scrapy-splash的使用学习
scrapy-splash是为了解决 scrapy不能够解析JavaScript加载的网页这一问题而存在的。
splash作为js渲染服务,是基于Twisted和QT开发的轻量浏览器引擎。
scrapy-splash模块主要使用了Splash。
也就是说,splash作为一个中间代理将结果返回。
splash官方文档https://splash.readthedocs.io/en/stable/
Splash一般都是运行在Linux环境下,windows下docker容易出错。
下载Splash,一般都是通过docker下载。关于docker是什么,感兴趣的可以搜一下。。。
首先下载 docker。
- 1 更新系统软件。
sudo apt-get update
- 2 安装依赖包。
- sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
- 3 添加官方密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
- 4 添加仓库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
- 5 这个是一篇博客经验之谈。。。再次更新软件,否则下一步安装可能失败
sudo apt-get update
- 6 安装docker
sudo apt-get install docker-ce
- 7查看docker版本
docker -v
- 8 最经典的应该是
sudo docker run hello-world
如果安装过程资源下载一直较慢,可能导致连接超时的话。建议更换一下源。
更换Ubuntu16.04的源
docker已经下载完成且服务已经启动,就可以下载splash了
查看运行状态命令 service docker status
一行命令 安装 如果权限问题 就加 sudo
docker pull scrapinghub/splash
安装完后,启动。
docker run -p 8050:8050 scrapinghub/splash
当splash成功启动后,我们可以看一下效果。打开浏览器访问localhost:8050
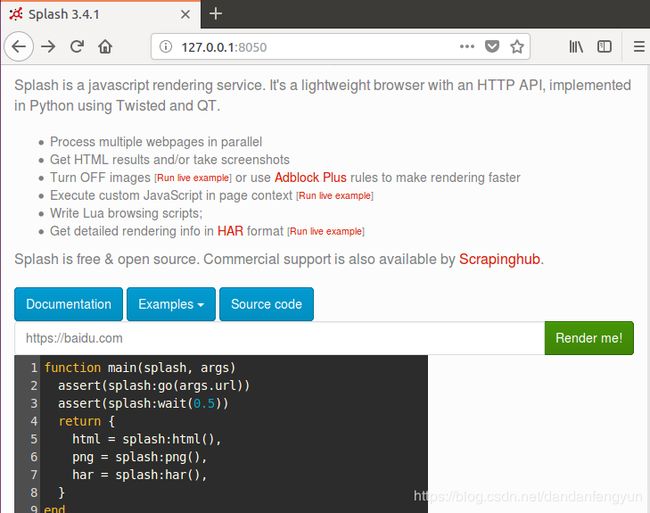
可以在Render me!的输入框中输入我们希望获取的网址。比如https://www.baidu.com然后点击Render me!可以看看结果。
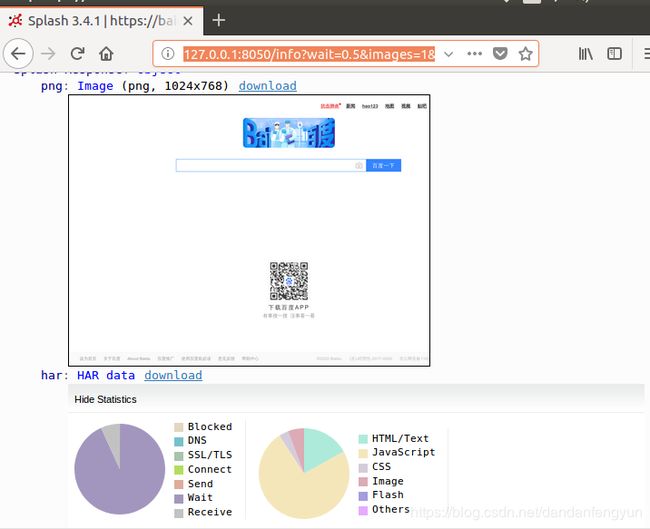
http://127.0.0.1:8050/info?wait=0.5&images=1&expand=1&timeout=90.0&url=https%3A%2F%2Fbaidu.com&lua_source=function+main%28splash%2C+args%29%0D%0A++assert%28splash%3Ago%28args.url%29%29%0D%0A++assert%28splash%3Await%280.5%29%29%0D%0A++return+%7B%0D%0A++++html+%3D+splash%3Ahtml%28%29%2C%0D%0A++++png+%3D+splash%3Apng%28%29%2C%0D%0A++++har+%3D+splash%3Ahar%28%29%2C%0D%0A++%7D%0D%0Aend
会打开这样一个类似网址的界面。其中url=就是我们输入的 https://ww.baidu.com,其他的wait= timeout=等都是一些参数。可以看splash官网。
好了。Splash安装完成并且启动,我们可以创建一个Scrapy-Splash项目了。Splash在里面充当了一个类似代理的角色,scrapy无法解析JavaScript,就把请求交给了splash,splash完成请求后又把相应结果返回给了scrapy。如此,scrapy就可以获得网页解析结果了。
一, 新建一个scrapy项目。修改setting.py内容加上
# 渲染服务的 splash url
SPLASH_URL = 'http://10.31.160.36:8050'
#下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 800,
'scrapy_splash.SplashMiddleware': 801,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 802,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
二, 爬虫文件修改。
import scrapy
from scrapy_splash import SplashRequest
from scrapy.http.response import Response,Request
class TaobaoSpider(scrapy.Spider):
name = 'taobao'
allowed_domains = ['www.taobao.com']
start_urls = ['https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA']
def start_requests(self):
for url in self.start_urls:
# yield SplashRequest(url=url, callback=self.parse,
# args={'wait': 1}, endpoint='render.png')
yield SplashRequest(url=url, callback=self.parse,
args={'wait': 1}, endpoint='render.html')
def parse(self, response):
print(response.url)
# with open("taobao.png", "wb") as file:
# file.write(response.body)
print(response.xpath('//*[@id="mainsrp-pager"]/div/div/div/ul/li[8]/a'))
phoneList = response.xpath("//div[@class='items']/div")
for phone in phoneList:
print(phone.xpath("./div[2]/div[2]/a/text()")[0].get().strip())
重点只是修改了yield 请求。本来是scrapy.Request()类,现在替换成了SplashRequest类。
运行查看结果。