Python进阶之路(2):批量下载豆瓣FM红心音乐MP3到本地
用豆瓣FM快十年了,听了3万多首歌,红心标记了近400首歌,然而由于版权问题只剩150首左右还能播放。以前用过一个可以下载浏览器播放的音视频文件到本地的插件,后来因为重装系统丢了,该插件也下架无法下载了。
所以很久都没有一个工具能够下载豆瓣音乐到本地。
今天偶然想到去Github看看有没人做过相关的项目,发现相关的项目都已经失效了。于是又开VPN去Chrome浏览器的扩展程序里找,找到了一个插件,可以爬取豆瓣FM上红心歌曲的下载链接和歌曲名信息。附该项目地址https://github.com/loveunk/douban-favorite-music-parser
效果图

于是我只需要编一个python程序,实现以下任务:
根据txt文件里的mp3下载地址和歌曲名,自动下载所有音乐保存到某个文件夹,文件命名为歌曲名。
已知:
我通过以上插件导出了两个txt文件,一个txt文件保存了mp3文件的下载地址,另一个txt文件保存了每个下载地址对应的歌曲名+专辑名+歌手名。


我需要把我的任务划分为几个步骤,依次编程完成每一个步骤,按步骤一个个解决问题。
细分任务:
1、打开下载地址txt文件,生成一个数组list,打开歌曲名txt文件,生成另一个数组list。
2、定义一个函数,描述下载一首歌这样一个动作。
3、for循环,引用之前定义的函数,将下载一首歌这个动作反复执行直到所有的歌都下载完。
一步步解决问题:
1、打开文件,生成数组
虽然入门教程里讲的是用open()函数打开文件,但我在之前解决问题的过程中,博主们反复推荐用with open()函数打开文件更稳,防止出现各种问题。
我用print()函数打印生成的数组。虽然入门教程第10章教导我不要用print()进行调试,但是其他的方法我还用的不熟练,这回依然是用print()来观察中间结果。
with open('DoubanMusicLinks.txt', 'r', encoding='utf-8') as f:
data = f.readlines()
data1 = [x.strip() for x in data]
f.close()
#print(data)
#print(data1)
加了encoding=‘utf-8’这句是因为,由于歌曲名txt文件里有很多歌曲名很奇怪,在gbk编码里没有,于是系统报错了,所以选用了utf-8编码,这个bug就消失了。
使用readlines()函数也是做了功课的,上一次我用的read()函数效果是一次性读取了文件里的 所有内容。readlines()函数和readline()函数的效果是每次读取一行数据,并且最后生成了数组,并且readlines()的效率高于readline(),并且readlines()读取的内容可以用于for……in……结构进行处理。
生成的数组每一条数据结尾都有\n回车符,所以用了strip()方法去除字符串首位的特殊符号。


