Hadoop的分布式架构改进与应用
Hadoop的分布式架构改进与应用
Baofeng Zhang@zju
转载请注明出处:http://blog.csdn.net/zbf8441372
1. 背景介绍
谈到分布式系统,就不得不提到Google的三驾马车:GFS[1],MapReduce[2]和BigTable[3]。虽然Google没有开源这三个技术的实现源码,但是基于这三篇开源文档, Nutch项目子项目之一的Yahoo资助的Hadoop分别实现了三个强有力的开源产品:HDFS,MapReduce和HBase。在大数据时代的背景下,许多公司都开始采用Hadoop作为底层分布式系统,而Hadoop的开源社区日益活跃,Hadoop家族不断发展壮大,已成为IT届最炙手可热的产品。
本文将在简单介绍Hadoop主要成员的基础上,探讨Hadoop在应用中的改进。
第一部分是对Hadoop诞生和现状的简单描述。
第二部分将简单介绍hadoop的主要成员,主要包括他们的基本特性和优势。分别是分布式文件系统HDFS,NoSQL家族之一的HBase,分布式并行编程方式MapReduce以及分布式协调器Zookeeper。
第三、四、五部分分别介绍了Hadoop的不同改进和使用。按次序分别是facebook的实时化改进,HadoopDB,以及CoHadoop。
最后是我的总结和体会。
如果对Hadoop的基本架构和基础知识熟悉,可以从第三部分看起。
2. 关于Hadoop
Hadoop本身起源于Apache Nutch项目,曾也是Lucene项目的一部分。从结构化数据,到半结构化数据和非结构化数据,从关系型数据库到非结构化数据库(NoSQL),更高性能的并行计算/批处理能力和海量数据存储成为现代主流IT公司的一致需求。
2.1 HDFS
HDFS,全称Hadoop Distributed Filesystem,是Hadoop生态圈的分布式文件系统。分布式文件系统跨多台计算机存储文件,该系统架构于网络之上,诞生即具备了网络编程的复杂性,比普通磁盘文件系统更加复杂。
2.1.1 HDFS数据块
HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。数据集通常由数据源生成或从数据源复制而来,接着长时间在此数据集上进行格类分析处理。每次都将涉及该数据集的大部分数据甚至全部,因此读取整个数据集的时间延迟比读取第一条记录时间的延迟更重要。而一次写入、多次读取是最高效的访问模式。有一点要说明的是,HDFS是为高数据吞吐量应用优化的,而这可能会以高时间延迟为代价。
HDFS默认的最基本的存储单元是64M的数据块(block)。HDFS的块比磁盘块(512字节)大得多,目的是为了最小化寻址开销。HDFS上的文件也被划分为多个分块(chunk),作为独立存储单元。与其他文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。
块抽象给分布式文件系统带来的好处:
Ø 文件的大小可以大于网络中任意一个磁盘的容量。
Ø 使用块抽象而非整个文件作为存储单元,大大简化了存储子系统的设计,同时也消除了对元数据的顾虑。
Ø 块非常适合用于数据备份进而提供数据容错能力和可用性。
2.1.2 Namenode和Datanode
namenode和datanode的管理者-工作者模式有点类似主从架构。namenode对应多个datanode。namenode管理文件系统的命名空间,维护文件系统和内部的文件及目录。datanode是文件系统的真正工作节点,根据需要存储并检索数据块(一般受namenode调度),并且定期向namenode发送它们所存储的块的列表。
namenode一旦挂掉,文件系统的所有文件就丢失了,不知道如何根据datanode的块来重建文件。因此,namenode的容错或者备份是很重要的。在HDFS中存在secondarynamenode(虽然不完全是个namenode的备份,更确切的是个辅助节点)周期性将元数据节点的命名控件镜像文件和修改日志合并。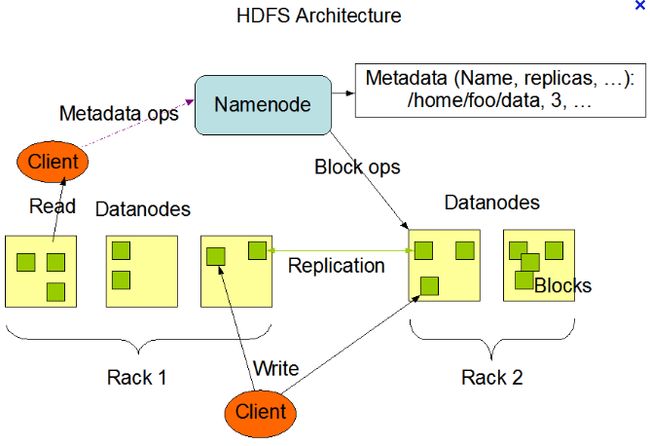
