通过SLB四层代理上传大文件 延时失败问题探究
文章目录
- 故事背景
- 一 概念介绍
- 1.1 TCP/IP报文的组成
- 1.2 MTU
- 1.3 MSS
- 1.4 ICMP 报文
- 1.5 PMTUD
- 二 TCP三次握手探秘
- 2.1 同网段直连握手
- 2.2 跨网段握手
- 2.3 经过四层设备透明转发
- 2.4 经过四层非透明转发
- 2.5 经过七层转发
- 2.6 实验验证
- 三 案例分析
- 3.1 阿里SLB四层转发 k8s nodeport模式 大数据传输502
- 四 遗留问题
- 参考链接
故事背景
这一切要从上次阿里云SLB七层转发,无法传输header(大于1460字节),但是四层却可以正常传输的问题说起,经过解这个难缠的问题,第一次了解了TCP中MSS,PMTU,还有icmp type3 code4差错报文,对TCP三次握手中,MSS的协商过程有了一个模糊的认识
但是事实证明,这个问题是有多么的常见,模糊的知识认知,在遇到更加具现问题的时候显得那么的苍白无力,我们只能从现象,从顶层去一点点摸索猜测,验证,来弥补底层网络知识的空白,整个过程迷茫而痛苦,却又充满激情和挑战,
一 概念介绍
在介绍整个事件来龙去脉前,需要先恶补一点基础知识
1.1 TCP/IP报文的组成
报文是网络传输的单位,应用程序产生的数据,在传输过程中会不断的封装成分组、包、帧来传输,封装的方式就是添加一些以一定格式组织起来的报文头信息,最后格式化成比特流,以高低电平,或者光信号的闪灭,在物理层进行传输
数据包传输的层级,决定了设备有权利获取数据包中那一层的信息,比如一个三层设备,是不能获取到四层包里的信息的,这个设备最多封装上一层主机的三层包头,就想数据包转发出去了
这一点需要记住,后面有用
我们看下TCP报文头组成
众所周知,TCP处在网络结构中的第四层,抓包软件体现的很清晰,的确实在第四层
 图:1.1-1
图:1.1-1
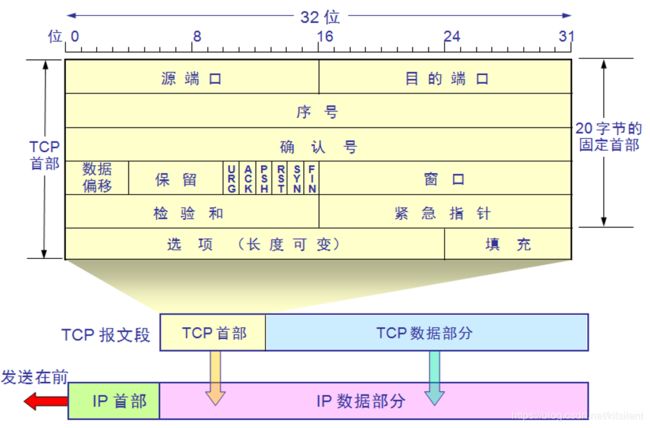
图1.1-2
这张图可以看到,tcp报文头信息又基本的20字节组成,外加上TCP Options拓展信息,也就是说TCP的报文头部是会超过20字节的,我们本问题的主角MSS就这这个部分里传递
这个只是TCP头部信息,当然还有IP头,MAC头信息,这不详细解释,可以参考这篇文章
https://www.iteye.com/blog/elf8848-2089414 讲的很详细
1.2 MTU
MTU是Maximum Transmission Unit的缩写,单位是字节,是网络设备上允许传输的网络包的最大长度,这个由网络设备的物理特性决定,不通的网络设备可能拥有不同的MTU值,大部分网络设备的MTU是1500 ,其实网络链路中最大承受的字节数是1518个字节,由于以太网报文头要占用14个字节,再加上4字节的校验位,那么留给网卡的可传送数据就只剩1500字节了
我们如何查看或者修改我们的网卡的mtu呢
- windows
查看网卡mtu
注意:当修改mtu的时候需要管理员权限运行cmd
##这里
C:\Users\nsk>netsh interface ipv4 show interfaces
Idx Met MTU State Name
--- ---------- ---------- ------------ ---------------------------
1 75 4294967295 connected Loopback Pseudo-Interface 1
23 45 1400 connected WLAN
13 5 1500 disconnected 以太网
5 65 1500 disconnected 蓝牙网络连接
19 25 1500 disconnected 本地连接* 12
11 35 1500 disconnected 以太网 2
51 5000 1500 connected vEthernet (WSL)
修改网卡mtu
找到要设置mtu的网卡Idx,用一下命令设置其mtu 立即生效
# store=persistent 重启也不会失效哦
netsh interface ipv4 set subinterface "13" mtu=1400 store=persistent
- linux
查看mtu
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: bond0: <BROADCAST,MULTICAST,MASTER> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 12:bd:c3:fd:6f:67 brd ff:ff:ff:ff:ff:ff
3: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ca:9d:82:a9:e5:44 brd ff:ff:ff:ff:ff:ff
4: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/sit 0.0.0.0 brd 0.0.0.0
5: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:15:5d:91:62:9c brd ff:ff:ff:ff:ff:ff
修改mtu
ip link set dev eth0 mtu 1400
1.3 MSS
MSS 是Maximum segment size的缩写,最大报文段长度,是TCP选项里的一个参数,他规定每个TCP报文传送数据的最大限额,为什么会有MSS的存在呢?