同样地,我提取了歌曲名的数组
with open('musicList.txt', 'r', encoding='utf-8') as f1:
song = f1.readlines()
song_name = [x.strip() for x in song]
f1.close()
2、每次写入歌曲时都新建一个文件并命名文件名
我本来是考虑直接写一个for循环,传入下载地址这个变量,然后生成mp3文件,但是遇到了困难,结果是我把所有的歌曲都写进了同一个mp3文件,我眼看着同一个mp3文件不断变大,于是中断程序,试听这个mp3文件,效果是一个mp3文件里有多首歌。我想,以后可以用这个方法把同一个人的多首歌合并到一个mp3文件里做成一张专辑,比用剪辑软件之类的效率高很多。但本次我不打算这么干。
如下图,这个文件里包含了三首歌。
下面的代码是我定义下载一首歌曲这个动作的函数。
def download_music(songlink, songname):
res = requests.get(songlink)
music = res.content
#songname1 = songname.strip('\t')
# with open(r'H:/Python学习实践/url_download_mp3/'+songname+'.mp3', 'ab')as file:
with open(os.getcwd() + '\\' + songname.replace('\t', '').replace('/', '').replace('?', '') + '.mp3', 'ab')as file:
file.write(music)
file.flush()
我在csdn网站搜索到博主下载一首歌曲的代码,进行借鉴。
由于我的歌名txt文件里每行数据里都有几个制表符,所以用了strip(’\t’)这个方法把制表符去掉了。
下载音乐的动作实际上就是:
1、用requests.get()方法进入某个链接。
2、用content语句获得这个链接里的内容。
3、打开或者新建一个文件。
4、将数据写入这个文件。
在新建一个文件时我遇到了难题。
因为每首歌都要新建一个文件,每个文件都要重命名。怎么自动命名呢。
我发现两个txt文件,每一行的歌曲下载地址和歌曲名都是一一对应的。那么我直接从歌曲名txt文件中提取歌曲名作为这个mp3文件的名字就行了。
经过多次试错,最终尝试用os.getcwd()语句获取程序当前所在的路径,然后用+号进行字符串拼接的操作。
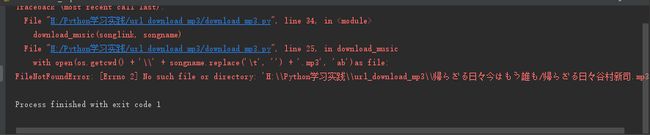
运行程序报错,发现是文件名命名这里出了问题。经历了几次错误。
我本来用r'H:/Python学习实践/url_download_mp3/'解决了语句作为文件名的前面的部分,报错了,于是改用os.getcwd()语句解决了这个报错。
但是之后又遇到了错误,在生成第一首歌的文件时,就报错了,文件夹里还没有生成那首歌的文件,猜想文件名错误,于是用replace()语句去掉了文件名里的制表符’\t’,再次运行,可行。程序完成后,运行下载了几十首歌,报错,发现又是文件名的 问题,于是又用replace()语句去掉了文件名里的’/'字符,后来下载了两百多首歌时,又遇到了报错。看来还有不该出现的字符,暂时没找到python不允许文件名中有哪些字符的表格,这个问题读者可自行继续解决。
3、for循环,反复下载歌曲。
教材上讲的for循环,一般都是一个数组中的一个参数的循环,让这个参数遍历这个数组中的每一条数据。
但是在我这个案例中,我设了两个参数,每一次for循环,都是两个参数分别从两个数组里遍历数据。
琢磨了好一会,找到了zip()方法。
菜鸟教程里给出了zip()函数的一个例子。
意思是,zip()函数里传入两个数组参数a和b,用zip打包成元祖列表,列表里的每一个元祖,对应的是a[n]和b[n]。这就符合了我的要求了。
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
所以我的for循环语句是这样的:
for (songlink, songname) in zip(data1, song_name):
download_music(songlink, songname)
这个程序就完成了,这个程序一口气下载了200多首歌,中途报错是因为歌曲名里有非法字符。我需要用replace()语句把所有的非法字符都提前筛选出去。应该有更高效的方法提前剔除所有非法字符,读者可以继续探索。
我下载200首歌花费了30分钟时间,如果程序报错中断,又要重新再来。于是我们最好还需要增加一些功能,让这个程序在中断工作后,能够重启时从上次工作中断的地方继续工作,而不是从头再来。完成这个任务,似乎需要用到pickle()函数,这次我暂不探索。
还有一种思路,能否让程序先跳过这条错误,继续完成之后的任务。这次我也没有探索,有待读者继续探索。
实现了这个程序之后,未来我要做一个爬取音乐的爬虫,就只需要让爬虫获得音乐的下载地址txt文件,和歌名的txt文件,然后就可以用我这个程序进行下载了。
我最近把微信读书里关于Python爬虫的书都翻了翻。以及看了下豆瓣FM网站的代码,发现要找到每首歌的下载地址,还需要一些周折,目前我看的教程里都没有讲这种方法,目前我看的教程里也没有讲如何批量让微信公众号文章导出pdf时显示图片,他们没有讨论解决懒加载的方法。以及我还想爬微信读书的某一本书的内容,但是看了网页源代码发现,微信读书的反爬虫也挺厉害,每一个字放在一个标签里,并且顺序打乱了。

看来反爬虫技术一直在迭代,我们先尝试些不那么难的东西吧。
我的公众号【江流】研究营销与运营的战略战术,目前在学习Python,欢迎交流。