2.2 HBase
跟传统的关系型数据库(RDBMS)基于行存储不同,HBase是一个分布式的,在HDFS上开发的面向列的分布式数据库。HBase行中的列分成“列族”(column family),所有的列族成员有相同的前缀。所有列族成员都一起存放在文件系统中。
2.2.1 与RDBMS比较
HBase通过在HDFS上提供随机读写来解决Hadoop不能处理的问题。HBase自底层设计开始即聚焦于各种可伸缩性问题:表可以很“高”,有数十亿个数据行;也可以很“宽”,有数百万个列;水平分区并在上千个普通商用机节点上自动复制。表的模式是物理存储的直接反映,使系统有可能提高高效的数据结构的序列化、存储和检索。
而RDBMS是模式固定、面向行的数据库且具有ACID性质和复杂的SQL查询处理引擎,强调事物的强一致性(strong consistency)、参照完整性(referential integrity)、数据抽象与物理存储层相对独立,以及基于SQL语言的复杂查询支持。
2.2.2 HBase特性
简单列举下HBase的关键特性。
Ø 没有真正的索引:行是顺序存储的,每行中的列也是,所以不存在索引膨胀的问题,而且插入性能和表的大小有关。
Ø 自动分区:在表增长的时候,表会自动分裂成区域(region),并分布到可用的节点上。
Ø 线性扩展:对于新增加的节点,区域自动重新进行平衡,负载会均匀分布。
Ø 容错:大量的节点意味着每个节点重要性并不突出,所以不用担心节点失效问题。
Ø 批处理:与MapReduce的集成可以全并行地进行分布式作业。
2.3 MapReduce
MapReduce是一种可用于数据处理的编程模型,是一个简单易用的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
2.3.1 Map & Reduce
一个Map/Reduce 作业(job)通常会把输入的数据集切分为若干独立的数据块,由 map任务以完全并行的方式处理它们。框架会对map的输出先进行排序,然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统(一般为HDFS)中。整个框架负责任务的调度和监控(jobtracker协调作业的运作,tasktracker运行作业划分后的任务),以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
2.3.2 Matser/Slave架构
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(jobconfiguration)。然后,Hadoop的 job client提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给job-client。
2.4 Zookeeper
Zookeeper是一个高可用的分布式数据管理与系统协调框架。简单的说,就是个分布式协调器。它以主从的架构,基于Paxos算法实现,保证了分布式环境中数据的强一致性,也因此各种分布式开源项目中都有它的身影。
2.4.1 Zookeeper机制
Zookeeper的核心是一个精简的文件系统,它的原语操作是一组丰富的构件(building block),可用于实现很多协调数据结构和协议,包括分布式队列、分布式锁和一组同级节点中的“领导者选举”(leader election)。
Zookeeper实现的是Paxos算法。Zookeeper集群启动后自动进行leader selection,投票选出一台机器作为Leader,其他的都是Follower。通过heartbeat的机制,Follower从Leader获取命令或者消息,同步自己的数据,和Leader保持一致。为了保证数据的一致性,只有当半数以上的Follower的状态和Leader成功同步了之后,才认为这次数据更新是成功的。为了选举方便,Zookeeper集群数目是奇数。
