 《笔者带你剖析Python3.x》
《笔者带你剖析Python3.x》
前言
其实不太想写跟Java无关的东西,但是实在憋得难受,想想一个项目组的其他同事都回家过年了,就剩下我一个苦逼的还在坚守在战斗一线,酱油也打了一段时间了,再憋下去难受了,所以趁着过年前发一篇博文吧,也可以打发下时间,何乐而不为呢?
废话说了一箩筐,回到正题。Python相信有不少开发人员,尤其是运维人员应该是非常熟悉的,那么请大家听我好好掰扯下Python究竟能够做什么,如果你觉得Python是个好东西,那么也请你尝试着使用它为你的项目增添一点色彩。笔者本文所使用的Python版本为3.x,尽管和Python2.x相比,3.x 在语法层面的改变是比较大的,但是请大家不要去纠结这些问题,只需要听笔者为你一一道来即可。
目录
一、Python简介;
二、Python的下载与安装;
三、第一个Python程序;
四、基本语法的使用
五、函数的使用;
六、流程控制语句;
七、面向对象特性;
八、I/O操作;
九、线程操作;
一、Python简介
其实看笔者这篇博文的朋友,更关心的是Python是什么,以及究竟能够为我们的项目带来什么好处?其实笔者在第一次接触Python的时候,立马就被这炫酷和简易的语法吸引住了,因为使用Python所带来的好处太多了。简单来说,Python其实是一门基于解释性/编译性的动态、面向对象编程语言,这里笔者要稍微解释下所谓的解释性/编译性问题。对Java有所了解的开发人员应该知道,JIT编译器所带来的改变对于Java程序的运行性能是起到了至关重要的作用,使得Java程序的运行性能有了质的飞跃,毫不逊色于C/C++编写的程序的执行性能,这是因为HotSpot VM中的JIT编译器会在运行时结合热点探测功能将频繁被调用的代码标记为“热点代码”然后经过分层优化编译技术将Java代码直接编译为本地代码。这种运行时的编译技术,必然比静态编译拥有更好的编译质量,毕竟静态编译是无法准确预估程序在执行过程中所有的运行时热点的。
和Java一样,Python的执行引擎究竟是基于解释执行呢,还是编译执行,或者是混合执行都取决于底层的VM(笔者博文全部统称为VM)。目前比较常见的Python VM有:CPython、IPython、PyPy,以及Jython(HotSpot VM)。关于这几个VM大家可以去官网了解下。简单来说,CPython是Python的官方缺省解释器,基于解释运行;而IPython是建立在CPython之上的一个交互式解释器;PyPy内置有JIT编译器,执行性能相对而言会比前几种高效许多倍;而Jython其实就是将Python代码编译为字节码后运行在HotSpot VM中,结合HotSpot VM的解释器+JIT编译器的混合执行引擎,可以达到高效执行的效果,不过更重要的是使用Jython可以很好的与Java代码交互(并不仅限于特定的语言,CPython可以是C、C++)。是的,你没有听错,简单到你会以为Python天生就是为了粘合Java代码而生!因此Python还有一个很好听的名字,那就是“胶水语言”。
当然不是说Python语言的作用就是纯粹的粘合其他语言一起执行,尽管Python最大的优点确实是这个,但是任何高级语言能做的事情,Python都能够做到,而且代码产出效率极快。因此大部分企业都会在项目需求较紧的时候使用Python快速上线,然后后续逐渐使用其他适合的编程语言逐步替换之前由Python编写的功能模块,以此保证代码的结构严谨性。
二、Python的下载与安装
如果你Java功力很强,那么学习Python就是轻而易举,这就好比《倚天屠龙记》中的张无忌掌握九阳神功后,学习太极拳的轻车熟路,其实道理都是一样的。当然如果你本身骨子里并无任何编程语言基础,学习Python同样也不会感觉到吃力,因为相对于Java\C\C++之类的编程语言,Python的学习可以算是相当简单的。如果按照笔者的经验来判断,除了比HTML稍微复杂点,几乎是个人都能够轻而易举的掌握Python这门语言。笔者甚至在考虑,过年回家的时候,是否有必要教老妈使用Python编写一个小程序?
