scrapy配合scrapy-splash抓取js动态渲染内容
最近想学习下scrapy-splash,之前用了seleium配合chrome总感觉有点慢,想要研究下scrapy-splash, 那知网上的内容很多不靠谱的。综合了好多文章,终于成功了。记录下,以免遗忘,也做一个正确的指导。
软件环境:
win 10 64位
python 3.6
scrapy 1.3.3
scrapy-splash 0.7.2
使用的是anaconda,忘了scrapy是自带的还是后面装的了,如果安装好的anaconda没有,就直接用pip install scrapy 安装下好了。
ScrapySplash 安装
注意,ScrapySplash需要使用docker,理解的人我就不用解释,不理解的人和一样,按操作执行就好了。这里的ScrapySplash与上面软件环境里的是不一样的,上面那个是在scrapy中用import引入使用的时候用的,这里的相当于一个软件,你要安装了才能使用。
安装 Docker
准备
由于ScrapySplash要在docker里使用,我们先安装docker,安装之前先检查自己的电脑是不是win 10 64位,还有没有开启hyper虚拟化。
-
查看电脑版本
win+x, 然后点击系统(Y) :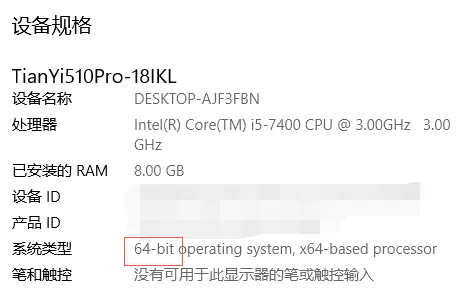
64位系统.png
-
查看hyper是否启用
ctrl+shift+esc打开任务管理器,然后点击性能,可以从图片上看到。红色框的地方。
查看hyper是否启用.png
如果发现hyper没有开启,也没关系,网上搜索一下有相关介绍,我这里简单说一下。WIN+X然后点击应用与功能,进入后右边有个程序与功能,点击进入后点击左侧的启用或关闭windows功能按钮,在出现的应用里找到hyper-V然后勾选上。具体进入方法不同的win10可能有些不一样,只要进入到程序与功能就好。
不过有的同学可能根据这个方法会找不到,这个就要进入到bios里去打开了。进入bios后找到Virtualization Technology,启动(enable)就好了。 具体方法就不说了,不同电脑进入的方法都不一样,请大家根据自己的电脑找相应资料。
正式安装
win 10的版本不同会有很多问题。
常规安装:从官网的下面地址可以下载
https://download.docker.com/win/stable/InstallDocker.msi
如果这种方式安装出错或者安装好后报错,请使用docker toolbox安装:
https://docs.docker.com/toolbox/toolbox_install_windows/
注意: docker 使用的是虚拟化技术,因此安装的时候就一起安装virtualbox, 请一定要勾选上,如果已经安装过则可以不用。
想要深入了解Docker,可以到Docker 官网:https://docs.docker.com/
启动环境
安装好docker后,打开docker,正常安装的可以直接用cmd进行操作,如果是toolbox安装的,请使用Docker Quickstart Terminal操作。
我是用toolbox安装的,因此后面命令行操作都是在Docker Quickstart Terminal里面。
打开命令行:
第一次打会比较慢,因为还在启动virtualbox虚拟机。等待一段时间后,出现下面的界面,说明安装成功了。
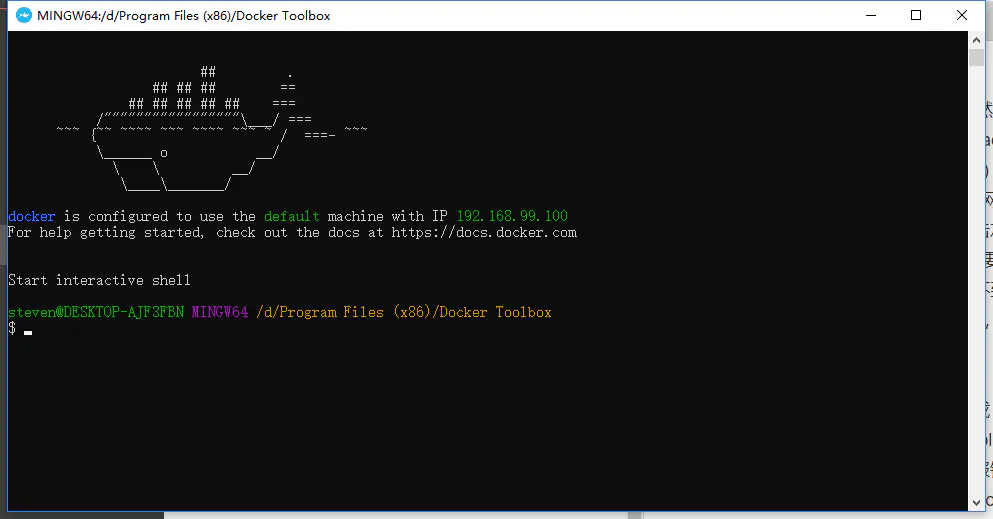
docker启动后.png
里面有一个IP, 请记住,这是后面要用到的东西。
下载ScrapySplash
在命令行里输入docker run -p 8050:8050 scrapinghub/splash, 这是docker的使用方式,表示启动splash, 第一次启动是本地没有splash应用,会自动从docker hub去下载,这个过程我们不用管,慢慢等好了。
下载好后,会直接启动应用,出现下面的界面:
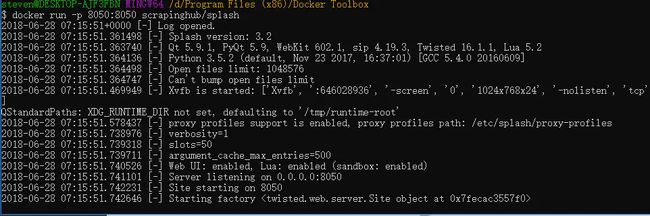
启动成功.png
