Sparkstreaming-windows测试过程异常问题记录
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -verbose:gc -XX:+UseG1GC -Xloggc:gc.log" \ --conf 'spark.driver.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -verbose:gc -XX:+UseG1GC -Xloggc:gc.log' \
1、异常问题记录:
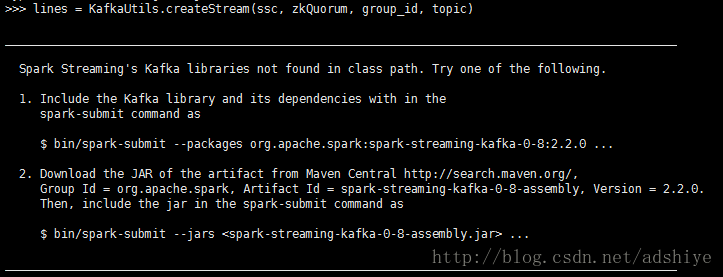
解决办法:去http://search.maven.org上下载对应的.jar,如下载:spark-streaming-kafka-0-8-assembly_2.11-2.4.5.jar
放在site-page的目录下,我这边的路径为:/usr/lib/python2.7/site-packages/pyspark/jars,而我python安装路径:/usr/bin/python2.7
2. hdfs上无权限问题:
org.apache.hadoop.security.AccessControlException: Permission denied: user=angela, access=WRITE,
inode="/user/angela/checkpoint/sparkstreaming_windows_31229":hdfs:hdfs:drwxr-xr-x
解决方案 ;找对应的同事新建一个/user/angela目录,并赋予相应权限。
3.代码报错:
20/04/01 14:26:30 ERROR scheduler.JobScheduler: Error generating jobs for time 1585722390000 ms
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input Pattern hdfs://CQBAK/user/etl/SHHadoopStream/BulkZip/{} matches 0 files
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.spark.input.StreamFileInputFormat.setMinPartitions(PortableDataStream.scala:51)
at org.apache.spark.rdd.BinaryFileRDD.getPartitions(BinaryFileRDD.scala:51)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251)
解决办法:在trans方法里面添加一行代码:rdd.isEmpty()的判断
rdef trans(rdd):
sc = rdd.context
if rdd.isEmpty():
return rdd
bulkZipEventList = rdd.collect()
hdfsPath = "hdfs:///user/etl/HadoopStream/HaHa/%s" % (generateHDFSPathListFromFileList(EventList))
rdd_zip_files = sc.binaryFiles(hdfsPath, 128)
return rdd_zip_files
4.在SparkStreaming中的 finallyDS.foreachRDD(getCurrView),在getCurrnView方法中,根据rdd.context生产sc,然后生成SQLcontext和Hivecontext,其中HiveContext中是读取hive中的数据,项目目录下有添加hive-site.xml,SparkConf中也设置了hive元数据的配置:sconf.set("hive.metastore.uris", "thrift://s3.hdp.com:9083"),但程序依旧报错:pyspark.sql.utils.AnalysisException: u"Table or view not found: `dtd_ods`.`stn_history`; line 1 pos 14;\n'GlobalLimit 1\n+- 'LocalLimit 1\n +- 'Project [*]\n +- 'UnresolvedRelation `dtd_ods`.`stn_history`\n"
解决办法:各种尝试后,发现必须先生成HiveContext,在生成SQLContext。代码如下:
sc=rdd.context
hiveContext = HiveContext(sc)
sqlContext = SQLContext(sc)
7.Py4JJavaError: An error occurred while calling o247.showString.
: java.lang.AssertionError: assertion failed: No plan for HiveTableRelation `dtd_ods`.`stn_history`, org.apache.hadoop.hive.ql.io.orc.OrcSerde, [servicetag#236, testitem#237, station#238, test_result#239, uut_state_message#240, stn_timestamp#241, uut_state_timestamp#242, last_uut_state_timestamp#243, last_time#244, product_name#245, site_code#246, localization#247, operation_shift#248, gbu#249, product_line#250, date_datetime#251, create_timestamp#252], [day#253]
8.Py4JJavaError: An error occurred while calling o254.collectToPython.