上一个标题我们解释了MTU是什么东东,也就是网卡可以接收的最大报文的长度,这里暂时定为1500,那如果有一个数据包超过了这个最大的传输单元1500字节后,会有什么后果呢?
链路层由于承受不了这么大的数据包,ip协议就会选择将数据包分开传送,这些包分片到对端的网卡设备后,再将分开的包重新组装起来,这样既降低了效率,而且还增加了丢包率,有很多设备是不支持ip层分包的,也就是你发送超过了网卡设备MTU的包,他就会丢弃这个包(比如阿里的SLB)
所以TCP协议在握手阶段,会和对端的设备商议好大家可以接收的MSS,规定的方法也简单粗暴,就是把自己网络出口设备的MTU减去ip首部(20字节)和tcp首部(字节)需要占用的字节数40个字节
一般如果你的网卡MTU是1500的话,那么不出意外,你跟别的设备第一次握手通报的的MSS应该是1460,这里写的“应该”,而不是“一定”,是因为,不排除别的协议可能会占用一些头部信息的资源,导致实际的MSS更少,比如一些VPN需要的用来加密的头部信息,或者PPPoE 用来额外计费的8字节畸形设计等等
MSS只会出现在SYN报文中
原来MSS的存在是为了避免ip分片产生,那为什么要避免ip分片,ip分片过多又是如何影响效率呢
首先ip协议是无状态的协议,并没有重传机制,当数据包的某个分片出现丢包,将不可避免造成所有数据分片都要重传一遍
其次当一个数据包封装过大,经过网卡可能会被分成很多ip分片,这些分配被一个统一的标识符锁定定,加上自己的偏移位来确定分配在报文中的位置,被下一个网卡得以将报文重组,这样频繁的分包重组,无形中加重了网卡的负担影响传输效率
所以传输最优策略就是在一开始,就协商好合适的MSS,保证tcp的分段数据可以合适的通过路径上的每个MTU,而不造成分片,但是这里讲到的协商MSS的过程适合同网络两台主机直接通信,那要是跨网络通信,中间通过了很多三层的路由设备,他们却无法通过四层的MSS里的信息来通报自己的合适的MTU值,那该咋办?
