Embedding Methods-从相似度出发进行细粒度文本分类
知乎主页lynne阿黎请大家不吝关注
背景
实体分类是指给一个实体一个指定的标签,这在关系抽取,知识问答等任务中非常重要。一般实体分类的标签都小于20个,但是当标签之间具有层级结构,同一个实体在不同的上下文中便可能具有不同的角色。例如:
-
Madonna starred as Breathless Mahoney in the film Dick Tracy
-
Madonna signed with Sire Records in 1982 and released her eponymous debut album the next year.
这两句话中,第一句的Madonna因为主演了电影,她的分类应该是actress,而下一句Maddona推出了新专辑,这里她的分类应该是musician。
对于细粒度实体分类来说,一个最大的困难是标注文本的收集,因为在标注的时候不考虑上下文的话可能会如上文的例子一样,会引入很多噪音。实际上一个优秀的细粒度实体分类模型应该是可以处理这些噪音并且在训练过程中发现label之间的关系的。
针对这些问题,本文使用ranking loss来解决这些问题,下面我们来看看文中是怎么解决的吧
模型
1. 学习目标
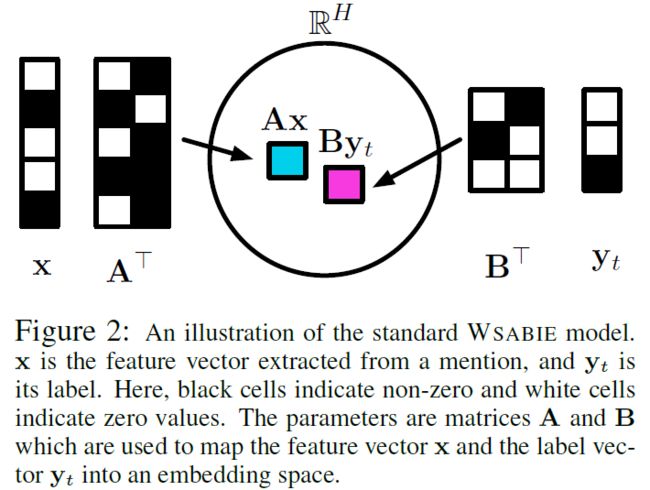
文中为了平衡细粒度标签之间的关系,将输入的文本信息和标签信息全都映射到一个低维空间![]() 中,其中H表示embedding的维度。映射方法如下图所示,我们对输入的文本信息和标签进行线性转换,将其映射到同一个低维空间。这样,标签之间的关系可以通过他们在低维空间的距离进行衡量,标签越不相关,那么他们的距离越远。
中,其中H表示embedding的维度。映射方法如下图所示,我们对输入的文本信息和标签进行线性转换,将其映射到同一个低维空间。这样,标签之间的关系可以通过他们在低维空间的距离进行衡量,标签越不相关,那么他们的距离越远。
对于一个实体和标签的距离如何衡量呢?既然我们已经有了他们在低维空间的向量,那么我们完全可以使用向量的点积来衡量他们的距离即:
![]()
其中x是指文本的向量,y是指标签的向量,AB分别是将其映射到低维空间的矩阵,f,g是他们的线性变换的函数。模型中待学习的参数是线性变换的矩阵A,B和输入的word embedding。
2. 损失函数
文中使用Weighted approximate pairwise(WARP),对于一个实体和他的标签{x,y}WARP loss如下:
![]()
其中y是x的真实标签集合,  是标签的补集。
是标签的补集。 ![]()
![]() R是将rank转化为权重的函数。文中使用SGD(stochastic gradient descent)对损失函数进行优化。
R是将rank转化为权重的函数。文中使用SGD(stochastic gradient descent)对损失函数进行优化。