又说了一大堆废话,回到主题,Python的下载和安装。大家可以登录https://www.python.org/下载Python,笔者本文所使用的版本并没有采用最新的3.4.2,而是3.3.0,没有特殊的寓意,因此你可以自由选择和笔者保持一致的版本,同样也可以下载最新的版本,当然千万不要下载Python2.x版本,毕竟它们在语法层面上的差距是非常大的。
当成功下载好Python后,在安装的时候记得勾选选项“path”,否则只能够在安装好后,手动配置Python的环境变量(PATH=安装路径)。当大家成功安装好Python后,为了检验是否安装成功,大家可以通过控制台,输入命令“Python -V”(大写V,Python大小写敏感)验收结果,如果控制台输出的是Python的版本号,则意味着安装成功,反之安装失败。
三、第一个Python程序
所谓工欲善其事必先利其器,在使用Python编写程序之前,首先要做的就是准备好Python的开发工具,当然笔者不建议新手一上来就是用各种IDE,而是建议你使用文本编辑器就可以了,比如Editplus,它会是你初次接触Python的利器,希望大家记住,学习任何一门新技术,或者新语言之前,必然首先需要记住一些常用的函数、语法风格,而不是什么都是依靠IDE工具来“饭来张口,衣来伸手”,不要让你的大脑过度偷懒,会生锈的。
当然如果你使用Python有一断时间了,或者正在准备使用Python运用在项目中时,就有必要考虑工作效率的问题了,因为笔者也不希望你浪费过多的时间在回忆应该调用那个函数,以及函数的名字叫什么,否则你可能离打包走人不远了。简单来说,Python的IDE工具非常多,如果是JYthon,那么使用PyDEV是非常好的,以插件的形式集成在神器Eclipse中,无疑为Java开发人员带来了方便。当然本文只是单纯的讲解Python的使用,并且VM也是使用CPython,因此Pycharm不得不说是编写Python的好帮手。
笔者不打算啰嗦的为大家科普IDE工具应该怎么使用,请自行Google。当成功启动IDE工具或者文本编辑器后,接下来我们就开始编写我们的第一个Python程序,如下所示:
print("Hello World")
当执行上述程序时,控制台将会输出“Hello World”。纳尼,你没有看错,Python就是这么简单,严格意义上按照模块进行划分,不需要显式的先编写一个类、在编写方法,再来写语句。嗦嘎德斯捏。
Sorry,笔者忘记了一件事情,按照惯例不应该先讲如何在IDE工具中或者文本编辑器中编写Python代码,而是应该让大家知道Python的交互式运行环境。没关系,现在讲似乎也不迟。Python其实有2种类型的运行环境,一种是基于交互式环境,而另外一种则是我们刚才使用到的传统环境。这里笔者所指的交互式环境,其实更多应用在测试、练习上,适合刚接触Python的开发人员,毕竟在交互式环境中,写一行代码,立马就可以得到结果,如下所示:
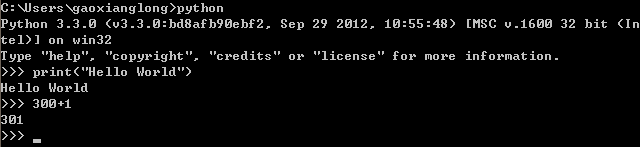
除了在刚开始学习Python的时候,或者在测试练习上会使用到Python自带的交互式环境外,实际的项目开发过程中,这种做法并不常见,因为代码无法固化,每次都要重新编写,意义何在?