无敌的网络设计师们设计出了PMTUD来解决这个问题,接下来的1.5会讲到
我们来看个清晰的图片来认识下报文的组成,以及MSS在其中位置
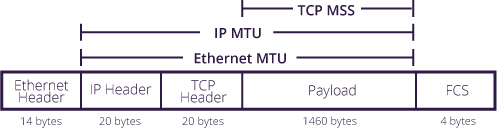
图:1.3-1
这张图可以清晰的看到MSS具体是定义什么的,也就是TCP真正可以运送的数据块的大小,这部分是真正有价值那部分数据,而别的头部信息,也不得不随着数据包一起传递,就向我们寄送快递一样,一层层包装并不是我们想要的,但却必不可少

图:1.3-2
TCP报文在协商好MSS后,即认为它封装的数据是正好可以通过所有链路,而不触发ip层的分包的,所以它会在ip头部信息标志位DF(Dont fragment)置位1
 图:1.3-3
图:1.3-3
如果一个网络设备接收到这样一个数据包,包的大小超过了MTU,但是却有DF 标志位置为了1 ,它会怎么做呢,这里引入了ip协议的一个补充协议,icmp协议,大多数人的概念里,都认为这个协议就是配合ping功能做设备存活性探测的,包括我,直到这里我才发现icmp另有天地,ping的探测报文只是icmp报文的一个类型而已,具体请看1.4 这个icmp协议会向发送 报文的源设备发送一个差错报文,来通报数据包被丢弃的原因,从而使发送的包的大小可以更加合适网络设备的MTU从而避免ip层的分包
1.4 ICMP 报文
icmp是Internet Control Message Protocol 的因为缩写,通常认识是ip协议的一个补充协议,用来探测终端设备是否网络是否可达,以及传递数据包被意外丢弃的差错报文给用户进程
ICMP报文是在IP数据报内部被传输的

图:1.4-1
icmp类型
icmp报文主要分为两个类型,查询类和差错类
查询类:主要判断数据包是否成功到达目标地址
差错类:传回数据包被丢弃的原因
ICMP提供一致易懂的出错报告信息。发送的出错报文返回到发送原数据的设备,因为只有发送设备才是出错报文的逻辑接受者。发送设备随后可根据ICMP报文确定发生错误的类型,并确定如何才能更好地重发失败的数据包。但是ICMP唯一的功能是报告问题而不是纠正错误,纠正错误的任务由发送方完成
网卡将包丢弃,向数据的源发送设备发型icmp差错报文,通报数据包太大的这个消息,那么如果icmp包过程中被屏蔽掉了,会出现什么结果呢,那就是数据源设备不断的发送数据包,路径中的某个网卡设备不断的丢包,这个设备称为路由黑洞,然后源设备不断重传的结果,恰巧很多网络管理人员出于网络安全考虑,会将整个icmp协议都屏蔽掉,就会出现这个现象
这里重点说下我们接下里会用到的type3 code4 类型报文 这是由于ip协议层设置了不可分包标志位DF而发送的差错报文

图:1.4-2 不可分包差错报文组成
前32位中的高16位是用来标识报文类型,低16位为icmp报文的校验和,这个校验和是用来校验报文的合法性的,有特定的算法来算出
中间的32位的低16位字节,标出由于MTU过小,会造成ip分片的下一跳MTU,通过在这个值,我们可以清晰的知道路径中最小的MTU是多少
校验和
- 生成校验和的算法
首先将检验和位置位0,通过将icmp 首部字段按照16bit为一个单位(当碰到奇数字节时,最后一个字节的低8位用0补齐即可),进行二进制取反,然后依次相加,溢出位补加到低位,保证整体不会超过16位,算出来的结果,按位取反后即为校验和,存入icmp报文的校验和位 - 检验校验和的方法
由于校验和是icmp首部除校验和字段的二级制取反后求和,然后再按位取反得到的,如果传输过程中没有出现差错,那么用同样的算法,将所有的头部信息相加(包括之前生成的校验和),所得到的的结果必然全为1,这样就实现了校验报文的效果
校验和算法,可以参考RCF1071
计算校验和简单的例子
这个校验和的算法实在是难懂,我们就用一个最简单的例子来代替,假设我们的校验和只有一个字节8bit,我们的算法是将头部信息中8bit为一个组合进行相加
假设我们的头部信息为以下报文
10000000 checksum 00000001
按照算法,我们先将checksum置位0,然后将其余的字节取反,求和,溢出位加到最低位
1000 0000 checksum 0000 0001
0111 1111 + 0 + 1111 1110 = 01111110
01111 1110 ---按位取反---> 1000 0001=checksum
那么此时我们的报文变成了这样
0111 1111 1000 0001(checksum) 1111 1110
假设这个报文讲过了网络传输到了数据接收设备,进行校验
首先将所有位 按位取反
0111 1111 1000 0001(checksum) 1111 1110
得到
1000 0000 0111 1110 0000 0001
1000 0000
+ = 1111 1110
0111 1110
+
0000 0001 #( checksum)
= 1111 1111 #全为1
可以看到结果全为1,则证明这个包是ok的
如果计算发现结果不全为1 ,也可以反推出实际的校验和应该为多少,可以看出,就是除了校验和位,其余头部信息,求和的取反!
惊叹!!!这里不得不佩服大佬们的操作啊~真是太牛逼了
今天和同事强哥探讨这个算法的必要性,同事说,直接将头部信息算个和不就行了,到目的设备,再算一遍,比对一下不就知道数据对不对了?