3. Hadoop在Facebook变得实时[4]
论文主要解释了Facebook引进Hadoop的原因。结合自己的需求,Facebook对hadoop进行了更实时的改进。
3.1 HDFS与MySQL的性能互补
HDFS适合大块地读取数据(推荐节点是64M),它关于随机读取的工作的accesslatency比较大,所以一般会用大规模的MySQL集群结合memcached这样的缓存工具来做处理。在Facebook中,从Hadoop中产生的类似中间结果的数据会装载到MySQL集群或者memcached中去,用来被web层使用。
同时,HDFS的顺序读取性能很好。Facebook需求写方面的高吞吐量,代价低的弹性存储,同时要求低延迟和硬盘上高效的顺序和随机读取。MySQL存储引擎被证明有比较高的随机读取能力,但是随机写吞吐率比较差。因此,Facebook决定采用Hadoop和HBase来平衡顺序和随机读取的性能,而不是只采用MySQL集群来不断尝试一种难以把握的balance。具体Facebook的需求将在下一节仔细剖析。
3.2Facebook需求
Facebook认为,用他们已有的基于MySQL集群的一些解决方案来处理问题已经遇到了瓶颈。之前的用例对工作量的扩展是有挑战性的。在一个RDBMS的环境下解决非常高的写吞吐量,大数据,不可预测增长及其他问题变得十分困难。
3.3 选择Hadoop和HBase原因
采用Hadoop和HBase来解决以上需求的存储系统方案的原因可以总结为以下几点:
Ø 弹性:需要能够用最小的开销和零宕机修复时间来对存储系统增量式地扩容。这里的扩容应该指的是可以比较方便地实时增加服务器台数来应对一些高峰或者突发服务需求。
Ø 高的写吞吐量
Ø 高效的硬盘随机读写
Ø 高可用性和容灾
Ø 错误隔离:当局部数据库挂掉或者服务器不能提供服务的时候,让最少的用户受到影响。HDFS应对这样的场景还是很不错的。
Ø 读写改的原子性:底层存储系统针对高并发量的需求
Ø 范围扫描:指特定场景下高效获取一个范围结果集。
HBase已经以key-value存储的方式提供了高一致性的高写吞吐,且在大规模数据传送和快速随机写以及流式读方面表现优异。它同时保证了行层次的原子性。从数据模型的角度看,面向列的实现给数据存储带来了极高的灵活性,“宽”行允许在一个table内存放百万数量级的被索引的值。
虽然HDFS的核心namenode的宕机会带来巨大影响,但是Facebook有信心打造一个在合理时限内的高可用的NameNode。根据一些实践测试,Facebook对HDFS进行了设计和改进,主要针对namenode。将在下节展开。
3.4 实时HDFS
HDFS刚开始是为了支持MapReduce这样的并行应用的数据存取的,是面向批处理系统的,所以在实时方面讲本身可能是存在不足的。Facebook主要改造在于一个高可用的AvatarNode。
我们知道HDFS的namenode一旦挂掉,整个集群就得等到namenode再次启动才能继续运行提供服务,所以需要这个热备份——AvatarNode的设计。在HDFS启动的时候,namenode是从一个叫fsimage的文件里读取文件系统的元数据的。元数据信息包括了HDFS上所有文件和目录的名字和元数据。但是namenode不会持续地去存每一块block的位置信息。所以冷启动namenode的时候包括两部分:首先读文件系统镜像;然后,大部分datanode汇报进程上的block信息,以此来恢复集群上每一块已知block的位置信息。这样的冷启动会花很长时间。
虽然一个备用的可用node可以避免failover时候去读磁盘上的fsimage,但是依然需要从datanodes里获取block信息。所以,时间相对还是偏长。于是诞生了AvatarNode。
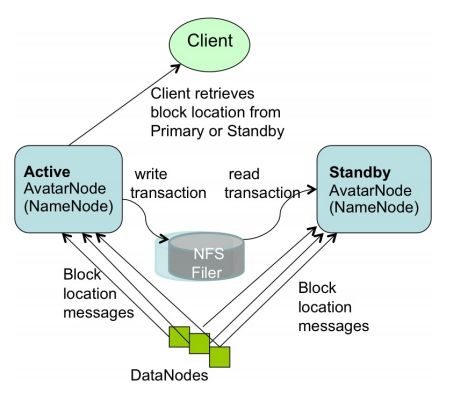
