Scrapy - Request 和 Response(请求和响应)
Requests and Responses:http://doc.scrapy.org/en/latest/topics/request-response.html
Requests and Responses(中文版):https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/request-response.html
请求 和 响应
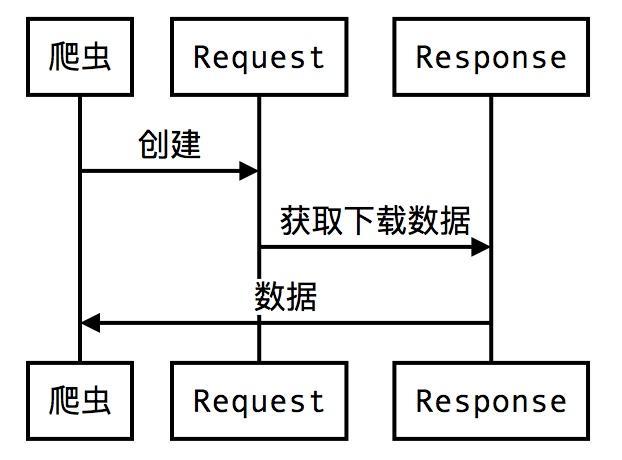
通常,Request对象 在 爬虫程序中生成并传递到系统,直到它们到达下载程序,后者执行请求并返回一个 Response对象,该对象 返回到发出请求的爬虫程序。
上面一段话比较拗口,有 web 经验的同学,应该都了解的,不明白看下面的图大概理解下。
- 爬虫 -> Request:创建
- Request -> Response:获取下载数据
- Response -> 爬虫:数据
Request 和 Response 类 都有一些子类,它们添加基类中不需要的功能。这些在下面 的 请求子类 和 响应子类中描述。
Request objects
class scrapy.http.Request (url [, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags] )
一个 Request 对象 表示一个 HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成 Response 对象。
参数:
- url (string) – the URL of this request
- callback (callable) – the function that will be called with the response of this request (once its downloaded) as its first parameter. For more information see Passing additional data to callback functions below. If a Request doesn’t specify a callback, the spider’s
parse()method will be used. Note that if exceptions are raised during processing, errback is called instead. - method (string) – the HTTP method of this request. Defaults to
'GET'. - meta (dict) – the initial values for the
Request.metaattribute. If given, the dict passed in this parameter will be shallow copied. - body (str or unicode) – the request body. If a
unicodeis passed, then it’s encoded tostrusing the encoding passed (which defaults toutf-8). Ifbodyis not given, an empty string is stored. Regardless of the type of this argument, the final value stored will be astr(neverunicodeorNone). - headers (dict) – the headers of this request. The dict values can be strings (for single valued headers) or lists (for multi-valued headers). If
Noneis passed as value, the HTTP header will not be sent at all. - cookies (dict or list) –
the request cookies. These can be sent in two forms.
- Using a dict:
request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}) - Using a list of dicts:
request_with_cookies = Request(url="http://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}])
The latter form allows for customizing the
domainandpathattributes of the cookie. This is only useful if the cookies are saved for later requests.When some site returns cookies (in a response) those are stored in the cookies for that domain and will be sent again in future requests. That’s the typical behaviour of any regular web browser. However, if, for some reason, you want to avoid merging with existing cookies you can instruct Scrapy to do so by setting the
dont_merge_cookieskey to True in theRequest.meta.Example of request without merging cookies:
request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}, meta={'dont_merge_cookies': True})For more info see CookiesMiddleware.
- Using a dict:
- encoding (string) – the encoding of this request (defaults to
'utf-8'). This encoding will be used to percent-encode the URL and to convert the body tostr(if given asunicode). - priority (int) – the priority of this request (defaults to
0). The priority is used by the scheduler to define the order used to process requests. Requests with a higher priority value will execute earlier. Negative values are allowed in order to indicate relatively low-priority. - dont_filter (boolean) – indicates that this request should not be filtered by the scheduler. This is used when you want to perform an identical request multiple times, to ignore the duplicates filter. Use it with care, or you will get into crawling loops. Default to
False. - errback (callable) – a function that will be called if any exception was raised while processing the request. This includes pages that failed with 404 HTTP errors and such. It receives a Twisted Failure instance as first parameter. For more information, see Using errbacks to catch exceptions in request processing below.
- flags (list) – Flags sent to the request, can be used for logging or similar purposes.
