Scrapy入门
注意: Python版本需要为2.7
丛书编者按:Scrapy由 Python 编写。如果刚接触并且好奇这门语言的特性以及Scrapy的详情, 对于已经熟悉其他语言并且想快速学习Python的编程老手, Learn Python The Hard Way , 对于想从Python开始学习的编程新手, 非程序员的Python学习资料列表 将是您的选择。
1.定义Item爬取模型
首先根据需要从dmoz.org获取到的数据对item进行建模。 我们需要从dmoz中获取名字,url,以及网站的描述。 对此,在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
# Creator yuluoxinsheng
import scrapy
class WikiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
2.编写第一个爬虫(Spider)
为了创建一个Spider,必须继承 scrapy.Spider
类, 且定义以下三个属性:
name
: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字
allowed_domains :
代表允许执行的url范围,通常以http请求字段的orion url为基准
start_urls
: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse()
是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response
对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request
对象。
import scrapy
class WikiSpider(scrapy.Spider):
name = "wiki"
allowed_domains = ["domz.org"]
start_urls = [
"http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/",
"http://www.dmoztools.net/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename,'wb') as f:
f.write(response.body)
3.创建wikipedia scrapy
> scrapy startproject wiki
console output

又遇到了windows的环境变量问题,题主也是无奈,尝试解决方法
成功解决:

爬取 (crawl)
Using the scrapy tool
Scrapy X.Y - no active project
Usage:
scrapy[options] [args]
Available commands:
crawl Run a spider
fetch Fetch a URL using the Scrapy downloader
[...]
进入项目的根目录(题主的目录为e:\Spider\wiki),执行下列命令启动spider:
> scrapy crawl wiki
console output


查看包含 [wiki] 的输出,输出的log中包含定义在 start_urls 的初始URL,并且与spider中是一一对应的。可以看到发出的get请求指向我们创建的两条链接,除此之外没有指向其他页面
4.Spider解析数据:
1.Scrapy为Spider的 start_urls属性中的每个URL创建了 scrapy.Request
对象,并将 parse 方法作为回调函数 (callback)赋值给了Request。
2.Request对象经过调度,执行生成 scrapy.http.Response
对象并送回给spider parse()
方法。
进入项目的根目录,执行下列命令来启动shell用来加载解析的页面数据:
> scrapy shell "http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/"
当shell载入后,将得到一个包含response数据的本地 response 变量。我们之前在parse函数中写入的response,body。shell显示的就是从domz爬取得body信息
console output
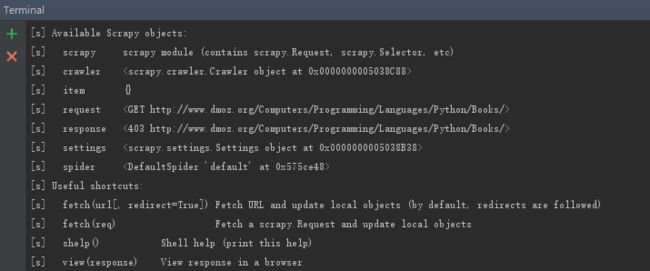
但这样解析出的数据某些不符合我们的需求,比如我们只要求回调/Languages的资源地址。而当输入 response.selector 时, 获取到一个可以用于查询返回数据的selector(选择器), 以及映射到 response.selector.xpath() 、 response.selector.css() 的 快捷方法(shortcut): response.xpath() 和 response.css() 。
selector根据response的类型自动选择最合适的分析规则(XML vs HTML)。
5.以Domz为例,老样子解析页面结构
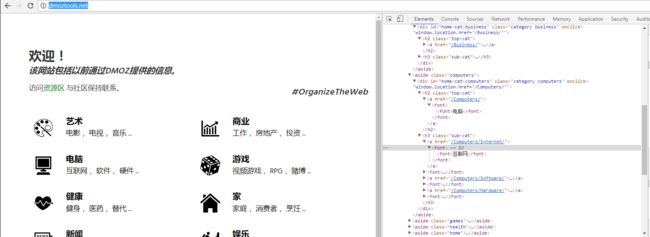
标签层次调用如下:
title aside->div->h2->a->font
link aside->div->h2->a href
desc aside->div->h3->a->font
更改Spider\WikiSpider,由于Domz网站域名更新,修改url
import scrapy
from wikiSpider.items import WikispiderItem
class WikiSpider(scrapy.Spider):
name = "wiki"
allowed_domains = ["dmoztools.net"]
start_urls = [
"http://dmoztools.net/Computers/Programming/Languages/Python/Books/",
"http://dmoztools.net/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
item = WikispiderItem()
content = response.xpath('//section/aside/div/text()')
print content
for sel in response.xpath('//section/aside/div'):
item['title'] = sel.xpath('h2/a/text()')
item['link'] = sel.xpath('h2/a/@href')
item['desc'] = sel.xpath('h3/a/text()')
return item
命令重启动spider:
> scrapy crawl wiki
console output :Error:xpath无法解析路径