如图所示。HDFS拥有两个AvatarNode——Active AvatarNode和Standby AvatarNode。他们形成了一对“主被动热备份”(active-passive-hot-standby)。AvatarNode是对NameNode的包装。Facebook的HDFS集群都采用NFS来存一份文件系统镜像的备份和一份事物日志的备份。Active AvatarNode把自己处理的事务写进NFS里的事务日志。同时,StandbyAvatarNode打开NFS上同一份事务日志,然后在自己的命名空间内开始执行事务,以保证自己的命名空间尽可能和初始信息接近。Standby AvatarNode同时照顾到初始信息的核查并创建新的文件系统镜像,和HDFS相比就没有了分离的SecondNameNode。
Datanodes同时和两个AvatarNode交流。这保证了Standby处也获得到最新的block状态信息,以在分钟时间级内转化成为Activer的Node(之前说namenode的冷启动的时长问题可以解决了)。Avatar DataNode相互之间输送心跳,block信息汇报和接受到的block。Avatar DataNodes集成了Zookeeper,因此他们知道主节点信息,会执行主节点发送的复制/删除命令(基于Zookeeper的leader selection和heartbeat机制),而来自Standby AvatarNode的复制/删除请求是忽略的。
对于事务日志的记录,还进行了一些改进。
i. 为了让故障和失效尽可能透明,Standby必须知道失效发生时的block位置信息,所以对每一块block分配记录一个额外的记录日志。这样允许客户端在发生失效的时刻前还是一直在写文件。
ii. 当Standby向正在被Active写事务记录的日志里读取事务信息的时候,有可能读到的是一个局部的事务。为了避免这样的问题,给每个要写进日志里的事务增加记录事务长度信息,事务id和校验和。
要了解更具体的信息,可以从原paper中获得更多具体的情况。
4. HadoopDB[6]
HadoopDB简单介绍下设计理念和他的架构。
4.1 HadoopDB理念
HadoopDB是一个混合系统。基本思想是用MapReduce作为与正在运行着单节点DBMS实例的多样化节点的通信层。查询语言用SQL表示,并用现有工具翻译成MapReduce可以接受的语言,使得尽可能多的任务可以被推送到每个高性能的单节点数据库上。这样基于MapReduce的并行化的数据库代价几乎是零。因为MapReduce是现有的。
HadoopDB背后的一些主要思想包括以下两个关键字:share-nothing MPP架构和parallel databases。
4.2 HadoopDB架构介绍
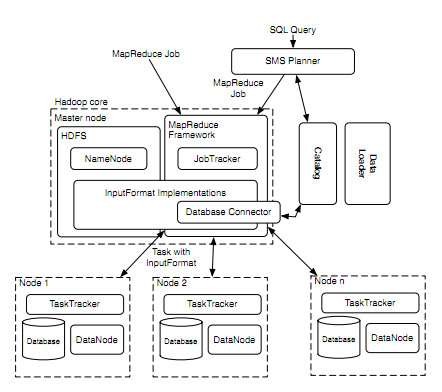
作为一个混合的系统,让我们看看HadoopDB由哪些部分构成:HDFS,MapReduce,SMS Planner,DB Connector等等。HadoopDB的核心框架还是Hadoop,具体就是存储层HDFS,和处理层MapReduce。关于HDFS上namenode,datanode各自处理任务,数据备份存储机制以及MapReduce内master-slave架构,jobtracker和tasktracker各自的工作机制和任务负载分配,数据本地化特性等内容就不详细说了。下面对主要构成部件做简单介绍:
1. Databae Connector:承担的是node上独立数据库系统和TaskTracker之间的接口。图中可以看到每个single的数据库都关联一个datanode和一个tasktracker。他传输SQL语句,得到一些KV返回值。扩展了Hadoop的InputFormat,使得与MapReduce框架实现无缝拼接。