咋一听好有道理,但是细想下,就能找到纰漏,比如我们的头部信息只有三个字节,其中一个字节就是校验位
0000 0001 0000 0001 求和 ---->0000 0010
传输的过程中 报文变成了这样子
0000 0000 0000 0010 求和----->0000 0010
两个和是一样的,但是能说明传输的过程是没有问题的吗?
有兴趣的还可以用大神的算法来试一下我们这个例子,得出来的结果可能是不一样的
由于所有的数据最终在物理层传输都是化为比特流的形式传输的,所以想要保证报文传输没问题,必须保住每一位都是正确传输的,这也就是算法中对每一位取反的原由吧
这里为什么这么大篇幅来扯这个校验和,因为在第三段案例中,会有类似的坑,这里可以来看一个由于校验和未通过的 的差错报文
图中黄色部分标出了校验和有错,应该是多少也标记了出来,这样差错报文,主机默认是不接受的,也就导致源设备不会因为这样一个差错报文而改变自己的发包策略,没有将数据包切割成更小的tcp段来传输,问题不解决,自然会导致重复的丢包,数据无法正常传输了

图:1.4-3 校验码异常的报文
下面看一个正常的icmp 由于不可分包导致的差错报文
这里可以结合图1.4-2 来观看
checksum 0x96c0 : 正好16位
checksum status Good: 说明校验码验证通过了
MTU of next hop :说明了报文被那一步的mtu给拦截了需要分包
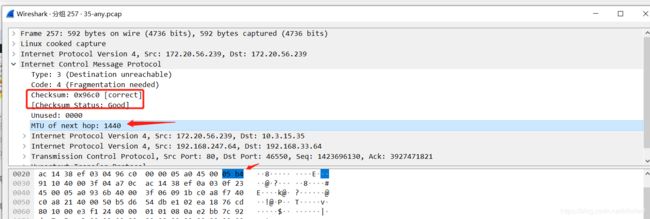
图:1.4-4 校验码正常的报文
下面是一些icmp的报文类型
| TYPE | CODE | Description | Query | Error |
|---|---|---|---|---|
| 0 | 0 | Echo Reply——回显应答(Ping应答) | x | |
| 3 | 0 | Network Unreachable——网络不可达 | x | |
| 3 | 1 | Host Unreachable——主机不可达 | x | |
| 3 | 2 | Protocol Unreachable——协议不可达 | x | |
| 3 | 3 | Port Unreachable——端口不可达 | x | |
| 3 | 4 | Fragmentation needed but no frag. bit set——需要进行分片但设置不分片比特 | x | |
| 3 | 5 | Source routing failed——源站选路失败 | x | |
| 3 | 6 | Destination network unknown——目的网络未知 | x | |
| 3 | 7 | Destination host unknown——目的主机未知 | x | |
| 3 | 8 | Source host isolated (obsolete)——源主机被隔离(作废不用) | x | |
| 3 | 9 | Destination network administratively prohibited——目的网络被强制禁止 | x | |
| 3 | 10 | Destination host administratively prohibited——目的主机被强制禁止 | x | |
| 3 | 11 | Network unreachable for TOS——由于服务类型TOS,网络不可达 | x | |
| 3 | 12 | Host unreachable for TOS——由于服务类型TOS,主机不可达 | x | |
