,最终获得['a','b','c',raw:'a.b.c']数组
// actions
var APPEND = 0 // 拼接字符在keystr后
var PUSH = 1 // 将keystr添加到keys数组中
var INC_SUB_PATH_DEPTH = 2 // 拼接当前字符在keystr后,并且深度+1
var PUSH_SUB_PATH = 3 // 如果深度大于0将状态置回IN_SUB_PATH,相反将keystr添加到keys数组
// states
var BEFORE_PATH = 0 // 初始状态
var IN_PATH = 1 // 遇到空格 和 ]
var BEFORE_IDENT = 2 // 遇到' . ' 或 空格时
var IN_IDENT = 3 // 遇到字符串数字时
var IN_SUB_PATH = 4 // 遇到 ' 或 " 或 [ 时
var IN_SINGLE_QUOTE = 5 // 遇到 '
var IN_DOUBLE_QUOTE = 6 // 遇到 "
var AFTER_PATH = 7 // 结束状态
var ERROR = 8 // 报错
var pathStateMachine = [] // 状态 + 动作 管理仓库
pathStateMachine[BEFORE_PATH] = {
'ws': [BEFORE_PATH],
'ident': [IN_IDENT, APPEND],
'[': [IN_SUB_PATH],
'eof': [AFTER_PATH]
}
pathStateMachine[IN_PATH] = {
'ws': [IN_PATH],
'.': [BEFORE_IDENT],
'[': [IN_SUB_PATH],
'eof': [AFTER_PATH]
}
pathStateMachine[BEFORE_IDENT] = {
'ws': [BEFORE_IDENT],
'ident': [IN_IDENT, APPEND]
}
pathStateMachine[IN_IDENT] = {
'ident': [IN_IDENT, APPEND],
'0': [IN_IDENT, APPEND],
'number': [IN_IDENT, APPEND],
'ws': [IN_PATH, PUSH],
'.': [BEFORE_IDENT, PUSH],
'[': [IN_SUB_PATH, PUSH],
'eof': [AFTER_PATH, PUSH]
}
pathStateMachine[IN_SUB_PATH] = {
"'": [IN_SINGLE_QUOTE, APPEND],
'"': [IN_DOUBLE_QUOTE, APPEND],
'[': [IN_SUB_PATH, INC_SUB_PATH_DEPTH],
']': [IN_PATH, PUSH_SUB_PATH],
'eof': ERROR,
'else': [IN_SUB_PATH, APPEND]
}
pathStateMachine[IN_SINGLE_QUOTE] = {
"'": [IN_SUB_PATH, APPEND],
'eof': ERROR,
'else': [IN_SINGLE_QUOTE, APPEND]
}
pathStateMachine[IN_DOUBLE_QUOTE] = {
'"': [IN_SUB_PATH, APPEND],
'eof': ERROR,
'else': [IN_DOUBLE_QUOTE, APPEND]
}
/*
开始状态下当遇到对应字符会将状态变化成对应状态并执行对应动作
我们以 a["b"].c 为线索进入parse函数并进行逐个字节扫描
index=0时:
char='a' mode=BEFORE_PATH pathStateMachine[BEFORE_PATH]['ident']=[IN_IDENT, APPEND] newchar="a",keys=[]
index=1时 :
char='[' mode=IN_IDENT pathStateMachine[IN_IDENT]['[']=[IN_SUB_PATH, PUSH] newchar=undefined,keys=['a']
index=2时 :
char='"' mode=IN_SUB_PATH pathStateMachine[IN_SUB_PATH]['"']=[IN_DOUBLE_QUOTE,APPEND] newchar='"',keys=['a']
index=3时 :
char='b' mode=IN_DOUBLE_QUOTE pathStateMachine[IN_DOUBLE_QUOTE]['ident']= pathStateMachine[IN_DOUBLE_QUOTE]['else'] = [IN_DOUBLE_QUOTE,APPEND] newchar='"b',keys=['a']
index=4时 :
char='"' mode=IN_DOUBLE_QUOTE pathStateMachine[IN_DOUBLE_QUOTE]['"']=[IN_SUB_PATH,APPEND] newchar='"b"',keys=['a']
index=5时 :
char="]" mode=IN_SUB_PATH pathStateMachine[IN_SUB_PATH][']']=[IN_PATH,PUSH_SUB_PATH] newchar=undefined,keys=['a','b']
index=6时 :
char="." mode=IN_PATH pathStateMachine[IN_PATH]['.']=[BEFORE_IDENT] newchar=undefined,keys=['a','b']
index=7时 :
char="c" mode=BEFORE_IDENT pathStateMachine[BEFORE_IDENT]['indent']=[IN_IDENT,APPEND] newchar='c',keys=['a','b']
index=8时 :
char=undefined mode=IN_IDENT pathStateMachine[IN_IDENT]['eof']=[AFTER_PATH,PUSH] newchar=undefined,keys=['a','b','c']
最终循环完成当状态变为AFTER_PATH时,keys = ['a','b','c',raw:'a["b"].c']
*/
function parse (path) {
var keys = []
var index = -1
var mode = BEFORE_PATH
var subPathDepth = 0
var c, newChar, key, type, transition, action, typeMap
var actions = []
actions[PUSH] = function () {
if (key !== undefined) {
keys.push(key)
key = undefined
}
}
actions[APPEND] = function () {
if (key === undefined) {
key = newChar
} else {
key += newChar
}
}
actions[INC_SUB_PATH_DEPTH] = function () {
actions[APPEND]()
subPathDepth++
}
actions[PUSH_SUB_PATH] = function () {
if (subPathDepth > 0) {
subPathDepth--
mode = IN_SUB_PATH
actions[APPEND]()
} else {
subPathDepth = 0
key = formatSubPath(key)
if (key === false) {
return false
} else {
actions[PUSH]()
}
}
}
function maybeUnescapeQuote () {
var nextChar = path[index + 1]
if ((mode === IN_SINGLE_QUOTE && nextChar === "'") ||
(mode === IN_DOUBLE_QUOTE && nextChar === '"')) {
index++
newChar = '\\' + nextChar
actions[APPEND]()
return true
}
}
while (mode != null) {
index++
c = path[index]
if (c === '\\' && maybeUnescapeQuote()) {
continue
}
type = getPathCharType(c)
typeMap = pathStateMachine[mode]
transition = typeMap[type] || typeMap['else'] || ERROR
if (transition === ERROR) {
return // parse error
}
mode = transition[0]
action = actions[transition[1]]
if (action) {
newChar = transition[2]
newChar = newChar === undefined
? c
: newChar
if (action() === false) {
return
}
}
if (mode === AFTER_PATH) {
keys.raw = path
return keys
}
}
}