2. Catalog:维持数据库的元数据信息。包括两部分:数据库的连接参数和元数据,如集群中的数据集,复本位置,数据分区属性。现在是以XML来记录这些元数据信息的。由JobTracker和TaskTracker在必要的时候来获取相应信息。
3. Data Loader:主要职责涉及根据给定的分区key来装载数据,对数据进行分区。包含自身两个主要Hasher:Global Hasher和Local Hasher。简单地说,Hasher无非是为了让分区更加均衡。
4. SMS Planner:SMS是SQL to MapReduce to SQL的缩写。HadoopDB通过使他们能执行SQL请求来提供一个并行化数据库前端做数据处理。SMS是扩展了Hive。关于Hive我在这里不展开介绍了。总之是关于一种融入到MapReduce job内的SQL的变种语言,来连接HDFS内存放文件的table。可以贴个图看下。不详细说了。

5. CoHadoop[7]
论文提出CoHadoop来解决Hadoop无法把相关的数据定位到同一个node集合下的性能瓶颈。CoHadoop是对Hadoop的一个轻量级扩展,目的是允许应用层能控制数据的存储。应用层通过某种方式提示CoHadoop某些集合里的文件是相关性比较大的,可能需要合并,之后CoHadoop就尝试去转移这些文件以提高一定的数据读取效率。
5.1 研究意义
Hadoop++[6]项目其实也做过类似的事,它将同一个job产生的两个file共同放置,但是当有新文件注入系统的时候,它需要对数据重新组织。
CoHadoop的改进主要给以下几个操作带来了比较大的好处:索引(indexing),聚合(grouping),聚集(aggregation),纵向存储(columnar storage),合并(join)以及sessionization。而像日志分析这样的操作,涉及到的就是把一些参考数据合并起来或者进行sessionization。这可以体现CoHadoop的改进意义所在。
以下是paper关于CoHadoop的总结:
Ø 这是一种很灵活,动态,轻量级的共置相关数据文件的方案,而且是直接在HDFS上实现的。
Ø 在日志处理方面,确定了两个用例:join和sessionization,使得在查询处理方面得到了显著的性能提高。
Ø 作者还研究了CoHadoop的容错,分布式数据和数据丢失。
Ø 在不同的场景下测试了join和sessionization的效果。
接下来还是介绍下CoHadoop的设计思想。
5.2 改进设计介绍
HDFS本身存数据的时候是有冗余的。默认是存三分拷贝。这三份复制品会存在不同的地方。最简单是存在datanode里。默认的存放方式是第一份拷贝存在新建的本地诞生的node的block里(假设足够存),这叫写“亲和”(write affinity)。HDFS然后选择同一机架上的datanode存放第二个拷贝,选择不同机架上的一个datanode存第三份拷贝。这是HDFS的本来的机制。那么为了实现相关数据的共置存储,论文修改了存放策略。
以上Hadoop现有的存放策略主要是为了负载均衡,但是当应用需要从不同的文件里去取所需的数据的时候,如果能自定义一些策略,那可能会得到显著的提升。轻量级的CoHadoop使得开发自定义的策略变得简单。虽然分区在Hadoop里实现很简单,但是共置并不容易,Hadoop也没有提供这样类似的可行性功能实现。
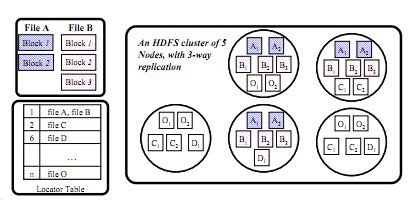
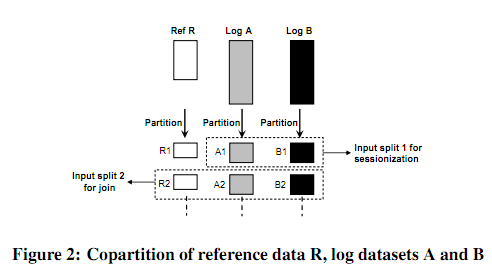
如图是CoHadoop的数据存放示意图。CoHadoop扩展了HDFS,提出了新的文件层属性——locator,并且修改了Hadoop的数据存放策略以使用这个locator。假设每个locator由一个整数值表示(也可以是别的表示方法),那么文件和locator之间可以是一个N:1的关系。每个HDFS的文件最多和一个locator关联,同一个locator可以关联很多文件。同一个locator下的文件存在同一个datanode集合里,而没有locator映射的文件依旧按照默认的Hadoop的存储机制存放。图中的A和B就属于同一个locator,A文件的两块block和B文件的三块Block结果存在了同一个datanode集合里。