| 3 | 13 | Communication administratively prohibited by filtering——由于过滤,通信被强制禁止 | x | |
| 3 | 14 | Host precedence violation——主机越权 | x | |
| 3 | 15 | Precedence cutoff in effect——优先中止生效 | x | |
| 4 | 0 | Source quench——源端被关闭(基本流控制) | ||
| 5 | 0 | Redirect for network——对网络重定向 | ||
| 5 | 1 | Redirect for host——对主机重定向 | ||
| 5 | 2 | Redirect for TOS and network——对服务类型和网络重定向 | ||
| 5 | 3 | Redirect for TOS and host——对服务类型和主机重定向 | ||
| 8 | 0 | Echo request——回显请求(Ping请求) x | ||
| 9 | 0 | Router advertisement——路由器通告 | ||
| 10 | 0 | Route solicitation——路由器请求 | ||
| 11 | 0 | TTL equals 0 during transit——传输期间生存时间为0 | x | |
| 11 | 1 | TTL equals 0 during reassembly——在数据报组装期间生存时间为0 | x | |
| 12 | 0 | IP header bad (catchall error)——坏的IP首部(包括各种差错) | x | |
| 12 | 1 | Required options missing——缺少必需的选项 | x | |
| 13 | 0 Timestamp request (obsolete)——时间戳请求(作废不用) x | |||
| 14 | Timestamp reply (obsolete)——时间戳应答(作废不用) x | |||
| 15 | 0 | Information request (obsolete)——信息请求(作废不用) x | ||
| 16 | 0 | Information reply (obsolete)——信息应答(作废不用) x | ||
| 17 | 0 | Address mask request——地址掩码请求 x | ||
| 18 | 0 | Address mask reply——地址掩码应答 |
表:1.4-1
1.5 PMTUD
路径MTU(PMTU),一种动态发现因特网上任意一条路径的最大传输单元(MTU)的技术
当在同一个网络上的两台主机互相进行通信时,该网络的MTU是非常重要的。但是如果两台主机之间的通信要通过多个网络,那么每个网络的链路层就可能有不同的MTU。重要的不是两台主机所在网络的MTU的值,重要的是两台通信主机路径中的最小MTU。它被称作路径MTU。
两台主机之间的路径MTU不一定是个常数。它取决于当时所选择的路由。而选路不一定是对称的(从A到B的路由可能与从B到A的路由不同),因此路径MTU在两个方向上不一定是一致的。
PMTU的大小决定了MSS大小,是tcp在链路传输中,ip层不分包的前提下可传输的最大数据量
在1.3节 MSS 中讲到了 端到端通信,如何通过TCP报文来协商MSS,但是设计到跨网络通信,或者跨代理设备通信,这两个端点之间就存在存在更小 MTU 链路的情况,这种情况下,我们将无法通过在SYN握手报文中,一次性的协商好MSS,于是PMTUD 路径MTU Discovery 算法解决了问题,解决的方法就是通过 1.4节有讲到的 icmp的差错报文,这样可以在三层链路中实现MTU的动态发现,从而避免了网络层无法理解四层报文的尴尬处境