3. 模型预测
对于本文任务的标签具有层级结构,一个实体有可能具有多个标签,因此如果只是单纯的选top1那么会伤害模型预测的正确性。因此本文选择top k作为正确的标签,k是标签的深度。所在预测过程中我们会设置一个阈值当s(x,y)大于这个阈值则认为标签是正确的。同时最后输出的时候我们会将和其他标签不是同一个类别的标签丢掉认为这是不合理的预测,例如person,artist和location,我们会认为location是不合理的预测。
但是这里又会面对另外一个问题,如果每个类型的标签数量都一致应该怎么选择呢,例如person和location,这点是文中是没有提到的。
4. Kernel Function
WSABIE模型的打分机制是![]() 这个计算的是和实体和标签的距离。其中
这个计算的是和实体和标签的距离。其中![]() 和
和![]() 分别表示线性变换矩阵的列向量。
分别表示线性变换矩阵的列向量。
本文采用Kernel function![]()
Kernel函数采用K近邻算法,选择B的200个最邻近的邻居其他均为0。采取这种计算方式的原因一是因为相比于其他的文本分类任务,本文中的任务分类相较于其他标签更为详细,因此所需要的数据量也更大,第二个原因是因为一个文本可能具有多个标签,这样可以避免噪声的影响。
实验结果
本文采用数据集GFT(Google Fine Types)和FIGER(Ling and Weld),两个数据集的标签分类如下所示,GFT的标签有4大类,PERSON,LOCATION,ORGANIZATION和OTHER。每个大类中又有其他小类,深度为7。FIGER有8个大类,标签深度为2。

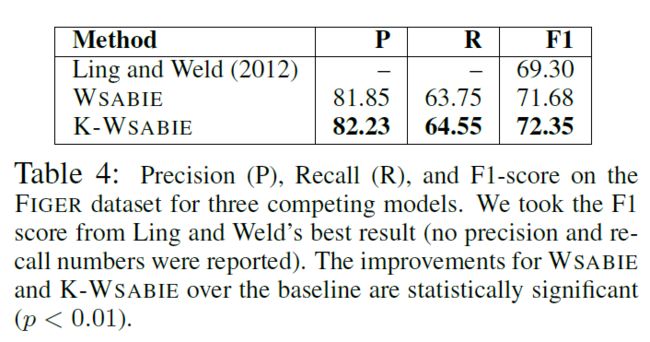
在GFT数据集上的效果如下:
在FIGER的数据集上效果如下:
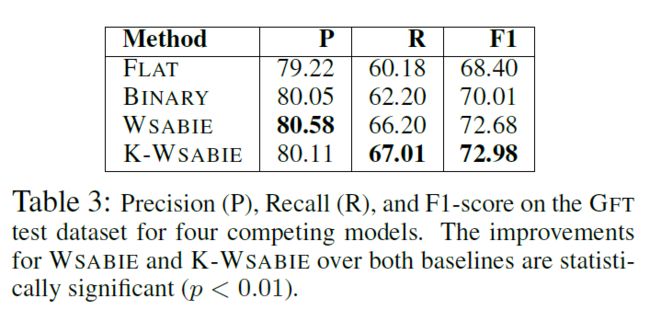
可以看到在两个数据集上K-WASIE的效果都达到了最优。
1. 标签粒度划分
看到这里是我感到最惊喜的,作者思考了一个问题,当我们划分实体的时候只用一级标签划分,这样效果是否会优于细粒度的标签。于是作者做了实验,只是用一级标签对文本进行分类,实验结果如下。我们发现粗粒度的文本分类的效果并不如细粒度,这个我在做NER的时候也遇到同样的问题,对于同一个大类别的细类别模型很难准确区分,所以会出现将实体边界切错的现象。这个我们分析,认为原因应该是我们的标签粒度太细,导致模型对于近似的标签很难区分。这也是为什么我最近一直在看细粒度文本分类的论文,后来我们尝试了lynne阿黎:HFT-CNN:层级多标签分类,让你的模型多学习几次,这篇文章的方法,有兴趣的同学也可以私信我一起探讨。

相关链接
- Embedding Methods for Fine Grained Entity Type Classification