: java.lang.IllegalStateException: table stats must be specified.
at org.apache.spark.sql.catalyst.catalog.HiveTableRelation$$anonfun$computeStats$2.apply(interface.scala:629)
at org.apache.spark.sql.catalyst.catalog.HiveTableRelation$$anonfun$computeStats$2.apply(interface.scala:629)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.catalyst.catalog.HiveTableRelation.computeStats(interface.scala:628)
at org.apache.spark.sql.catalyst.plans.logical.statsEstimation.SizeInBytesOnlyStatsPlanVisitor$.default(SizeInBytesOnlyStatsPlanVisitor.scala:55)
at org.apache.spark.sql.catalyst.plans.logical.statsEstimation.SizeInBytesOnlyStatsPlanVisitor$.default(SizeInBytesOnlyStatsPlanVisitor.scala:27)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlanVisitor$class.visit(LogicalPlanVisitor
10.
20/04/08 15:38:17 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://s1:4040
Exception in thread "main" java.lang.NoClassDefFoundError: com/sun/jersey/api/client/config/ClientConfig
at org.apache.hadoop.yarn.client.api.TimelineClient.createTimelineClient(TimelineClient.java:55)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.createTimelineClient(YarnClientImpl.java:181)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.serviceInit(YarnClientImpl.java:168)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:163)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:161)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBac
解决方案:将/usr/hdp/2.6.3/hadoop-yarn/lib下面的jersey-client-1.9.jar,jersey-core-1.9.jar copy到/usr/lib/python2.7/site-packages/pyspark/jars下。同时将jars下的jersey-client-2.22.2.jar mv为jersey-client-2.22.2.jar.backup
参考:https://my.oschina.net/xiaozhublog/blog/737902
10.Exception in thread "main" java.lang.IllegalAccessError: tried to access method org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider.getProxyInternal()Ljava/lang/Object; from class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProviderat org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider.init(RequestHedgingRMFailoverProxyProvider.java:75)at org.apache.hadoop.yarn.client.RMProxy.createRMFailoverProxyProvider(RMProxy.java:163)at org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:94)at org.apache.hadoop.yarn.client.ClientRMProxy
解决办法:将yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider
修改为:yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
参考:https://www.w3xue.com/exp/article/20202/74219.html
11.python 终端 ImportError: ('No module named
解决方法:在sparkContext中添加依赖的python文件
sc.addPyFile('./ParseNewTest.py')
sc.addPyFile('./Parseommon.py')
sc.addPyFile('./Parseh.py')
12.程序从checkpioint目录恢复时报: ImportError: ('No module named
pache.spark.api.python.PythonException (Traceback (most recent call last):
File "/mnt/hadoop/local/usercache/hive/appcache/application_1587440040048_0489/container_e149_1587440040048_0489_01_000003/pyspark.zip/pyspark/worker.py", line 98, in main
command = pickleSer._read_with_length(infile)
File "/mnt/hadoop/local/usercache/hive/appcache/application_1587440040048_0489/container_e149_1587440040048_0489_01_000003/pyspark.zip/pyspark/serializers.py", line 164, in _read_with_length
return self.loads(obj)
File "/mnt/hadoop/local/usercache/hive/appcache/application_1587440040048_0489/container_e149_1587440040048_0489_01_000003/pyspark.zip/pyspark/serializers.py", line 422, in loads
return pickle.loads(obj)
File "/mnt/hadoop/local/usercache/hive/appcache/application_1587440040048_0489/container_e149_1587440040048_0489_01_000003/pyspark.zip/pyspark/cloudpickle.py", line 664, in subimport
__import__(name)
ImportError: ('No module named ParseBulkpper',
描述:程序第一次启动能正常运行,第二次启动从checkpoint目录恢复时报找不到包。
解决办法:在spark-submit中添加--files产生,此参数功能:--files FILES:逗号隔开的文件列表,这些文件将存放于每一个工作节点进程目录下。