引文:最近的胶囊网络也真的是太火了,身边的朋友也都在各种夸:什么空间相对特征的,那我就写一篇入门级的CNN理解案例,作为自己在CNN领域的一个收尾,同时也给刚入门CNN的同学留下一些我学习CNN时记的笔记以及一些感悟,希望能帮到大家。
一、经典BP神经网络在图像处理方面的表现

上图为一经典BP网络处理MNIST时常用的模型,由于MNIST数据集的像素为28*28,所以输入层设为784个
节点。MNIST数据集只存在十种答案:0123456789, 故设定十个输出节点,中间包含一层500节点的隐藏
层,用于提取像素特征进行运算处理。
这里我们不考虑数据是如何在其内部进行运算的,BP神经网络的运算相信大家已经不陌生了,我们来计算 一下这个神经网络资源耗费问题:
运算过程:输入*weightes1+biases1……
浮点参数量:[28*28*1+500]*500+10 = 642010
这还只是个浅层的BP神经网络,如果将深度增加到四 层,在内部添加一个500节点的隐藏层,那么这个网络 的浮点参数量将是: [(28*28*1+500)*500+500]*500+10 ≈3.2亿
由此可见,越深的BP模型在训练上所需要耗费的计算 机资源就越多,时间也就越长,对于开发者来说这是 将是一笔不菲的开销。
缺点:
1、运算量大导致训练时间过长
2、参数过多导致耗费系统内存资源
3、结构体系单一导致训练效果不理想
针对以上这几点问题,早在上个世纪七八十年代就给出了一种沿用至今的解决方案“感受野”,也就是我们现在所谓的卷积内核(kernerl)或过滤器(filter)。
在本篇文章中主要以卷积核的形式来为大家讲解。
接下来,我们正式的进入卷积神经网络的学习(CNN)
一个标准的经典卷积网络,包含一个输入层、若干卷积层、若干池化层和一个输出层,当然也可能有多个输出层,这些都是后话。
1.1 卷积
如下图,设此图的像素为5*5,我们设一卷积核大小为3*3,步长为[1,1],那么我们最终的数据为整个像素块与卷积核的加权和加上偏置项的和。 (此图没有偏置项)

计算方式
卷积核步长为1时,输出的长宽尺寸为:原图长宽– 卷积核大小+ 1
关于步长不为1的卷积处理所得到的公式 就留给大家当一个思考题。
通道:在实际情况中我们设立的卷积核的深度并不为1,卷积核的功能是要提取图像的特征,显然单一的卷积核在提取多特征并不现实,卷积核的深度就是卷积层的通道,通道数量等于当前卷基层输出的深度,必须由人为设定。
多通道处理方式:实际情况中我们要处理的图像深度大多不为1,学过图像处理的同学可能比较清楚,如RGB色彩图像(全彩图)的深的就为3,虽然这相当于是三个值不同的单通道图像,但也通过一批卷积核进行卷积处理。

如上图,这是一个LeNet-5的第一层卷积,采用了5*5大小的内核,通道数为6,根据内核大小我可以计算出输出的尺寸为28*28,通道数量依旧为6
讲到这里,我们不妨来考虑一个问题,我们刚才所讲的是卷积核步长为1的例子,这些步长为1的卷积核都恰好计算图像中所有的像素块,那如果我们的图像大小为3*3,卷积核大小为2*2,步长为2的时候呢?
我们的卷积核是不是就无法正常工作了?
针对以上的问题,我们引出了全零填充这个概念
1、全零填充(SAME)
卷积输出输入尺寸相同,不考虑卷积核的尺寸,缺失像素填充0。
2、不填充(VALID)
考虑滤波器尺寸。尽量不越过图像边界,也可能边界被填充
让我们回到上面的问题,这个时候我们对3*3的图像进行全零填充,使之成为4*4
如下图
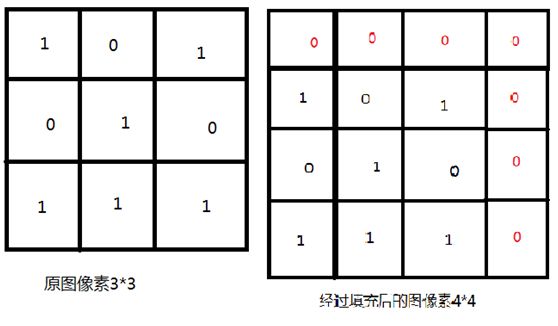
这样一来,我们的卷积核就可以对图像进行卷机处理了。
1.2池化
池化的作用是对图像的上采样与下采样:
上采样是增加图像的参照值, 从而获取图片更的信息,类似于放大图片(像素和算法允许的情况下)
下采样是缩小图像尺寸,忽略细微差距,提高训练速度与效率 常用的池化处理有两种:
最大池化与均值池化
如下图就是最大池化的计算过程。我们可以将下图的池化想象为一个2*2空核,步长为2,其中包含 if语句用于筛选出当前空核所覆盖的区域最大值并输出。
关于均值池化就是计算空核所覆盖区域的平均值并进行输出
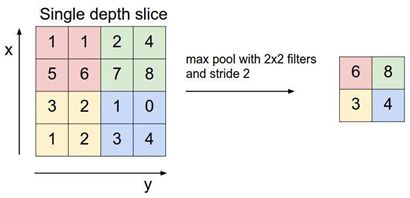
在CNN中采用下采样居多,只对当前层参数进行运算处理,对于通道则不会进行运算。在池化层中也相应的有填充模式,参考1.1讲的卷积填充方式是一样的。
特点:
1、输入通道等于输出通道
2、尺寸改变
3、空核无参数
严格意义上来讲,池化层并不属于神经网络中的layer,仅仅当作一个优化算法的工具
二、LeNet-5分析与实现
LeNet-5是在1998年被提出来用于解决识别手写数字的第一代卷积神经网络, LeNet-5中的数字5是指此网络有五层结构,如下图

在本模型中含两层卷积、两层池化和三层全连接,由于池化层在严格意义上来讲并不将其归为网络深度,所以本模型只有五层。
当时我的笔记:一般的,我们在规划卷积网络时,将池化层当作工具对待,而不是单独的“层”。而层必须包含可被训练的Weight
讲到这里,我来给大家出一道思考小题:
求此卷积网络中的参数量并与BP神经网络进行对比
得出来的答案就是本文的核心问题:为什么我们再图像识别领域不推荐用BP模型
除了参数的数量,我们还要关注一个问题:模型训练效率
在第一节给大家介绍BP网络处理MNIST的模型,在使用RELU作为激活函数迭代10000次的精度为98.4%
而LeNet-5同样使用RELU作为激活函数迭代10000次时的精度可以达到99.3%
结语:本文仅给出了LeNet-5这种鼻祖类型的CNN供大家入门,有学习能力的同学还可以去了解一下VGG、Inception、AlexNet等等这些经典卷积模型.
注:本文原创,已售与“昂钛客AI”