这时我们可以在浏览器里输入http://192.168.99.100:8050/,这里的IP就是前面出现的那个IP。出现下面的界面就说明启动成功了。
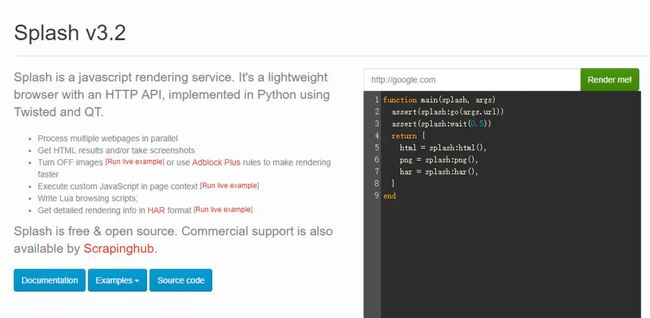
splash启动成功.png
注意:我参考相关文章时总能看到说是输入http://localhost:8050/, 我不知道是大家的电脑不一样,还是都是人云亦云,这是个坑,我还以为我安装出错,都重装了好几次,还是不出现上面的界面。按我理解localhost是本地主机的意思,可以我们的应用是在虚拟机里如果是本地主机, 那说明要在虚拟机里打开浏览器了,可是我们是在win 10里操作呀,难道其他文章的作者都是直接在虚拟机里操作,此处不明,如有人能告知,不胜感激。
好了, 至此,整个环境已经搭建好了,下面开始scrapy爬虫设置了。
scrapy爬虫设置
scrapy项目其实和正常的项目没什么区别。如有不懂的,可以参看我另外的文章 Scrapy 抓取本地论坛招聘内容 (一)
这里我创建一个新的项目做为学习用:
> scrapy startproject jdproject
> cd jdproject/
> scrapy genspider jd https://www.jd.com/
注意: 这里也是在命令行里操作,不过不用在 Docker Quickstart Terminal, 在正常的cmd里也可以
打开jdproject/spiders/jd.py, 修改内容:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy_splash.request import SplashRequest, SplashFormRequest
class JdSpider(scrapy.Spider):
name = "jd"
def start_requests(self):
splash_args = {"lua_source": """
--splash.response_body_enabled = true
splash.private_mode_enabled = false
splash:set_user_agent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36")
assert(splash:go("https://item.jd.com/5089239.html"))
splash:wait(3)
return {html = splash:html()}
"""}
yield SplashRequest("https://item.jd.com/5089239.html", endpoint='run', args=splash_args, callback=self.onSave)
def onSave(self, response):
value = response.xpath('//span[@class="p-price"]//text()').extract()
print(value)
打开jdproject/settings.py, 修改:
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.99.100:8050/" # 自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
测试
这里我用的是https://item.jd.com/5089239.html做测试,要拿产品价格。
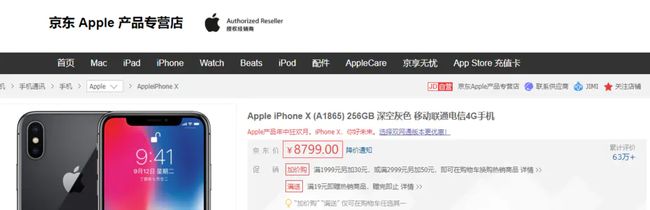
jd.png
运行爬虫:

结果.png
可以很清楚的看到我们要的价格已经出现了。
至此,我们成功的部署好ScrapySplash, 并且成功的实现了爬虫项目。
如果对splash感兴趣的话,可以参考官网:http://splash.readthedocs.io/en/stable/
作者:Stevent
链接:https://www.jianshu.com/p/8a8d0ceed8d3
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。