对应中文解释:
url(string)- 此请求的网址。请记住,此属性包含转义的网址,因此它可能与构造函数中传递的网址不同。此属性为只读。更改请求 的 URL 可以使用 Request 的replace()。callback(callable)- 将使用此请求的响应(一旦下载)作为其第一个参数调用的函数。有关更多信息,请参阅下面的将附加数据传递给回调函数。如果请求没有指定回调,parse()将使用spider的 方法。请注意,如果在处理期间引发异常,则会调用errback。method(string)- 此请求的HTTP方法。默认为'GET'。注意:必须保证是大写的。例如:"GET","POST","PUT"等meta(dict)- 属性的初始值Request.meta。如果给定,在此参数中传递的 dict 将被浅复制。包含此请求的任意元数据的字典。此dict对于新请求为空,通常由不同的Scrapy组件(扩展程序,中间件等)填充。因此,此dict中包含的数据取决于您启用的扩展。有关Scrapy识别的特殊元键列表,请参阅Request.meta特殊键。当使用copy()或者replace()克隆请求时,此 dict 是 浅复制 的 。在爬虫中可以通过 response.meta 属性访问。body(str或unicode)- 请求体。即 包含请求正文的 str。此属性为只读。更改body可以使用 Request 的replace()。如果unicode传递了a,那么它被编码为 str使用传递的编码(默认为utf-8)。如果 body 没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个str(不会是unicode或None)。headers(dict)- 这个请求的头。dict 值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None作为值传递,则不会发送HTTP头。cookie(dict或list)- 请求cookie。这些可以以两种形式发送encoding(string)- 此请求的编码(默认为'utf-8')。此编码将用于对URL进行百分比编码,并将正文转换为str(如果给定unicode)。priority(int)- 此请求的优先级(默认为0)。调度器使用优先级来定义用于处理请求的顺序。具有较高优先级值的请求将较早执行。允许负值以指示相对低优先级。dont_filter(boolean)- 表示此请求不应由调度程序过滤。当您想要多次执行相同的请求时忽略重复过滤器时使用。小心使用它,或者你会进入爬行循环。默认为False。-
errback(callable)- 如果在处理请求时引发任何异常,将调用的函数。这包括失败的404 HTTP错误等页面。它接收一个Twisted Failure实例作为第一个参数。有关更多信息,请参阅使用errbacks在请求处理中捕获异常。
-
copy()方法
返回一个新的请求,它是这个请求的副本。另请参见: 将附加数据传递到回调函数。 -
replace([url, method, headers, body, cookies, meta, encoding, dont_filter, callback, errback])
返回具有相同成员的Request对象,但通过指定的任何关键字参数赋予新值的成员除外。该属性Request.meta是默认复制(除非新的值在给定的meta参数)。另请参见 将附加数据传递给回调函数
repalce() 方法使用:首先看 下 这个方法在源码中的定义(scrapy/http/request/__init__.py):
"""
This module implements the Request class which is used to represent HTTP
requests in Scrapy.
See documentation in docs/topics/request-response.rst
"""
import six
from w3lib.url import safe_url_string
from scrapy.http.headers import Headers
from scrapy.utils.python import to_bytes
from scrapy.utils.trackref import object_ref
from scrapy.utils.url import escape_ajax
from scrapy.http.common import obsolete_setter
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError('callback must be a callable, got %s' % type(callback).__name__)
if errback is not None and not callable(errback):
raise TypeError('errback must be a callable, got %s' % type(errback).__name__)
assert callback or not errback, "Cannot use errback without a callback"
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
self.flags = [] if flags is None else list(flags)
@property
def meta(self):
if self._meta is None:
self._meta = {}
return self._meta
def _get_url(self):
return self._url
def _set_url(self, url):
if not isinstance(url, six.string_types):
raise TypeError('Request url must be str or unicode, got %s:' % type(url).__name__)
s = safe_url_string(url, self.encoding)
self._url = escape_ajax(s)
if ':' not in self._url:
raise ValueError('Missing scheme in request url: %s' % self._url)
url = property(_get_url, obsolete_setter(_set_url, 'url'))
def _get_body(self):
return self._body
def _set_body(self, body):
if body is None:
self._body = b''
else:
self._body = to_bytes(body, self.encoding)
body = property(_get_body, obsolete_setter(_set_body, 'body'))
@property
def encoding(self):
return self._encoding
def __str__(self):
return "<%s %s>" % (self.method, self.url)
__repr__ = __str__
def copy(self):
"""Return a copy of this Request"""
return self.replace()
def replace(self, *args, **kwargs):
"""Create a new Request with the same attributes except for those
given new values.
