基于 kears的全卷积网络u-net端到端医学图像多类型图像分割(二)
文章目录
- 1. 端到端的图像分割网络
- 2. 数据准备
- 3. 训练
- 4. 结果
- 5.多分类
- 6.其它相关
1. 端到端的图像分割网络
首先,回顾下网络模型
def get_unet(pretrained_weights=None):
inputs = Input((img_rows, img_cols, 1))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(inputs)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)
up6 = concatenate([Conv2DTranspose(256, (2, 2), strides=(2, 2), padding='same')(conv5), conv4], axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
up7 = concatenate([Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv6), conv3], axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
up8 = concatenate([Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv7), conv2], axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
up9 = concatenate([Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(conv8), conv1], axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv10 = Conv2D(1, (1, 1), activation='sigmoid')(conv9)
model = Model(inputs=[inputs], outputs=[conv10])
model.compile(optimizer=Adam(lr=1e-5), loss=dice_coef_loss, metrics=[dice_coef])
if (pretrained_weights):
model.load_weights(pretrained_weights)
return model
- 比较重要的是定义loss function 我们使用dice loss,主要思路就是求图像重合部分占比。相关代码如下:
def dice_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
def dice_coef_loss(y_true, y_pred):
return -dice_coef(y_true, y_pred)
2. 数据准备
由于是端到端的训练,我们的数据其实并没有经过太多处理,将mask和原图分别放到np array中即可。以下代码段展示training data的准备方式,test data 基本类似。
data_path = 'data/' #设置路径
image_rows = 256
image_cols = 256
def create_train_data():
train_data_path = os.path.join(data_path, 'train/Image') #训练文件路径
train_data_Label_path = os.path.join(data_path, 'train/Label') #mask文件路径
images = os.listdir(train_data_path)
total = len(images)
imgs = np.ndarray((total, image_rows, image_cols), dtype=np.uint8)
imgs_mask = np.ndarray((total, image_rows, image_cols), dtype=np.uint8)
i = 0
print('Creating training images...')
for image_name in images:
img = imread(os.path.join(train_data_path, image_name), as_grey=True)
img_mask = imread(os.path.join(train_data_Label_path, image_name), as_grey=True)
img = np.array([img])
img_mask = np.array([img_mask])
imgs[i] = img
imgs_mask[i] = img_mask
if i % 100 == 0:
print('Done: {0}/{1} images'.format(i, total))
i += 1
print('Loading done.')
np.save('imgs_train.npy', imgs)
np.save('imgs_mask_train.npy', imgs_mask)
print('Saving to .npy files done.')
3. 训练
训练前,要先对相关数据归一化,对于训练数据,我们先求均值,与标准差,原始值与均值做差,再除以均值。
imgs_train = imgs_train.astype('float32')
mean = np.mean(imgs_train) # mean for data centering
std = np.std(imgs_train) # std for data normalization
imgs_train -= mean
imgs_train /= std
对于mask数据,直接除以通道最大值255即可。
imgs_mask_train = imgs_mask_train.astype('float32')
imgs_mask_train /= 255. # scale masks to [0, 1]
设置相关参数,开始训练:
model.fit(imgs_train, imgs_mask_train, batch_size=16, nb_epoch=20, verbose=1, shuffle=True,
validation_split=0.2,
callbacks=[model_checkpoint])
4. 结果
经过大约200 epoch 的训练,我们的结果如下图(从左至右依次为原始图,手工标注图,算法分割图):
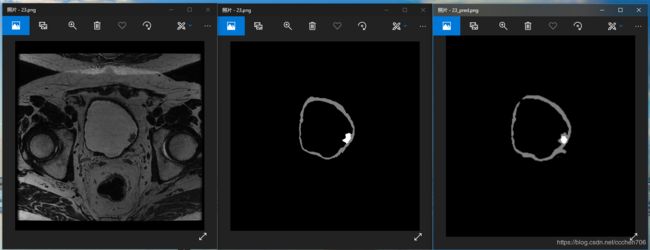
最终的dice_coef 在0.7左右。
5.多分类
可以看到最终的结果是3分类的,但训练过程中发现,网络结果仍旧是二分类,因此,我们仍旧需要针对不同分类训练多个二分类模型,在预测时,先做多个二分类,再对数据进行相关融合,得到最终结果。相关预测及合并代码如下:
imgs_mask_test = model.predict(imgs_test, verbose=1)
imgs_mask_test_t = modelt.predict(imgs_test, verbose=1)
pred_dir = 'preds_a'
if not os.path.exists(pred_dir):
os.mkdir(pred_dir)
for image,image_t,image_id in zip(imgs_mask_test,imgs_mask_test_t ,imgs_id_test):
image = (image[:, :, 0] * 128.).astype(np.uint8)
image_t = (image_t[:, :, 0] * 255.).astype(np.uint8)
image[image_t>200]=255
imsave(os.path.join(pred_dir, str(image_id) + '_pred.png'), image)
6.其它相关
二分类源代码及已上传至github keras-u-net 多分类,由于大家数据不同,分类类别不同,暂时没有更新相关代码。欢迎交流。
- 注:由于相关训练数据不便提供,所以相关数据文件没有上传。