Python console
启动shell,解析Books页面
scrapy shell http://dmoztools.net/Computers/Programming/Languages/Python/Books/
6.测试xpath获取页面各个标签值
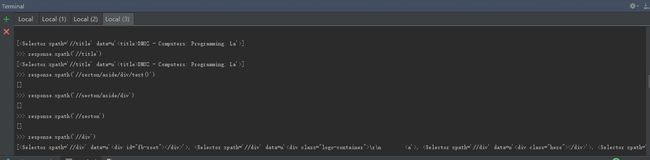
Test Result:
- 发现解析页面URL为 DomzBook
- response.xpath('//section/aside/div')未获取到响应标签内容,尝试xpath语法

7.重新解析页面层次调用结构
- "title" div class="title-and-desc" -> a -> div class="site-title" -> text()
- "link" div class="title-and-desc" -> a -> @href
- "desc" div class="site-descr" -> text()

console Input
response.xpath("//div[@class='title-and-desc']")
更新WikiSpider.py
import scrapy
from wikiSpider.items import WikispiderItem
class WikiSpider(scrapy.Spider):
name = "wiki"
allowed_domains = ["dmoztools.net"]
start_urls = [
"http://dmoztools.net/Computers/Programming/Languages/Python/Books/",
"http://dmoztools.net/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
item = WikispiderItem()
content = response.xpath("//div[contains(@class,'site-item')]/text()")
print content
for sel in response.xpath("//div[contains(@class,'site-item')]"):
item['title'] = sel.xpath("div[@class='title-and-desc']/a/div[@class='site-title']/text()")
item['link'] = sel.xpath("div[@class='title-and-desc']/a/@href")
item['desc'] = sel.xpath("div[@class='site-descr']/text()")
return item
console output
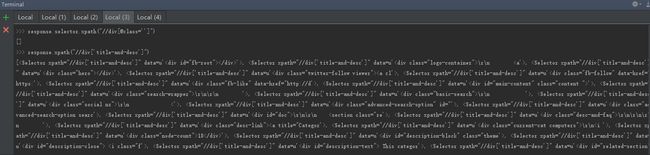
发现某些div未正确解析,查看嵌套选择器,原因在于Xpath是一种基于XML文档的搜索方式,对于css的规则仅解析为字符串,尝试contains标记属性节点
console Input
response.xpath("//div[contains(@class,'site-item')]")
console output > > 标注行已成功返回响应标签值
F:\pythonProject\wikiSpider>scrapy crawl wiki
2017-07-09 22:24:14 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: wikiSpider)
2017-07-09 22:24:14 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'wikiSpider.spiders', 'SPIDER_MODULES': ['wikiSpider.spiders'], 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'wikiSpider'}
2017-07-09 22:24:14 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-07-09 22:24:15 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-07-09 22:24:15 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-07-09 22:24:15 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-07-09 22:24:15 [scrapy.core.engine] INFO: Spider opened
2017-07-09 22:24:15 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-07-09 22:24:15 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6027
2017-07-09 22:24:15 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2017-07-09 22:24:17 [scrapy.core.engine] DEBUG: Crawled (200) , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,