四、基本语法的使用
笔者在本节中将会介绍Python的基本语法的使用,涵盖了:变量的定义、运算符、表达式、数据类型、数据结构等知识点。请不要责怪笔者的“不耐烦”,毕竟这些太过于基础的技术,笔者实在是不忍心大费周章,浪费纸墨和口水去讲解,毕竟后续还有其它的知识点,因此快速讲解是笔者的风格,希望理解。
简单来说,变量其实就是属性(后续重点讲解);运算符其实用于计算,表达式由字面值、云算法和变量构成;数据类型很简单,跟Java一样,Python同样也是强类型的,不过在Python中定义一个变量,开发人员并不需要在变量标示符之前显式声明变量的类型(PS:不显式定义变量类型导致笔者曾经一度以为Python是弱类型,结果试了下10+“100”,运行期报错,OK,纠正下这个错误);数据结构简单来说就是数据的存储结构和存储方式。下面笔者使用一段简单的代码来汇总笔者本节提及过的所有知识点,如下所示:
#encoding=gbk
#Python的基本语法结构
userName="JohnGao"
age=28
sex=True
hobbys=["看书","写字","睡觉"]
print("我的名字->" + userName)
print("我的年纪->" + str(age))
print("我的性别->" + str(sex))
for hobby in hobbys:
print("我的爱好->"+hobby,end="\t")
上述程序示例中,将会按照笔者书写的顺序串行执行print输出。可以发现,在Python中,确实是大小写敏感的,boolean类型的值,True和False首字母是必须要大写;而笔者在输出int类型和boolean类型的2个变量时,使用了强转,因为Python的一条语句输出,只能是同一种数据类型,而不能够是多种(除非符号“,”分割)。关于笔者定义的线性表的数据结构来存储数据结果集,然后又使用for循环的方式将其迭代,关于这一点,笔者稍后会做出解释。
五、函数的使用
函数即方法。除了可以在代码中使用Python提供的缺省内置函数外,开发人员也可以编写自定义函数来实现程序的功能。当然在正式开始讲解如何在程序中编写一个自定义函数之前,我们首先来看看Python究竟带给了我们哪些惊喜?笔者示例几个比较常用的Python内置函数,如下所示:
#encoding=gbk
#求绝对值函数
print(abs(-100))
#强制转换函数
print(str(100))
print(int("200"))
print(float(2000))
print(bool(1))
#isinstance函数
print(isinstance(100,(int,float)))
上述程序示例中abs()函数的作用就是用于求绝对值,比如字面值-100的绝对值就是100;而强制转换函数的作用无非就是将一种数据类型转向另外一种数据类型,当然如果是float转向int,由于int无法存储小数,必然
精度会丢失;至于isinstance()函数其实就是类似于Java的instanceof()方法,目的就是检测当前类型是否跟目标类型一直,该函数除了可以作用于基本数据类型外,还支持引用类型。
当大家了解了Python的一些常用的缺省内置函数后,接下来我们再来学习如何在程序中编写自定义函数,以满足特定的程序功能。其实在Python中定义一个自定义函数非常简单,我们都知道在Java中定义一个方法无非就是使用void关键字或者返回值进行标示,而在Python中则是使用关键字def进行标示,如下所示:
def testMethod1():
print("一个简单的自定义函数")
#定义一个无任何操作的空函数
#pass关键字就是一个占位符
def testMethod2():
pass
上述代码示例中,方法是没有显式带有返回值的,那么如果希望方法具有返回值时应该怎么办呢?其实在Python中,开发人员无需显式的定义返回值类型,当一个函数执行完成后希望有返回值进行返回时,可以使用关键字return。在此大家需要注意,
如果一个函数内部并没有显式的通过return关键字指定有返回值时,Python缺省将会返回一个None值。如下所示:
def testMethod1():
value=100+1
return value
print(testMethod1())
大家是否曾想过Java方法能否支持
多返回值?很抱歉,目前Java语法层面并没有提供这种支持,不过在Java中就真的没有办法一次性返回多个参数吗?其实不然,当我们返回一个数组或者集合类型的时候其实就是间接返回了多个参数,基于这个想法,Python的函数可以友好的“支持”多返回值。如下所示:
def testMethod1():
value1=100+1