具体实现:
- PMTUD只有TCP才特有的,当PMTUD出于启用状态,所有来自改主机的TCP/IP数据包中的ip首部 DF(Dont Fragment) 比特位都会被置位1,主机会以TCP握手阶段协商好的MSS为最大tcp数据量传输TCP分段包
- 当某个TCP分段包,在传输的链路上遇到一个更小的MTU设备时,由于数据包的ip首部设置了不可分包标志,网卡设备会将整个包丢弃,并且将丢包的原因,以icmp type3 code4 类型的差错报文 格式,向数据包的源设备发送差错通告,icmp中包括了一些必要信息,比如可能导致分包的下一跳的MTU的值,还有传输层的源端口 目标端口 标记tcp分段包的 seq 和ack的值,包括应用层的信息等
- 假如差错在回源的路上,没有收到防火墙阻拦,安全到达发送数据包的源设备,发送方会对icmp报文checksum校验和做一次校验,如果没问题,则按照差错信息,记录探测到PMTU,主机在带MTU值的路由表创建“主机”(/32)条目,从而“记住”目的地使用的MTU值
linux内核参数 net.ipv4.route.mtu_expires 记录pmtu的缓存时间,默认为6分钟
可以通过echo 1 >/proc/sys/net/ipv4/route/flush来释放pmtu的缓存
- 数据的源端设备通过最新的PMTU值再次发送TCP报文,不断重复上面过程,知道数据包可以不分包,传至目标设备
- 目标设备回传数据会经过同样的PMTUD的逻辑,应为MSS的值是双向不对称的,我们上面说过这个问题
RFC 1191[Mogul and Deering 1990]描述了路径MTU的发现机制,即在任何时候确定路径MTU的方法
这张图是RFC1191 规定的PMTU的具体实现,有兴趣可以读一下
图:1.5-1
二 TCP三次握手探秘
关于tcp三次握手,四次挥手的桥段,网上真的是烂大街了,一手一大把,这里不再赘述了,只是贴一张图片来参考下,我们主要针对tcp三次握手的场景来进行下探讨
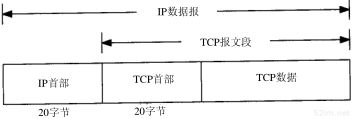
图 2-1 tcp在ip数据包中的封装
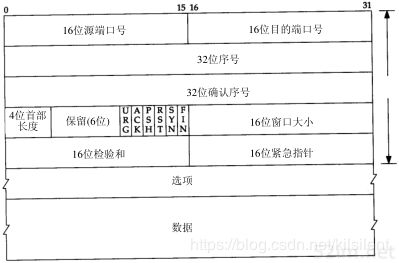
图2-2 tcp 包头信息,如果不计算任选字节,通常为20字节

图 2-3 三次握手过程
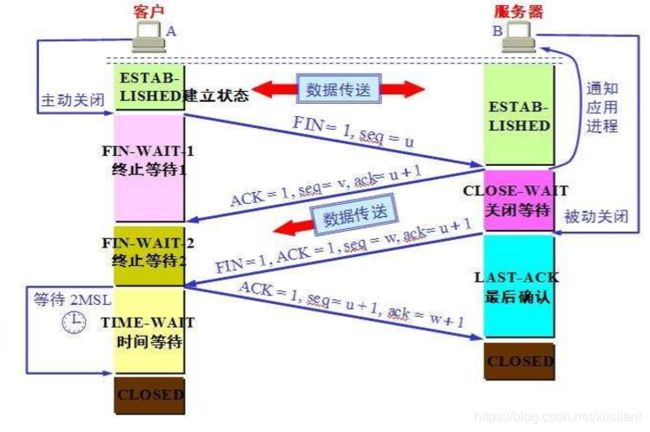
图 2-4 四次挥手过程

图2-5 有限状态机
接下来我们来研究下,两台主机上的两个应用A 和B 在不同环境下通过TCP通信,是如何建立tcp连接的
2.1 同网段直连握手

当源主机和目标主机在同一个网段的时候,这是最理想简单的一种场景,源ip和目标ip,源端口和目标端口都是可追溯, mss 协商就是在两台主机出口网卡的mtu之前选最小的一个,减去ip和tcp头信息占用的40字节就可以了,这种场景mss 为1360,而且不会出现icmp的差错报文,因为所有的mtu已经在握手阶段探测清楚了
2.2 跨网段握手

- 当源主机和和目标主机不再同一网段,数据包的流转就稍显复杂,因为三次握手协商的MSS只有四层设备能够感知,中间路由器的MTU是无法得知的,所以第一次发包时,MSS为A主机和B主机出口网卡的MTU最小值,减去ip tcp头信息占用字节,为1360
- 1360的数据包发到路由器C的时候,由于下一跳的MTU只有1360需要分包,但是数据包内有DF位,网卡丢弃报文,发回icmp差错报文到A主机,刷新主机路由表中对应路劲的pmtu,mss 调整为1300-40 改为1260,接下来所有的包最大都不会超过1300,A到B的路打通了
