协程的原理与实现:qemu 之 Coroutine
一,概念
在操作系统(os)级别,有进程(process)和线程(thread)两个我们看不到但又实际存在的“东西”,这两个东西都是用来模拟“并行”的,并且在OS内做为调度的实体单元,各自拥有独立的CPU资源。
Coroutine: 翻译成”协程“, 但它实际上并不是一个可由OS调度的实体,而是可以理解为“由用户层自己调度执行的一段代码片段”。
二,进程,线程,协程
Process: 进程。
进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
Thread : 线程
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是这样的)。
Coroutine: 协程
协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。
三,qemu 中协程的实现
3.1 setjmp, longjmp

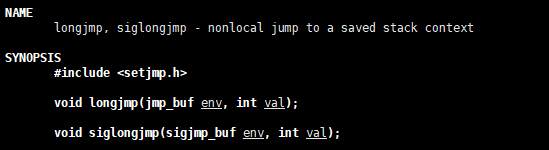
#include
int setjmp(jmp_buf env);
将当前上下文保存在 env中,并直接返回0, 在调用longjmp返回时,会返回 val值。 (可以理解为保存并定义一个 label)
void longjmp(jmp_buf env, int val);
恢复先前通过setjmp保存的 env 上下文,即恢复setjmp执行,并用 val作为 setjmp的返回值。(可以理解为 goto 到指定的 label )
注:sigsetjmp, siglongjmp与上面类似,只是env中会用savesigs保存信号相关的标记。
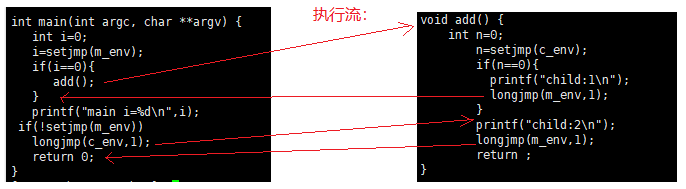
代码示例:
#include
#include
jmp_buf m_env,c_env;
void add() {
int n=0;
n=setjmp(c_env); // 定义一个label2
if(n==0){ // 直接返回0,goto返回 1
printf("child:1\n");
longjmp(m_env,1); // goto 到 label1
}
printf("child:2\n");
longjmp(m_env,1); // goto 到新的 label1
return ;
}
int main(int argc, char **argv) {
int i=0;
i=setjmp(m_env); // 定义一个label1
if(i==0){ // 直接返回0 , goto返回为1
add();
}
printf("main i=%d\n",i);
if(!setjmp(m_env)) // 重新定义 label1
longjmp(c_env,1); // goto label2
return 0;
}
执行流程如图:
3.2 getcontext, setcontext,makecontext,swapcontext
#include
int getcontext(ucontext_t *ucp);
// 获取当前上下文,保存在ucp中。
int setcontext(const ucontext_t *ucp);
// 用ucp来重新设置当前的上下文,调用成功不会返回,因为EIP已指向新的上下文。
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
说明:
1,修改 ucp所对应的上下文,这个ucp是之前getcontext获取的
2,在调用makecontext前,调用者必需先分配一个堆栈存入ucp->uc_stack, 并且要定义一个继承者存入ucp->uc_link;
3, 当这个ucp对应的上下文被激活时,会调用 func入口函数. (激活可以由swapcontext 或 setcontext)
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
//保存当前上下文到 oucp, 并激活 ucp所对应的上下文
typedef struct ucontext {
struct ucontext *uc_link; // 当前上下文结束时,返回调用者的上下文
sigset_t uc_sigmask;
stack_t uc_stack; // 栈
mcontext_t uc_mcontext;
...