value2="userName->JohnGao"
return value1,value2
value1,value2=testMethod1()
print(value1,value2)
print(testMethod1())
其实Python所谓的多返回值,
无非就是返回一个数组类型。除了返回值之外,接下来我们再来看看如何定义函数参数以及函数的可变参数,如下所示:
#定义函数参数
def testMethod1(userName,age):
return userName,age
userName,age=testMethod1("JohnGao",28)
print(userName,age)
#定义可变参数
def testMethod1(*values):
for value in values:
print(value,end="\t")
testMethod1(100,200,300)
六、流程控制语句
流程控制语句其实光听名字都猜得出一个大概,无非就是
控制程序的执行流程。本小节笔者会重点为大家介绍如何使用Python编写if-else、if-else-if多路分支、for循环,以及while循环等语句。废话不多说,首先来看一个简单的示例,如下所示:
#if-else语句
value = 50
if value < 10:
pass
else:
pass
#if-else-if多路分支语句
userName=input("猜猜我的名字:\n")
if userName == "JohnGao":
pass
elif userName=="JohnGao1":
pass
else:
pass
#for循环语句
for i in range(10):
pass
value2=["1","2","3"]
for j in value2:
pass
#while循环语句
value3=0
while value3<10:
value3+=1
其他话就不多说了,相信大家都能够看懂笔者上述程序示例。既然都已经讲解到第6小节了,相信细心的读者已经发现了,Python和Java在语法层面上确实存在一些细微的差别,但是基本上有Java功底的开发人员都能够读懂和理解Python代码所想阐述的意思。不知大家是否还记得,读大学那会,你们的老师经常告诉你们一定要注意
编码规范,代码一定要
四格缩进,这样的代码
可读性才会更好,毕竟一个团队,项目的代码并不是你一个人在写。但是在Java中,代码的四格缩进仅仅只是一个可读性上面的
非硬性要求,哪怕你并不遵守,也不会影响程序
语义。
和Java恰恰相反,Python算是将四格缩进
发扬光大了,由于Python中代码块并没有使用符号“{}”进行概括,因此依靠四格缩进就算是Python语法的一种
隐式代码块的概括,大家在使用Python进行编码的时候一定要非常注意,否则你将会有意想不到的蛋疼问题等着你。
七、面向对象特性
面向对象的思想如今已经渗透到软件开发的
各个领域,例如:OOA(Object Oriented Analysis,面向对象的分析)、OOD(Object Oriented Design,面向对象的设计),以及开发人员时常挂在嘴边的OOP(Object Oriented Programming,面向对象的编程)。简单来说,面向对象的概念就是类和对象,而面向对象的特性就是封装、继承和多态。
总规一点,使用面向对象编程,最大的好处就是能够轻而易举的实现
代码复用。类是一个抽象的概念,所代表的含义其实就是某一类事物,比如动物这个就算是一个类;而对象就是类的一个具体实例。比如:老虎、狮子、大象等,在一个对象中,属性(即变量)代表了对象的各种
器官,而方法则代表了对象的一系列
行为。明白这一点后,我们再来看面向对象的3个特性,从封装开始,在开发过程中,如果有一些通用的控制逻辑,或者业务逻辑(统称为组件),我们是否需要将其封装在一个类中,然后在需要的时候调用即可,而不必翻来覆去的重复编写,因此类就是最基本的
封装单元。试想一下,既然通用性的组件封装好后,接下来的任务就是使用,采用继承的方式使用封装好的组件就是一个不错的方式,并且一旦继承后,面向对象的多态性则体现了出来。所谓的多态,大家千万不要只是简简单单的理解为方法的重载(override)和重写(overwrite),否则会显得非常肤浅。多态简单来说其实就是
晚期绑定的一种形式,既然发生在运行期,那么对象之间的引用必然就
不是编译期可知的静态链接,而是动态链接,因为无法在编译期确定下来的引用关系,则只能够在运行期进行绑定,比如Java中的
里氏替换原则就是一个很好的例子。
Python对面向对象的支持和其他高级编程语言一样,都是支持的非常完善。在程序中,定义一个类使用的是关键字class,如下所示:
class Animal(object):
pass
和Java一样,Python中所有类型的超类就是object。然而如果是显式继承其他超类的话,我们则可以在类名标示符的符号“()”定进行标注,如下所示:
#继承示例
class Animal(object):
pass
class Tiger(Animal):
pass
class Pig(Animal):
pass
接下来我们来看一个晚期绑定的例子,如下所示:
#晚期绑定
class Animal(object):
def getName(self):
pass
class Tiger(Animal):
def getName(self):
print("我的名字叫做Tiger")
class Pig(Animal):
def getName(self):
print("我的名字叫做Pig")
def getName(Animal):
print(Animal.getName())
#创建对象实例
animal = Tiger()
getName(animal)
上述程序示例中,笔者调用getName()方法时,由于在编译期根本无法确定所传递进来的参数究竟是Animal还是他的子类,因此也就意味着
编译期可变,自然也就无法使用前期绑定的方式。在Python中,为一个类型创建其对象实例并不需要像Java一样显式的使用关键字new,隐式的创建一个类的对象实例或多或少减少了开发人员的编码量。 在本小节的结尾处,笔者再跟大家浪费点口水阐述下Python的访问修饰符。在Java中,开发人员可以使用public、private或protected等关键字定义类成员的
可见性,但是在Python中,则可以使用符号“--”将其类成员定义为私有,而缺省就是public的,如下所示:
class Demo(object):
userName="张三"
__passWord="123456"
def getName(self):
pass
demo = Demo()
print(demo.userName)
#print(demo.passWord)
上述程序示例中,passWord变量的可见性仅限于Demo内部,而无法被外界
感知到。其实说了这么多,笔者似乎已经零零散散的介绍过Python的大部分语法了,但回想一下,既然变量都已经谈到了,那么常量是不是也要拉出来晒一晒?在Java中定义一个常量需要使用关键字final进行标示,然后标示符名称使用大写的形式标示所定义的字段是一个常量,而Python并不需要显式的使用final关键字进行标示,因为Python压根就
没有真正意义上的常量,仅仅只是一种规范性的
约定,约定什么呢?就是约定Python中所谓的常量标示符全部都使用大写,但是这个常量并非真正意义上的常量,值是可变的,因此Python中的常量即“
伪常量”。
八、I/O操作
I/O(Input/Output)技术,是最容易被大部分web开发人员所忽略的,其实I/O技术算得上是与开发人员打交道最
频繁的技术之一,哪怕你没有在程序中显式的使用I/O,你仍然也在不知不觉中
间接使用到了。比如当我们打开电脑的时候,需要从磁盘中读取操作系统的系统文件、打开浏览器上网时、QQ或者微信聊天时都间接或者直接的使用到了I/O技术。而在项目研发过程中,Tomcat中大量的I/O操作只是你自己浑然不知而已,所以了解并熟练掌握I/O技术的使用是每一个程序员
必备的技能之一。
向目标数据源读取数据:
向目标数据源写入数据:
那么什么是I/O 呢?所谓I/O 指的就是数据输入/输出的过程,我们称之为流(数据通信通道)这个概念。比如当Python应用程序需要读取目标数据源的数据时,则开启输入流。当需要写入时,则开启输出流。数据源可以是本地磁盘、内存或者是网络中的数据。Python语言定义了2 种类型的流:字节流(以byte 为单位读/写数据)和字符流(以char 为单位读/写数据)。字节流为处理字节数据的输入/输出提供了方便的方法,常用于读/写二进制数据。字符流则为处理字符数据的输入/输出提供了方便的方法。并且在某些情况下,使用字符流比使用字节流显得更为高效。
接下来笔者开始为大家演示如何使用I/O技术读取目标数据源的数据和向目标数据源写入数据(以字符为单位),如下所示:
#读取目标数据源的数据
try:
readValue=open("d:/test.txt","r")
#读取一行字符串
print(readValue.readline())
finally:
if readValue:
readValue.close()
#向目标数据源写入数据
try:
writeValue=open("d:/test2.txt","w")
#写入一行字符串
writeValue.write("test...")