为了更好地管理和跟踪这些locator和文件之间的映射信息,设计了一个新的数据结构——locatortable存在namenode里。它存放了每个locator映射的文件集。图中也可以看到。当namenode运行的时候,locator table是在内存里动态维护的,
关于数据存放策略的修改是这么做的:只要有一个新的和locator l关联的文件f被创建,会去locator table里查询是否存在一个实例是属于这个locator l的。如果不存在,就新增一条(l, f)在table里,并用HDFS默认的存放方式存这份文件的拷贝们。如果已经存在,就可以知道这个l映射的file list,如果从现有的存放了这个list内的文件的r个datanode里按一定方式(考虑空间)选出几个用于存新来的文件的拷贝的节点,存放这份文件的拷贝们。大致的意思就是这样。
关于日志的join和sessionization的改进,就不展开了。简单贴两个图。

做sessionization,对于日志处理时候MapReduce计算的影响比较。
6. 总结
虽然我对Hadoop有浓厚的兴趣,但是自己所能接触到的项目和环境,都没有到达一个比较饱和的需求点。要做分布式存储?根本用不着动用HBase或者别的NoSQL组成的分布式集群,只需要一个分布式的MySQL集群就可以了,NoSQL可以做的事,其实MySQL何尝不能完成?只是说NoSQL对某些数据的存储,在某些读写性能上有局部的个性化的优势而已。更不必说要用MapReduce去完成什么样大规模,TB级数据的分布式并行计算了。在数据和硬件设施方面,以至到技术程度方面,学校里都没有满足条件,没有如此的需求。
学校的课程里也没有涉及到分布式的内容。分布式文件系统/存储/索引之类的话题一直是存在于企业级别,存在于大公司大数据基础和服务器集群基础的。学校里偶尔可以听到如阿里开的关于分布式的讲座,也是很基础的,浅尝截止。
出生在什么样的年代,就会接触什么样的技术。学习什么样的技术,就能充实自己成什么样的技术人才。把握Hadoop,把握时代的核心技术,就掌握了现在大数据时代,甚至可以遇见并操控未来!
7. 参考文献和资料
[1] S. Ghemawat,H. Gobioff, and S.-T. Leung, “The google file system,” SIGOPS Oper. Syst. Rev.,vol. 37, no. 5, pp. 29–43, 2003.
[2] J. Dean and S.Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In OSDI,2004.
[3] Bigtable: ADistributed Storage System for Structured Data. In OSDI, 2006.
[4] Apache HadoopGoes Realtime at Facebook. In SIGMOD, 2011.
[5] A. Abouzeidand et al. HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologiesfor Analytical Workloads. In VLDB, 2009.
[6] J. Dittrich etal. Hadoop++: Making a yellow elephant run like a cheetah (without it evennoticing). In VLDB, 2010.
[7] CoHadoop: Flexible Data Placementand Its Exploitation in Hadoop. In VLDB, 2011.