- B返回数据包至A,会经历A所经历的一切,通过PMTUD算法,调节MSS
2.3 经过四层设备透明转发

- mss的协商过程,可以参考2.3
- 中间的设备只是做了一个四层路由器的角色,不解封四层的包,只是根据路由规则,将数据包发送到指定的设备,所以表现为同一个tcp连接
2.4 经过四层非透明转发
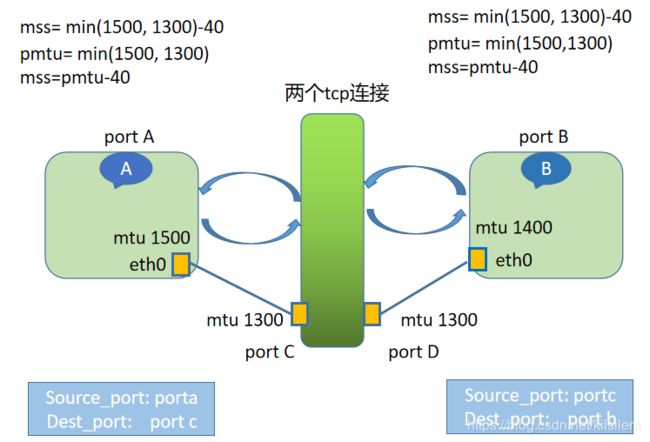
- 当中间的设备做的是非透明的四层转发角色,比如nginx,我们也可以把它叫做四层代理,那么当A请求B的包发过来时,设备会将包四层包头解封后,读取数据后,再重新封装四层包头,当成一个客户端向主机B发送TCP请求,由于TCP头信息是重新封装过的,表现出来的源端口一定会改变,于是多出了一个tcp的连接,所以这里有两个连接
2.5 经过七层转发
七层转发的参考四层的非透明转发
2.6 实验验证
为了验证我们上面五个图,是不是正确的,我们来做一个实验
- 实验条件
- 使用calio ipip模式构建的k8s网络环境,创建svc在16.14主机上监听800端口,将请求转发至指定pod的800端口
- 在172.20.52.44上配置四层转发,监听800端口,请求转发至10.166.16.14的800端口
- 实验的目的
- 验证通过nginx四层转发为非透明转发,k8s的 nodeport模式为四层的透明转发
- 透明转发的情况下,访问目标应用不再额外创建tcp连接,只是对数据包的分发流转,而非透明转发会重新封装TCP包,再次维护一个tcp连接
- 访问链路图
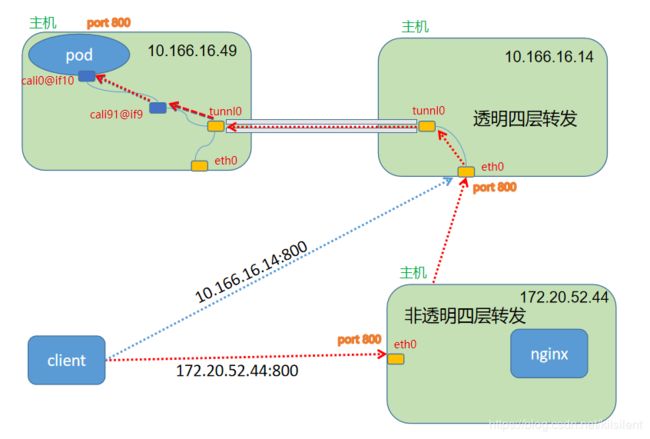
情形一 (直接请求nodeport)
图中从client端,沿着蓝色的链路直接访问10.166.16.14:800端口
- 登录pod 查看链接,可以看到当前,客户端请求的源端口是61384

- 在client 抓包,可以看到客户端发送请求的源端口的确是61384
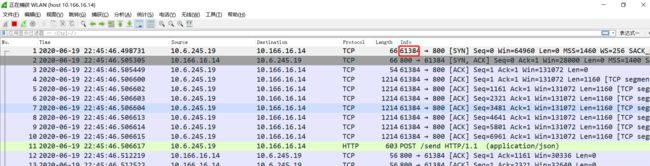
情形一 验证了 k8s 的nodeport模式实现的转发是透明的四层转发,同样证实了2.3节的说法,tcp连接通过四层透明转发维护的是一个tcp连接,源端口和目标端口是不会改变的
情形二(通过nginx 四层代理)
图中从client端,沿着红色的链路直接访问172.20.52.44:800端口
- 登录pod 查看链接,可以看到当前,客户端请求的源端口是49744

- 在client 抓包,可以看到客户端发送请求的源端口的确是61988
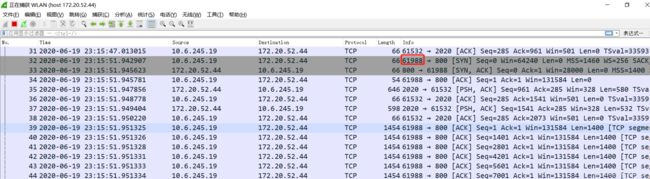
- 在nginx 172.20.52.44 主机上抓包一看究竟
情形二 验证了 nginx 的四层转发是不透明的四层转发操作,同样验证了我们2.4节理论,当tcp连接通过非透明的四层转发的时候,这个四层设备会充当一个四层代理,再次发起一个tcp连接去访问目标主机,从而增加一个tcp连接
- 结论
- 前面的理论都是对滴
- k8s 的nodeport 是透明四层转发 ,而nginx 的四层代理是非透明的四层转发
三 案例分析
由于案例中基本都是与阿里云的SLB 有关,这里附一张阿里云SLB的实现架构图

图3-1
阿里的slb 四层是通过lvs实现的,用的是full_nat模型 ,七层代理是通过Tengine实现的,这里需要着重说下的是,lvs也是四层透明转发,也就是tcp连接经过lvs,是不会被截断的,再多一个连接的。
3.1 阿里SLB四层转发 k8s nodeport模式 大数据传输502