finally:
if writeValue:
writeValue.close()
上述程序示例中,笔者使用的是readLine()函数每次读取目标数据源的一行字符串数据,但是如果有多行数据时应该怎么办呢?2个办法,那么使用read()函数一次性读完,要么循环迭代的方式进行读取,如下所示:
笔者在上述程序中所读/写的都是字符串数据,那么如果是二进制流呢?那就需要使用字节流的方式进行读取,如下所示:
#读取目标数据源的二进制数据流
readValue=open("d:/test.txt","rw")
#向目标数据源写入二进制数据流
writeValue=open("d:/test2.txt","w")
其实读/写二进制数据在Python中很简单,不像在Java中多得让人眼花缭乱的I/O组件数都数不过来,更不用谈记住了,
反观Python就一个open()函数,其内部指定一个目标数据源地址和操作方式就可以了。假设我们想实现一个文件复制粘贴的程序,除了使用Python提供的内置函数外,还可以利用手动的方式进行实现,如下所示:
#文件复制操作
def copy_method(file_path, save_path):
if not isinstance(file_path,(str)):
print("只支持所传递的参数为字符串")
else:
startTime=time.time()
with open(file_path,"rb") as read_value:
context = read_value.read()
print("数据全部读入完毕,数据大小为->" + str(len(context)/1024) + "KB")
with open(save_path,"wb") as write_value:
write_value.write(context)
print("数据写入完成...")
print("耗时->" + str((time.time() - startTime) * 1000) + "ms")
#"E:\\迅雷下载\\move.rmvb", "d:\\move.rmvb"
#copy_method("d:/fengtong.rar", "d:\\fengtong2.rar");
#E:\\迅雷下载\\move.rmvb
#文件复制操作2(适合大文件的读写)
def copy_method2(file_path, save_path):
if not isinstance(file_path,(str)):
print("只支持所传递的参数为字符串")
else:
try:
startTime=time.time()
write_value = open(save_path,"wb")
for read_value in open(file_path,"rb"):
write_value.write(read_value)
print("数据写入完成...")
print("耗时->" + str((time.time() - startTime) * 1000) + "ms")
finally:
if write_value:
write_value.close()
上述程序示例中,笔者使用了2种方式实现文件的复制粘贴操作,第一种方式其实适用于文件容量不大的情况,而第二种方式则适用于大文件的情况。如果是读写大文件,采用for line in open的方式无疑是最高效的,Python内部自建有
buffer缓冲区机制,不至于
一次性读爆内存。因此希望大家记住,如果有大文件操作的I/O操作时for line in open的方式必须优先。接下来笔者再演示一个程序,加深大家对I/O技术的掌握和理解,如下所示:
import os
def findFile(path):
#列出当前目录下的所有文件及文件夹
files = os.listdir(path)
for file in files:
if os.path.isfile(file):
print(file)
else:
os.chdir(os.path.abspath(file))
findFile(os.getcwd())
cwd=os.getcwd()
parent=""
for i in range(len(cwd.split("\\")) - 1):
parent+=cwd.split("\\")[i] + "\\"
#切换到上一级目录
os.chdir(parent)
filePath="D:\\test"
os.chdir(filePath)
findFile(filePath)
相信大家都已经注意到了,I/O资源在消费完成之后,必须将其关闭,如果不关闭或者忘记关闭,就会长期
霸占系统内部资源,极大程度上
系统的资
源分配。就像Java的内存管理一样,开发人员梦寐以求的就是希望有一天再也无需关注
