《SQL反模式》第三章 单纯的树
树就是树,你还需要考虑什么吗? 罗纳德.里根

我们看个贴吧的例子,吧友们可以一起讨论一个主题,又可以互相评论,怎么存储这些评论信息呢?
第一版:
create table comment(
comment_id serial primary key,
parent_id bigint unsigned,
bug_id bigint unsigned not null,
author bigint unsigned not null,
comment text not null,
foreign key (parent_id) refenences comment(comment_id )
);
这样会有一个问题,如何遍历给定主题的所有评论?层级可以无限深的评论,1-2-3-4-5-6......,这注定是一个耗时的过程。
一、问题分析:
下面引用下书中的例子(范例数据):


问题1:
对于上面的示例数据,如何查询一个节点的说有后代呢?
方法一:关联查询
关联两层数据:
select a.*,b.* from comment a left join comment b on a.comment_id = b.parent_id ; // 只能获取两层数据
关联四层数据:
select a.*,b.*,c.*,d.* from comment a
left join comment b on a.comment_id = b.parent_id
left join comment c on b.comment_id = c.parent_id
left joni comment d on c.comment_id = d.parent_id;
这里有一个问题,SQL查询的关联次数是有限制的,不能无限关联。。。,如果需要关联100层或者1000层,就无能为力了。
方法二:查询出所有行,在构造成树
select * from comment where bug_id = '1';
如果我们需要的不是完整的树,只是其中的某个评论子树,这种方法就不行了,再者,如果数据量很大,就涉及到大量的数据复制到内存去构造树形数据,就会非常低效。
问题2:
对于上面的示例数据,如何删除一个非叶子节点?
方法:
首先要修改子节点的parent_id,然后才能删除
1、先查找要删除节点的父节点
select parent_id from comment where comment_id = 6;
// 返回4;
2、更新comment_id为6的所有子节点的父节点,之前为6,现在都要改成4
update comment set parent_id = 4 where parent_id = 6;
3、删除非叶子节点
delete from comment where comment_id = 6;
过程是比较麻烦的。
优势1:
插入数据很方便,也可以很容易的获取一个节点的直接父节点。
如果你的应用程序只涉及到插入和获取父节点,这是一种很好的实现方式。
二、问题解决
方法1:路径枚举
路径枚举就是将祖先信息合成一个字符串,像下面一样。

获取comment_id = 7的祖先
select * from comment c where '1/4/6/7' like c.path || '%';
这个查询语句就会匹配到‘1/4/6’、‘1/4’、‘1/’
查询comment_id = 4的所有后代
select * from comment c where c.path like '1/4/' || %';
这句查询语句就会匹配到‘1/4/5’、‘1/4/6’,‘1/4/6/7’
缺点:
因为路径的长度我们不好控制,就会引入我们第二章讲的《SQL反模式》第二章 乱穿马路问题。
方法二:嵌套集
嵌套集就是使用两个数字定位一个节点

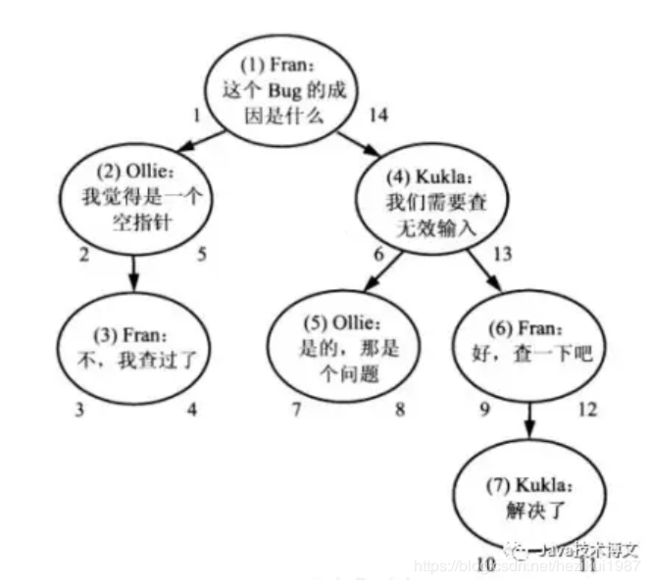
这是一个先序遍历的二叉树。
搜索comment_id = 4的所有后代
select c2.* from comment as c1 join comment as c2 on c2.nleft between c1.nleft and c1.nright where c1.comment_id = 4;
搜索comment_id = 4的所有祖先
select c2.* from comment as c1 join comment as c2 on c1.nleft between c2.nleft and c2.nright where c1.comment_id = 4;
方法三:闭包表
闭包表的实现方式是,额外创建一张TreePaths的表,这个表包含两列,祖先和后代,并且每一列都是指向comment中comment_id的外键。

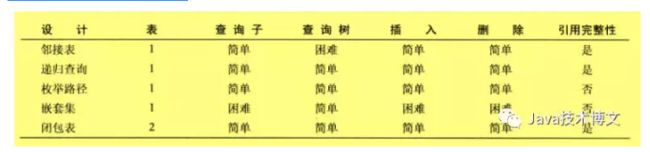
三、你该使用哪种设计?
-
邻接表设计比较简单,很多软件设计都使用了它。
-
枚举路径可能会引入“乱穿马路”问题
-
嵌套集查询树会比较简单
-
闭包集是推荐的用法,但是需要额外增加一张表,属于以空间换时间。