"""
for x in ['url', 'method', 'headers', 'body', 'cookies', 'meta', 'flags',
'encoding', 'priority', 'dont_filter', 'callback', 'errback']:
kwargs.setdefault(x, getattr(self, x))
cls = kwargs.pop('cls', self.__class__)
return cls(*args, **kwargs)
replace() 方法 返回一个 类 的 实例,需要一个变量来保存这个类 实例。所以使用方式如下:
if __name__ == '__main__':
from scrapy.http.request import Request
r = Request(url='https://www.baidu.com')
r_1 = r.replace(url="https://www.google.com")
print('r_1.url : {0}'.format(r_1.url))
print('r_1.method : {0}'.format(r_1.method))
r_2 = r.replace(method='post')
print('r_2.url : {0}'.format(r_2.url))
print('r_2.method : {0}'.format(r_2.method))
r._set_url('http://www.sina.com')
print('r.url : {0}'.format(r.url))
print('r.method : {0}'.format(r.method))运行结果截图:

将 附加数据 传递 给 回调函数
也就是 从 request 中传递数据 到 response
请求的回调是当下载该请求的响应时将被调用的函数。将使用下载的Response对象作为其第一个参数来调用回调函数。
Example:
def parse_page1(self, response):
return scrapy.Request("http://www.example.com/some_page.html",
callback=self.parse_page2)
def parse_page2(self, response):
# this would log http://www.example.com/some_page.html
self.logger.info("Visited %s", response.url)在某些情况下,您可能有兴趣向这些回调函数传递参数,以便稍后在第二个回调中接收参数。您可以使用该Request.meta属性。
以下是使用此机制传递项目以填充来自不同页面的不同字段的示例:
def parse_page1(self, response):
item = MyItem()
item['main_url'] = response.url
request = scrapy.Request("http://www.example.com/some_page.html",
callback=self.parse_page2)
request.meta['item'] = item
yield request
def parse_page2(self, response):
item = response.meta['item']
item['other_url'] = response.url
yield item
使用 errbacks 在请求处理中捕获异常
请求的 errback 是在处理异常时被调用的函数。
它接收一个Twisted Failure实例作为第一个参数,并可用于跟踪连接建立超时,DNS错误等。
这里有一个 示例爬虫 记录所有错误,并捕获一些特定的错误,如果需要:
import scrapy
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
class ErrbackSpider(scrapy.Spider):
name = "errback_example"
start_urls = [
"http://www.httpbin.org/", # HTTP 200 expected
"http://www.httpbin.org/status/404", # Not found error
"http://www.httpbin.org/status/500", # server issue
"http://www.httpbin.org:12345/", # non-responding host, timeout expected
"http://www.httphttpbinbin.org/", # DNS error expected
]
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(u, callback=self.parse_httpbin,
errback=self.errback_httpbin,
dont_filter=True)
def parse_httpbin(self, response):
self.logger.info('Got successful response from {}'.format(response.url))
# do something useful here...
def errback_httpbin(self, failure):
# log all failures
self.logger.error(repr(failure))
# in case you want to do something special for some errors,
# you may need the failure's type:
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
self.logger.error('HttpError on %s', response.url)
elif failure.check(DNSLookupError):
# this is the original request
request = failure.request
self.logger.error('DNSLookupError on %s', request.url)
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error('TimeoutError on %s', request.url)
Request.meta 特殊键
该 Request.meta 属性可以包含任何任意数据,但有一些特殊的键由 Scrapy 及其内置扩展识别。
那些是:
dont_redirect
dont_retry
handle_httpstatus_list
handle_httpstatus_all
dont_merge_cookies(参见cookies构造函数的Request参数)
cookiejar
dont_cache
redirect_urls
bindaddress
dont_obey_robotstxt
download_timeout
download_maxsize
download_latency
proxy
bindaddress:用于执行请求的出站IP地址的IP。
download_timeout:下载器在超时前等待的时间量(以秒为单位)。参见:DOWNLOAD_TIMEOUT。
download_latency:自请求已启动以来,用于获取响应的时间量,即通过网络发送的HTTP消息。此元键仅在响应已下载时可用。虽然大多数其他元键用于控制Scrapy行为,但这应该是只读的。
Request (请求) 的 subclasses(子类)
Here is the list of built-in Request subclasses. You can also subclass it to implement your own custom functionality.
这是 Scrapy 框架中 Request 类 的 内建 subclasses(子类) 列表。你也可以 通过继承来实现它的一个子类,用来实现啊你自己自定的功能
FormRequest objects
FormRequest类 扩展了 Request 具有处理HTML表单的功能的基础。它使用lxml.html表单 从 Response对象 的 表单数据 预填充 表单字段。
FormRequest
class scrapy.http.FormRequest(url [, formdata, ...])
FormRequest类 增加了新 的构造函数的 参数。其余的参数与 Request类 相同,这里没有记录。
- 参数:formdata(元组的dict或iterable) - 是一个包含HTML Form数据的字典(或(key,value)元组的迭代),它将被url编码并分配给请求的主体。
from_response
FormRequest对象 添加下面的方法到 标准的 Request 对象中:
classmethod from_response(response[, formname=None, formid=None, formnumber=0, formdata=None, formxpath=None, formcss=None, clickdata=None, dont_click=False, ...])
Returns a new FormRequest object with its form field values pre-populated with those found in the HTML element contained in the given response. For an example see Using FormRequest.from_response() to simulate a user login.
返回一个新 FormRequest对象,其中它的 form(表单) 字段值 已预先设置,用在给定的 Response 对象 中 包含的 HTML 中 发现的 HTML