机器学习_周志华 第三章 线性模型 学习笔记 3.1-3.2
3.1 线性模型的基本形式
对于拥有d个属性的示例, ![]()
![]() = (
= (![]() ), 其中xi是x的第i个属性上的取值,线性模型希望通过属性(即
), 其中xi是x的第i个属性上的取值,线性模型希望通过属性(即![]() ,
, ![]() )线性组合来进行预测,即:
)线性组合来进行预测,即:
![]()
其中![]() = (
= (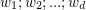 ),通过学习,得到
),通过学习,得到![]() 和
和![]() 之后,模型就得到确定了。
之后,模型就得到确定了。
![]() 中的各个属性可看作一个重要性的系数,以西瓜为例,我们通过西瓜的色泽,根蒂以及敲声来判断一个西瓜的好坏,那么,我们就可以得到:
中的各个属性可看作一个重要性的系数,以西瓜为例,我们通过西瓜的色泽,根蒂以及敲声来判断一个西瓜的好坏,那么,我们就可以得到:
![]()
其中![]() =(0.2,0.5,0.3),通过色泽,瓜蒂,敲声来综合判断一个瓜的好坏,其中瓜蒂最为重要,所以在
=(0.2,0.5,0.3),通过色泽,瓜蒂,敲声来综合判断一个瓜的好坏,其中瓜蒂最为重要,所以在![]() 中系数为0.5,而色泽和敲声系数分别为0.2和0.3.
中系数为0.5,而色泽和敲声系数分别为0.2和0.3.
3.2 线性回归
每个数据集D中都存在很多的数据,对于每一个数据用![]() 表示,其中
表示,其中![]() ,“线性回归”就是我们试图用数据集D中的数据来训练一个线性模型,来尽可能准确的预测实质输出标记(即
,“线性回归”就是我们试图用数据集D中的数据来训练一个线性模型,来尽可能准确的预测实质输出标记(即![]() )。
)。
我们首先考虑输入(即![]() )只有一个属性的情况(即
)只有一个属性的情况(即![]() 且
且 ![]() )。
)。
3.2.1 对于属性值为离散属性时,我们如何将其转化为连续属性
对于输入不是数值的离散性输入,我们可以根据数据之间的“序”的关系,通过连续化将其转化为连续值,例如身高属性,他的取值可以是“高”和“矮”,根据他们之间的关系,我们可以用{1.0,0.0}来表示{高,矮}的关系。若不只有两种属性取值,例如高度属性,我们可以取值“高”,“中”,“低”,我们就可以转化为{1.0,0.5,0.0}的数值属性,这是对于属性之间存在一个“序”的关系的时候,我们可以运用这种形式,将其转化为连续性的数值属性。
若属性之间不存在序的关系,即各个属性值之间没有关联,假定我们可以取k种属性值,就可转化为k维向量来表示,当![]() 时,分别为
时,分别为![]()
3.2.2 线性回归
我们现在试图去学习一个线性模型![]() ,使得:
,使得:
![]() , 使得
, 使得![]()
均方误差:![]() 表示模型
表示模型![]() 在数据集
在数据集![]() 上的均方误差
上的均方误差
我们使用均方误差来衡量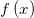 和
和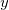 之间的差别。均方误差是回归任务中最常用的性能度量,我们要想求得我们所期望的
之间的差别。均方误差是回归任务中最常用的性能度量,我们要想求得我们所期望的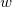 和
和![]() ,我们就要试图使得均方误差最小。
,我们就要试图使得均方误差最小。
![]() 函数:返回满足求得函数值最小时的输入参数
函数:返回满足求得函数值最小时的输入参数
上面的公式即在求满足均方误差最小时的和![]() 。
。
3.2.2.1 利用最小二乘法来求解线性回归
最小二乘法:基于均方误差最小化来进行模型求解的方法。
(形象记忆)在线性回归中,最小二乘法就是试图找到一条直线,使得所有样本到直线上的欧式距离之和最小。
由最小二乘法的定义我们可知,我们所需要求的是:![]() 的最小值,
的最小值,![]() 是关于和
是关于和![]() 的二元函数,由多元函数求极值得方式,我们就可以解得,当
的二元函数,由多元函数求极值得方式,我们就可以解得,当![]() 取得极小值时,和
取得极小值时,和![]() 的值。
的值。
关于多元函数就极值,可参考:https://blog.csdn.net/baishuiniyaonulia/article/details/80141115
我们将![]() 分别对和
分别对和![]() 求偏导,得到:
求偏导,得到:
![]()
![]()
由于我们要取极小值,所以领上面两个式子等于0,可以求得:
![]()
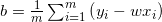
其中![]() 为
为 的均值。
的均值。
以上是当样本只有一个属性时的讨论。
3.2.3 多元线性回归
多元线性回归是数据集![]() 中的样本
中的样本![]() 具有d个属性的描述,我们刚刚讨论的线性回归是数据集
具有d个属性的描述,我们刚刚讨论的线性回归是数据集![]() 中的样本
中的样本![]() 只具有1个属性。
只具有1个属性。
当样本![]() 具有d个属性时,我们试图学习到的模型形式:
具有d个属性时,我们试图学习到的模型形式:
![]() ,使得
,使得![]()
多元线性回归的的求参思路,与线性回归相同,也是运用最小二乘法对![]() 和
和![]() 进行估计。由于多元线性回归具有
进行估计。由于多元线性回归具有 个属性,所以我们在计算时,通常会将其转化为矩阵形式的计算,这就要求我们要学会矩阵计算的求偏导公式。
个属性,所以我们在计算时,通常会将其转化为矩阵形式的计算,这就要求我们要学会矩阵计算的求偏导公式。
矩阵计算求偏导:目前没有找到能把我讲明白的博客,后续补链接
假设数据集![]() 中具有
中具有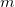 个样本。
个样本。
设:
![]()
![]()
前列代表的是每个样本具有种属性,![]() 列的1是在计算时根据函数表达式
列的1是在计算时根据函数表达式![]() ,来加上
,来加上![]() 的。
的。
则转化为矩阵以后:![]()
则我们用最小二乘法去求解多元线性回归的参数矩阵![]() :
:
![]()
3.2.3.1 利用最小二乘法来求解多元线性回归
令![]() ,其中
,其中![]() 为未知参量,我们对
为未知参量,我们对![]() 进行求导得到:
进行求导得到:
![]() (此处用到了矩阵求导的知识)
(此处用到了矩阵求导的知识)
令上式等于零可得
![]()
![]()
![]()
1)当![]() 为满秩矩阵或正定矩阵时,矩阵可逆,得:
为满秩矩阵或正定矩阵时,矩阵可逆,得:
![]()
则设 ![]() , 由
, 由 ![]() 可得
可得 ![]()
2)但现实任务中![]() 往往不是满秩矩阵,此时我们会解出多个
往往不是满秩矩阵,此时我们会解出多个![]() ,他们都能使得均方误差最小,这时我们选择哪一个解作为输出是由学习算法的偏好决定的,常见的做法是引入正则化项。
,他们都能使得均方误差最小,这时我们选择哪一个解作为输出是由学习算法的偏好决定的,常见的做法是引入正则化项。
3.2.4 对数线性回归
由上面的线性回归和多元线性回归的内容可知,我们将线性回归模型写成 ![]() 的形式。
的形式。
这时就衍生出了,当我们认为示例所对应的输出标记是在指数上进行变化的,我们可以将输出标记的对数当作模型逼近的目标,即:![]() ,这就叫做对数线性回归,实际上就是试图用
,这就叫做对数线性回归,实际上就是试图用 ![]() 去逼近 。
去逼近 。
在式子 ![]() 中,他仍然是一个线性的表示,但是实质上已经是输入空间到输出空间的一个非线性的映射了。
中,他仍然是一个线性的表示,但是实质上已经是输入空间到输出空间的一个非线性的映射了。
3.2.5 广义线性模型
例如3.2.4中的对数线性回归,我们更一般的考虑这样的形式,对于单调可微的函数![]() ,即
,即![]()
可以得到 ![]()
这样的模型我们称为“广义线性模型”,其中函数![]() 称为“联系函数”,可以看出,对数线性回归是广义线性模型在
称为“联系函数”,可以看出,对数线性回归是广义线性模型在![]() 时的特例。
时的特例。