-
背景
研发同事开发了新的功能,需要上线,最后商定了将服务发布到k8s集群,通过svc nodeport的形式将服务暴露出来,然后通过阿里云的公网slb的四层转发功能,将服务暴露至公网,当在内网一切调试ok后,在配置slb后,一系列诡异的问题接踵而至- 客户端在访问服务,上传数据时,当上传数据量稍大时,会出现超时的现象,但是网络是通的,端口也是通的
- 上传几百字节的数据时,一切都是ok的
- 当内网请求成功过一次后,从公网无论传多大数据,都不会出现超时现象
-
链路图
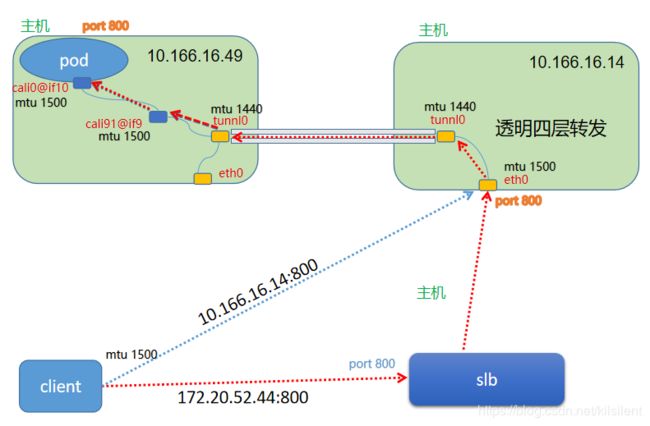
图 3.1-1 -
分析
其实有了前面的基础知识做铺垫,这个问题已经变得非常容器解决了,但是这里还是要写下,艰难的解惑之路
- 当出现超时问题后,果断进行了抓包操作,但是一开始抓包姿势有点问题,只抓了服务端口 800的报文,由于icmp属于三层的报文,无法被抓取到,导致错过了差错报文
- 仔细分析报文后,发现包传递好像有问题,就抱着试一试的心态,让研发同学按照1.2节讲到的命令,将电脑网卡MTU改成1400试了下,发现问题竟然解决了!! 那我的猜想是没问题的,一定是MSS的问题,重新抓取所有的包,果然抓到了icmp的差错报文,通过分析差错报文,可以发现问题出在了tunnel0的mtu上面,而clinet端不知为什么不去协商MSS
- 那既然找到了问题,那就先最快解决问题吧,既然直接访问nodeport没问题,那我就在nodeport主机和slb中间搭建一个可以截断tcp连接的设备,将客户端和pod维持的链接切成两段,这样tunnel0网卡返回的icmp差错报文,可以由四层代理设备处理,应该就不会出现超时现象了,于是在slb到nodeport之间加了一个nginx,做四层代理,问题果然解决了
-
解决
-
添加一个四层代理转发,来处理差错报文

图 3.1-2 -
修改calico网卡的mtu 和tunnel一致
-
阿里提供解决方案
-
四 遗留问题
- 为什么windows没有去响应icmp的差错报文
问题出现时,在clinent端抓包,的确看到了差错报文,但是client端却没有根据pmtud的算法去调小mss,原因是我们在1.4节 讲到的icmp 差错报文里的校验和,不知为什么,当差错报文经过阿里云的slb后,校验和出错了,所以client端不认这个报文,也就不去调小自己的mss
当然,你也可以忽略这个校验和的错误,方法就是关闭网卡的硬件校验和
参考 http://www.tudoupe.com/win10/win10jiqiao/2019/0524/8297.html
但是为什么校验和不对,现在也没有找到答案 - 为什么icmp差错报文,经过阿里云的slb四层代理后,校验和会出错?
参考链接
https://www.imperva.com/blog/mtu-mss-explained/
TCP 的那些事儿
https://www.iteye.com/blog/elf8848-2089414
rfc1911文档
https://www.ietf.org/rfc/rfc1191.txt
解决解决 GRE 和 IPSEC 中的 IP 分段、MTU、MSS 和 PMTUD 问题
https://m.baidu.com/ala/c/www.360doc.cn/mip/621875917.html
《TCP/IP详解 卷1:协议》
http://www.52im.net/topic-tcpipvol1.html
关闭 win10 网卡硬件校验
http://www.tudoupe.com/win10/win10jiqiao/2019/0524/8297.html