繁琐的资源管理(资源创建、资源就绪、资源回收)。值得庆幸的是Python提供有类似Java7一样的自动资源管理机制(with open as value)。
九、线程操作
其实笔者写道这里,已经有顶乏力了,为了避免烂尾,笔者就不长篇大论了(今天最后一天上班,木有心情写了)。简单来说,多线程指的就是并发,当然并发跟并行的概念还是要区分下,并发是构建于单CPU上,而并行是构建于多CPU上的并发执行。因为我们知道多线程并不是真正意义上的多任务同时执行,而是CPU会不停的做任务切换,交叉运行,看起来貌似是一起执行(CPU切换平率快),但其实不是这样,只有并行才是真正意义上的多任务同时执行。
在Python中定义和使用线程很简单,Python的API提供了2个模块:thread和threading,threading对thread模块进行了封装。绝大多数情况下,我们只需要使用threading这个模块即可。启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行即可,如下所示:
def run():
for i in range(10):
print(i)
thread1=threading.Thread(target=run,name="线程A")
thread1.start()
#主线程继续执行
print("........")
既然谈到线程,不得不提及的还有锁机制,因为在并发环境下,多线程同时对一个资源进行操作,会造成非线程安全问题,因此Python也提供有锁机制,如下所示:
#获取锁
value="资源"
lock=threading.Lock()
def run():
try:
lock.acquire()
for i in range(10):
print(threading.current_thread().name,value)
finally:
lock.release()
thread1=threading.Thread(target=run,name="线程A")
thread1.start()
thread2=threading.Thread(target=run,name="线程B")
thread2.start()
上述程序示例中,多个线程持有同一把锁,只有当前一个前程使用完并释放锁,队列中的其他线程才能够正常的访问同一个资源,以此避免非线程安全问题。当然值得注意的,在Python中,锁的释放并非是自动的,而是需要开发人员手动显式的执行release()函数进行释放,所以大家千万要记得使用完之后一定要记得解锁,否则其他线程就会一直阻塞。
在并发场景下,使用锁可以有效的避免线程安全问题,但是这也同时造成了另外一个问题的出现,那就容易造成线程死锁,如下所示:
#encoding=gbk
import threading,time
resourceA="资源A"
resourceB="资源B"
#获取锁
lockA=threading.Lock()
lockB=threading.Lock()
def run1():
try:
lockA.acquire()
print("%s成功锁住"%threading.current_thread().name,resourceA)
print("%s准备锁住"%threading.current_thread().name,resourceB)
time.sleep(1)
lockB.acquire()
print("%s成功锁住"%threading.current_thread().name,resourceB)
finally:
lockB.release()
lockA.release()
def run2():
try:
lockB.acquire()
print("%s成功锁住"%threading.current_thread().name,resourceB)
print("%s准备锁住"%threading.current_thread().name,resourceA)
lockA.acquire()
print("%s成功锁住"%threading.current_thread().name,resourceA)
finally:
lockA.release()
lockB.release()
thread1=threading.Thread(target=run1,name="线程A")
thread1.start()
thread2=threading.Thread(target=run2,name="线程B")
thread2.start()
简单来说,就是A线程锁住A资源的时候,试图获取B锁,但是B线程已经抢先一步获取到B锁,这个时候A线程就必须等待,而B线程试图获取A锁时,发现A锁已经被A线程获取了,因此双方都在等待,这样一来就造成了永久等待,也就是线程死锁。
本章内容到此结束,由于时间仓库,本文或许有很多不尽人意的地方,希望各位能够理解和体谅。最后祝愿大家,在新的一年事事顺心,万事如意,羊年行大运。