} ucontext_t;
代码示例:
#include
#define _XOPEN_SOURCE
#include
#undef _XOPEN_SOURCE
int fib_res;
ucontext_t main_ctx, fib_ctx;
char fib_stack[1024 * 32];
void fib() {
int a0 = 0;
int a1 = 1;
while (1) {
fib_res = a0 + a1;
a0 = a1;
a1 = fib_res;
printf("fib : fib_res=%d\n",fib_res);
swapcontext(&fib_ctx, &main_ctx);
}
}
int main(int argc, char **argv) {
getcontext(&fib_ctx);
getcontext(&main_ctx);
fib_ctx.uc_link = &main_ctx;
fib_ctx.uc_stack.ss_sp = fib_stack;
fib_ctx.uc_stack.ss_size = sizeof(fib_stack);
fib_ctx.uc_stack.ss_flags = 0;
makecontext(&fib_ctx, fib, 0);
while (1) {
swapcontext(&main_ctx, &fib_ctx);
printf("main:%d\n", fib_res);
if (fib_res > 100) {
break;
}
}
return 0;
}
代码执行流程示意图:

3.3 qemu中 Coroutine实现
qemu中协程引入: https://github.com/qemu/qemu.git
commit: 00dccaf1f84
说明:
异步代码变得非常复杂。同时,同步代码正在增长,因为它便于编写。
有时甚至会添加重复的代码路径,一个是同步的,另一个是异步的。
这个补丁引入了协同程序,它允许代码看起来是同步的,但在封装下是异步的。
协程具有自己的堆栈,因此能够跨阻塞操作保留状态,阻塞操作传统上需要回调函数和手动准备参数。
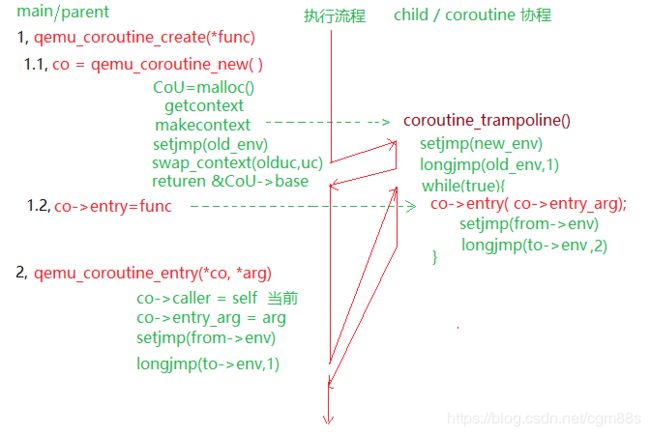
创建并开始一个coroutine协程:
coroutine = qemu_coroutine_create(my_coroutine);
qemu_coroutine_enter(coroutine, my_data);
协程开始执行,直到返回,或 yield :
void coroutine_fn my_coroutine(void *opaque) {
MyData *my_data = opaque;
/* do some work */
qemu_coroutine_yield();
/* do some more work */
}
Yielding 会(把控制权)返回给 qemu_coroutine_enter() 的调用者。
这通常用于在发出异步I/O请求后切换回主线程的事件循环。
然后,请求的回调函数将再次调用 qemu_coroutine_enter() 以切换回 coroutine 协程。
请注意,如果仅从包含全局互斥锁的线程使用协同程序,则它们将永远不会同时执行。
这使得使用协程编程比使用线程更容易。
由于在任何时候只有一个协程可能处于活动状态,因此不会发生竞争条件。其他协同程序只能交叉yield。
这个协程的实现是基于Anthony Liguori [email protected] 编写的 gtk-vnc中的实现。
由 Kevin Wolf [email protected] 使用 setjmp()/longjmp() 来替代更昂贵的 swapcontext()。
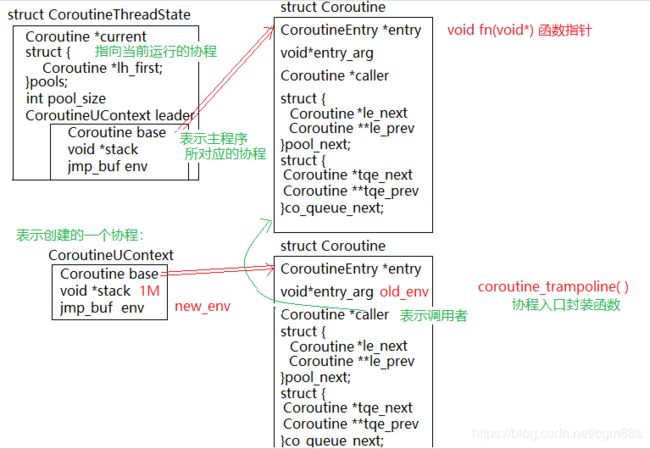
数据结构图:
执行流程原理图: