【计算机系统】 PerfLab优化理论到实践
PerfLab 优化方法目录
常数除法的自动优化
减少函数的调用
函数优化思路:
3.1 查表
3.2 求余
3.3 平方
3.4 用移位实现乘除法运算
3.5 避免不必要的整数乘法
3.6 使用增量和减量操作符
3.7 使用复合赋值表达式
3.8 公共表达式的提取
3.9 调整数据类型对齐方式
3.10 本地变量排列优化
3.11 指针变量局部化
3.12 不定义不使用的返回值
3.13 减少函数参数调用
3.14 为所有函数添加原型定义
3.15 最大限度使用const类型
3.16 将本地函数强制声明为static
循环优化
4.1 分解小循环
4.2 init化通用代码
4.3 循环转置
4.4 优化(do) while循环
4.5 循环展开
4.6 循环归一
4.7 循环顺序
4.7.1 多层嵌套的循环应该能够使内部的平均计算量最小(下标访问计算等)
4.7.2 不随循环变化的条件判断应该放在循环外部,宁可多写几遍相同的for循环
4.8 死循环优选
switch 优化
5.1 可能性分析
5.2 嵌套switch 语句
5.3 使用函数指针表
并行优化
6.1 削弱代码依赖性
6.2 避免读写依赖
采用递归
变量优化
分支优化
-
常数除法的自动优化
编译器会自动优化常见的常数除法,并将除法转化为乘法和移位操作,将多个时钟周期压缩到数个时钟周期(乘法需要的周期数远小于除法,加减法的时钟周期数又会小于乘法)。
如果有num / size而size的值是已知的,那么此时用常数替换size会大大提高运算速度,因为此时编译器会自动对这种除法进行优化为乘法和移位的运算。
-
减少函数的调用
函数的调用会占用大量的时间,所以将函数内联化或者是直接将函数的代码写到另一个函数中是减少函数调用时间的很好的方法。
特别值得注意的是,函数的内联有时候并不是能够任意实现的,例如在遇到switch和for的时候就不能够将函数进行内联。
-
函数优化思路:
3.1 查表
将常用的数据预先计算出来,然后再之后的运算中直接调用
3.2 求余
位操作只需一个指令周期即可完成,而大部分的C编译器的“%”运算均是调用子程序来完成,代码长、执行速度慢。通常,只要求是求2n方的余数,均可使用位操作的方法来代替。
3.3 平方
乘法运算比求平方运算快得多,因为浮点数的求平方是通过调用子程序来实现的,乘法运算的子程序比平方运算的子程序代码短,执行速度快。
所以优化时使用自己乘自己的方法代替平方运算。
3.4 用移位实现乘除法运算
对于偶数,进行移位运算进行除法运算只需要通过简单的右移操作就可以实现,如果是较为复杂的乘法预算也可以化为移位运算和加减法运算的符合运算。
例如:
- int A = a*9;
- int A = (a<<3)+a;
3.5 避免不必要的整数乘法
由于整数的乘法的开销小于整数的除法,通常可以将多次连续的除法转换为一次除法和多次乘法,例如:
优化之前代码:
m = i / j / k;
优化之后代码:
m = i / (j * k);
3.6 使用增量和减量操作符
x=x+1 (自增一和自减一)这样的语句会再汇编代码中被翻译为:
- mov addr[M, a, b], ebx
- add 1, ebx
- mov ebx, addr[M, a, b]
但用增量和减量操作符如++, --
将代码优化为
- x -= 1;
则得到对应的汇编代码:
- incr x
这样一下就减少了2/3 的时钟周期消耗
3.7 使用复合赋值表达式
复合表达式的优化是编译器自动完成的,对于:
- a = a + b
和
- a = a - b
类型的代码,可以优化表示为
- a -= b
和
- a += b
编译器会对这类复合操作符号进行生成的汇编代码层级的优化
3.8 公共表达式的提取
C++的编译器不会对含有浮点数的表达式子自动推出公共的子表达式,
此时编译器再公共表达式的提取过程中不能按照代数的等价关系重新
安排表达式,所以就需要程序员自己提取公共的表达式。
例如:
- float x, y, z, l, m;
- float tmp1 = x / y * z;
- float tmp2 = x / m * y;
对于上面三行优化前的代码,进行了重复的浮点数运算,但是编译器并
不会自动检测和优化这个除法运算中的公因式,这时就需要我们手动优
化,手动提取出公因子并手动复用:
- float x, y, z, l, m;
- const float temp = x / y;
- float tmp1 = temp * z;
- float tmp2 = temp / m;
这样优化过的代码就会节省至少10个时钟周期,总的时钟周期至少减半,
也就是代码运行速度至少加倍。
3.9 调整数据类型对齐方式
在声明结构体变量的时候,要考虑结构体变量的内部的数据对其方式,将多字节的数据放在前面,将较短的数据放在后面,编译器会自动将结构体实例对齐,通常,编译器会自动地将这类结构实例对齐在内存地偶数边界,这样可以最大程度地避免由于编译器遵循4,8等字节对齐标准导致的大量内存空洞问题。
为了确保数据的对齐,可以利用编译器自动对齐结构体首元素的特性,如果已经按照上面的对齐规则将对应的数据按照由长数据类型到短数据类型依次填充,那么再加上倍数对齐准则就可以实现所有数据类型的自动对齐:即再对齐的时候按照最长数据类型(放在第一个)的整数倍填充其他的数据类型,最终达到整个结构体的有效长度为最长类型长度的整数倍的效果。
优化前:
- struct {
- char a[5];
- long k;
- double x;
- } naive_block;
优化后:(进行数据类型大小重排,并进行结构体的字节填充)
- struct {
- double x;
- long k;
- char a[5];
- char gapFiller[7];
- } advanced_block;
上面两条优化优化原则也适用于类的成员排列的优化。
3.10 本地变量排列优化
编译器进行本地变量的空间分配的时候,顺序和在源代码中的声名顺序相同。这一点在学习CSAPP的过程中是没有提及的,但是CSAPP的期末考试却是考到了这一点。优化的时候,也是将长的变量类型优先放在前面,并利用编译器分配第一个变量时进行自动对齐的特性保证之后的变量全部都能保持对齐。
3.11 指针变量局部化
在CSAPP中已经强调,由于函数内部有指针操作不能被编译器直接优化,否则可能会有冲突结果,所以编译器对于指针类型访问的数据变量不会自动地进行优化,所以在函数传入指针数据地时候,为了充分利用编译器地优化能力,通常将指针指向地数据进行局部变量“固定”,即数据进入函数首先转移到函数内部地局部变量,在函数将参数传回的时候再将数据通过赋值给指针来实现操作传回。
优化前:
- void isqrt(unsigned long a, unsigned long* q, unsigned long* r)
- {
- *q = a;
- if (a > 0)
- {
- while (*q > (*r= a / *q))
- {
- *q = (*q + *r)>> 1;
- }
- }
- *r = a - *q * *q;
- }
优化后:
- void isqrt(unsigned long a, unsigned long* q, unsigned long* r)
- {
- unsigned long qq, rr;
- qq = a;
- if (a > 0)
- {
- while (qq > (rr= a / qq))
- {
- qq = (qq + rr)>> 1;
- }
- }
- rr = a - qq * qq;
- *q = qq;
- *r = rr;
- }
3.12 不定义不使用的返回值
对于一个不需要返回值的参数,就设置返回类型为void。
3.13 减少函数参数调用
学习过CSAPP就知道函数调用和传参是需要将参数压栈到下一个调用函数体之前的,参数越多,需要的准备参数的时间就越多,同时栈收回的时候,指针需要移动的距离也越长。可以通过使用全局变量来进行部分优化。
3.14 为所有函数添加原型定义
函数的原型可以为编译器的优化提供足够的优化信息。
3.15 最大限度使用const类型
对于C++标准,const类型的对象由于本身的对象地址不能够被获取,所以编译器不会对这个变量进行内存的分配,这样就减少了内存分配、访问、回收的全部时间。
3.16 将本地函数强制声明为static
声明成static不仅可以保证数据安全,防止多文件编译冲突,同时会激活编译器的强制使用内部连接机制,如果不使用static,则编译器并不会自动使用内部连接。
-
循环优化
4.1 分解小循环
优化前:
- for (i = 0; i < 4; i ++)
- {
- r[i] = 0;
- for (j = 0; j < 4; j ++)
- {
- r[i] += M[j][i]*V[j];
- }
- }
优化后:
- r[0] =M[0][0]*V[0] + M[1][0]*V[1] + M[2][0]*V[2] + M[3][0]*V[3];
- r[1] =M[0][1]*V[0] + M[1][1]*V[1] + M[2][1]*V[2] + M[3][1]*V[3];
- r[2] =M[0][2]*V[0] + M[1][2]*V[1] + M[2][2]*V[2] + M[3][2]*V[3];
- r[3] =M[0][3]*V[0] + M[1][3]*V[1] + M[2][3]*V[2] + M[3][3]*v[3];
将较小的循环直接全部展开写,可以有效提高运行速度。
4.2 init化通用代码
编程老手通常都有一个编写init() 函数的习惯,即通过一次初始化将需要的环境配置好,
对于不需要放在循环中的代码,应全部挪出来,否则跳转寻址将会消耗很多无意义的时钟周期。
4.3 循环转置
这种技巧是将循环由++改为相反的变化方向--,一个直观的例子就是使用自减的延时函数。
在使用STM32的时候就注意到,如果使用中断实现延时,那么效果就是定时器会进行自减,当寄存器的值减到0的时候,就会触发中断,这样的设计是有其效率的考虑的。
对于MCU,其这样设计是因为其有0转移指令,采用:
- void delay (void)
- {
- unsigned int i;
- for ( i = 0 ; i < 1000 ; i++ );
- }
比
- void delay (void)
- {
- unsigned int i;
- for ( i = 1000 ; i > 0 ; --i );
- }
要慢
在PC级别的CPU上,JNZ(0跳转)指令也具有这种特别的高速指令,所以在循环
对方向没有严苛要求的时候,可以使用max -> min 的方向进行变化。
4.4 优化(do) while循环
学了CSAPP当时用的32位Linux有印象,do while的代码就是写编译器的coder遵循的规范,while循环的汇编实现也是基于do while实现的,所以网上流传使用do while循环会更短:
为了验证这个结论,在Win10的Ubuntu子系统中(X64)进行了反汇编的代码测试:
首先写测试程序如下:
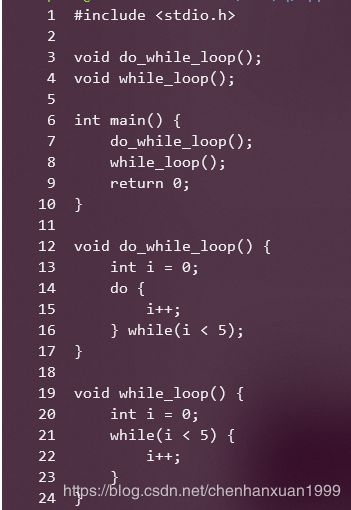
然后进行反汇编如下:
首先反汇编 while_loop 函数:
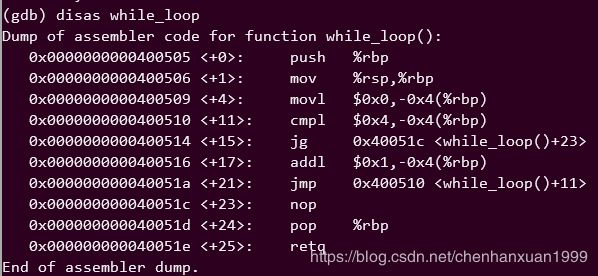
然后反汇编 do_while_loop函数:
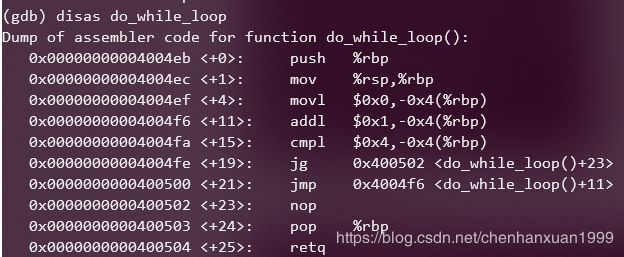
发现两个函数的汇编代码长度相同,都是10条语句。
所以这一条在X64体系中不成立。
4.5 循环展开
传统的优化思路,循环必须要有一个cmp比较+jmp跳转,全部手写肯定会比跳转指令快。
因为每次循环都会减少这两条指令。
4.6 循环归一
将能够在一次循环中处理完毕的数据放到同一个循环中进行处理。
4.7 循环顺序
4.7.1 多层嵌套的循环应该能够使内部的平均计算量最小(下标访问计算等)
4.7.2 不随循环变化的条件判断应该放在循环外部,宁可多写几遍相同的for循环
,也应该避免在一个for循环中写多个if判断,这样在数据量大的时候,每个for循环就要进行巨量的if分支的判断。
4.8 死循环优选
有资料显示for语句的死循环更优秀,但是经过我的测试,发现for和while语句的汇编代码最终是一样的:
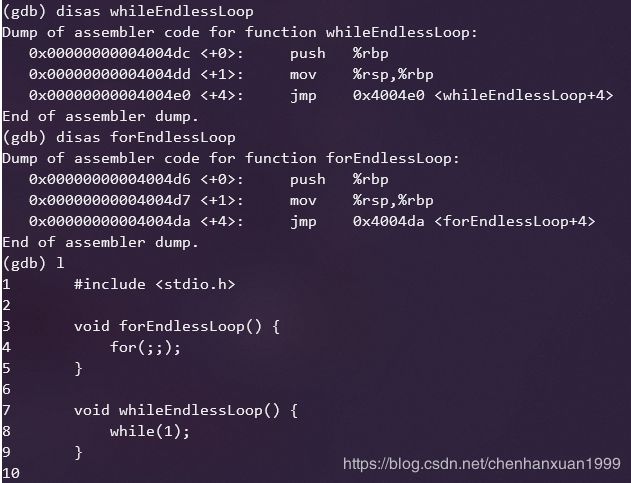
所以该结论在X64下GCC编译不成立。
-
switch 优化
5.1 可能性分析
switch 结构可能会被编译为跳转表结构,也可能被编译为比较树(链)结构。
如果switch 结构被编译为跳转树结构,编译器生成的最终是if-else结构的汇编
代码,会从上到下进行逐次的比较。所以可以使用按照发生的可能性将可能性较
大的情况使用较小的case对应。
5.2 嵌套switch 语句
在外层switch语句的case中或者是default中再次嵌套switch,合理使用可以加速。
通常将发生频率低的情况放在内层的swtich中,较常见的情况放在外层的case中。
5.3 使用函数指针表
对于case中语句过长的switch case有更高效的替换结构——函数指针表。
提速方案就是使用一个函数指针数组来分别对应原来每个case中的解决方案。
假设原来有三个case,分别对应的解决方案是handleFunc1,handleFunc2,
handleFunc3,但是每一个handleFunc的长度都很长的时候,就可以创建一个
函数指针数组如:
- // Code
- ReturnType (* funcPArray[]) (parameters) = {handleFunc1, handleFunc2, handleFunc3};
之后就可以使用函数指针数组进行hash效率的访问,而不用一个个case进行判断,节省了大量的寻址和cmp的时间,例如,假设三个case对应的分别是State1,State2,State3
三个State,通过CatchState() 方法返回当前的状态Statei,那么可以使用:
- // Code
- handleState = funcPArray[CatchState()]();
-
并行优化
6.1 削弱代码依赖性
尽量写没有前后读写依赖的代码,充分利用CPU的流水线,例如:
在求和的时候,假设CPU是一个20核40线程的机器,那么可以声明40个变量,分别做步长为40的求和,最后再对这40个变量进行求和,相比于单变量sum累加,理论加速40倍。当然这样不一定科学,因为还设计到缓存的命中问题,当然能用上这种级别的CPU的机器,CPU一级缓存至少也得2MB以上,我8核心16线程的CPU一级缓存都有1MB,所以抖动现象应该比较小,毕竟步长才40。
需注意的是,如果操作的是浮点数,那么即使设计的计算过程过程在数学意义上是相同的,由于计算机二进制近似表示浮点数的原因,不同的操作顺序可能会得到不同的结果。
6.2 避免读写依赖
计算机中的数据在保存到内存的要遵循先存后读的顺序,即先有效保存,之后才能进行读取。为了让程序绕开这个限制,需要将数据尽可能地存在内部地寄存器中,这样会由更快的读取速度。由于编译器不会自动进行编译优化来避免读写优化的问题,需要手动引进临时寄存器变量来消除数据被不停写回内存堵塞流水线等待写回完成的操作。
而且另外一个常识就是写的开销远大于读,所以要避免向内存中频繁的写数据,尽量借助寄存器完成计算,最后一次性将结果写入。
优化前:
- typedef uint unsigned int;
- for ( uint i = 1 ; i < len ; ++i ) {
- arr[i] = arr[i-1] + vec[i];
- }
优化后:
- uint t(arr[0]);
- for ( uint i = 1 ; i < len ; ++i ) {
- t += vec[i];
- arr[i] = t;
- }
可以看到上面的代码用t直接避免了原来代码中的对arr[i]内存的读操作,最终只有写操作,而这个写操作与寄存器中的t也无关,所以极大提高了代码的效率。
理,可以对下面的代码进行优化:
优化前:
- Type arr_1[len], arr_2[len], arr_3[len];
- for ( uint i = 1 ; i < len ; ++i ) {
- arr_1[i] = arr_2[i] * ( arr_3[i] + arr[i-1] );
- }
优化后:
- Type t(arr_1[0]);
- for ( uint i = 1 ; i < len ; ++i ) {
- t += arr_3[i];
- arr_1[i] = arr_2[i] * t;
- }
-
采用递归
编译器在设计的时候,负责的编译器开发者就对递归代码的生成专门进行了优化,所以只要能够写出优质的多路递归,效率并不需要程序员进行担心,前提是递归算法本身设计也要较为科学。
-
变量优化
通过寄存器变量register关键字提高代码的运行速度,现代的编译器已经能够自动做这样的优化了,但是有时候寄存器探测到某个变量有被修改的可能,就不会将auto变量自动升级为register,程序员应该自己能够显示声明register关键字去提高自己的代码速度。
-
分支优化
减少同级if的数量,增加嵌套if结构数量。