selenium + python实现截图并且保存图片的方法
在自动化测试过程中,是有必要截图的,特别是遇到错误的时候进行截图,截图可以帮助我们直观的定位错误、记录测试步骤。。截图对于测试人员来说应该是较为重要的一个技能。
webdriver的截图功能十分强悍,无论页面多长,webdriver都能比较完美的截到完整的页面。
Webdriver自带截图功能:
(1)get_screenshot_as_file()
该方式很简单,通过driver获取该方法,将截图要保存的路径写入就好,
(2)save_screenshot(),与get_screenshot_as_file()方式一样,使用起来都很简单
看以下实例,打开csdn首页进行截图
# -*- coding: utf-8 -*-
from selenium import webdriver
import unittest
import os,sys,time
from pathlib import Path
#初始化实例
driver = webdriver.Chrome()
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
current_time1 = time.strftime("%Y-%m-%d", time.localtime(time.time()))
print(current_time )
print(current_time1 )
#设置存储图片路径,测试结果图片可以按照每天进行区分
#通过if进行断言判断
driver.get("https://www.csdn.net/")
#新创建路径“.”表示当前整个.py文件的路径所在的位置,“\\”路径分割符,其中的一个是"\"转义符
pfilename = u'.\\image'
pic_path = pfilename+ '\\' + current_time1 + '_' + current_time + '.png'
#判断文件夹是否存在,不存在就新建一个新的
if Path(pfilename).is_dir():
pass
else:
Path(pfilename).mkdir()
print(pic_path)
time.sleep(2)
print(driver.title)
#截取当前url页面的图片,并且将截取的图片保存在指定的路径(pic_path)
driver.save_screenshot(pic_path)
if u'CSDN-专业IT技术社区' == driver.title:
print('Assertion test pass')
else:
print('Assertion test fail')
driver.quit()
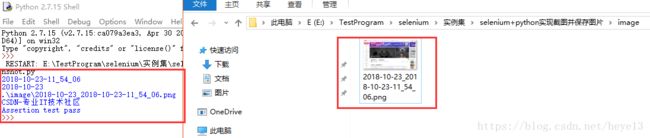
运行的结果如下
2、解决打开一个网站,出现的图片加载不完全的问题。好在selenium支持javascript,我们可以在截图之前先运行一个javascript脚本,先滚动页面的滚动条,然后再回到顶部再去截图。
#-*- coding:utf-8 -*-
from selenium import webdriver
import time
from pathlib import Path
def take_screenshot(url):
browser = webdriver.Chrome()
browser.maximize_window()
browser.get(url) # Load page
browser.execute_script("""
(function () {
var y = 0;
var step = 100;
window.scroll(0, 0);
function f() {
if (y < document.body.scrollHeight) {
y += step;
window.scroll(0, y);
setTimeout(f, 100);
} else {
window.scroll(0, 0);
document.title += "scroll-done";
}
}
setTimeout(f, 1000);
})();
""")
for i in xrange(30):
if "scroll-done" in browser.title:
break
time.sleep(10)
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
#新创建路径“.”表示当前整个.py文件的路径所在的位置,“\\”路径分割符,其中的一个是"\"转义符
pfilename = u'.\\image'
pic_path = pfilename+ '\\' + current_time + '.png'
#判断文件夹是否存在,不存在就新建一个新的
if Path(pfilename).is_dir():
pass
else:
Path(pfilename).mkdir()
print(pic_path)
time.sleep(2)
browser.save_screenshot(pic_path)
browser.close()
if __name__ == "__main__":
take_screenshot("http://codingpy.com")3、截取页面的某个元素实现方法:
(1)先去截图一张全屏大图
(2)再定位元素,获取其地址和宽高,进行截取
#-*- coding:utf-8 -*-
from selenium import webdriver
from time import sleep
import time
from PIL import Image
#实现思路
#1、截取元素位置、大小
#2、获取元素位置、大小
#3、截取元素图片并保存
#时间格式进行格式化
def time_format():
current_time = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
return current_time
#区域截图(对指定的区域/元素截图)
def element_screenshot(element):
#截取全屏图片
driver.save_screenshot(".\\image\\full.png")
#获取element的顶点坐标
x_Piont = element.location['x']
y_Piont = element.location['y']
#获取element的宽、高
element_width = x_Piont + element.size['width']
element_height = y_Piont + element.size['height']
picture = Image.open(".\\image\\full.png")
picture = picture.crop((x_Piont, y_Piont, element_width, element_height))
'''
去掉截图下端的空白区域
'''
driver.execute_script(
"""
$('#main').siblings().remove();
$('#aside__wrapper').siblings().remove();
$('.ui.sticky').siblings().remove();
$('.follow-me').siblings().remove();
$('img.ui.image').siblings().remove();
"""
)
picture.save(".\\image" + time_format() + ".png")
driver = webdriver.Chrome()
driver.get("http://www.baidu.com/")
driver.maximize_window()
#要截取的目标元素
element = driver.find_element_by_id("su")
#调用element_screenshot()方法
element_screenshot(element)
sleep(2)
driver.quit()4、截取长图的方法。百度上很多教程有说到使用WebDriver.PhantomJS自带的方法支持对整个网页截屏,但是新版的selenium已经去掉了PhantomJS,也有一个解决方案,但是并没有实现截取长图,下面的代码找到了替代PhantomJS的方案,但是运行起来没有截取长图,具体原因还有待研究。
#-*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from pathlib import Path
def take_screenshot(url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(executable_path='C:\\Python27\\chromedriver', chrome_options=chrome_options)
browser.maximize_window()
browser.get(url) # Load page
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
#新创建路径“.”表示当前整个.py文件的路径所在的位置,“\\”路径分割符,其中的一个是"\"转义符
pfilename = u'.\\image'
pic_path = pfilename+ '\\' + current_time + '.png'
#判断文件夹是否存在,不存在就新建一个新的
if Path(pfilename).is_dir():
pass
else:
Path(pfilename).mkdir()
print(pic_path)
time.sleep(2)
browser.save_screenshot(pic_path)
browser.close()
if __name__ == "__main__":
take_screenshot("http://codingpy.com")