企业微信群机器人入门
文章目录
- 简介
- 安装
- 初试
- 消息类型
- 文本类型
- Markdown类型
- 图片类型
- 图文类型
- 发送频率
- 定时任务
- 汇总
- IP白名单
- 转拼音
- 参考文献
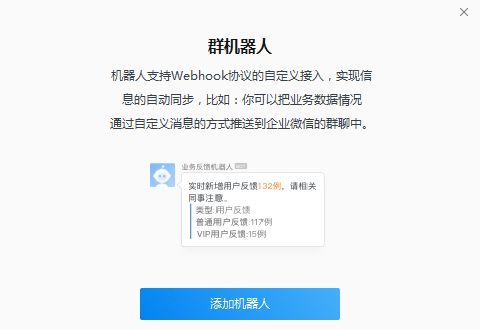
简介
本文发送信息使用Python的网络库 requests
备注:
- 默认只能发送信息
- 接收信息需要企业管理员权限在企业微信管理后台中创建应用
安装
pip install requests
初试
- 新建群。为进行测试,新建一个群,加上自己最少3人
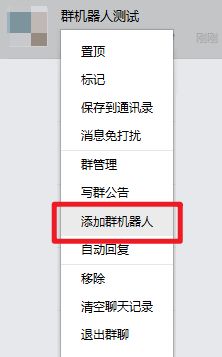
- 添加群机器人。右键 → 添加群机器人
- 基本设置。新创建一个机器人 → 填入机器人名称 → 添加机器人
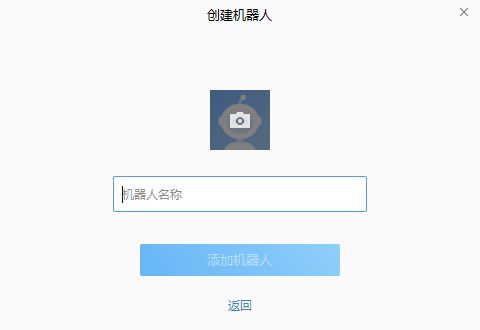
- 保存 Webhook 地址便于后面进行消息发送
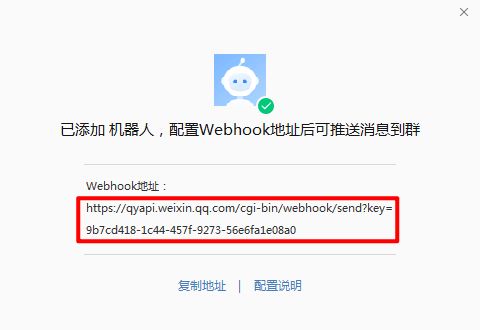
代码,对应填入 Webhook 地址
import json
import requests
URL = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=9b7cd418-1c44-457f-9273-56e6fa1e08a0" # Webhook地址
def message(content):
data = {
"msgtype": "text",
"text": {
"content": content
}
}
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=URL, data=data)
r = json.loads(r.text)
return r
if __name__ == "__main__":
print(message("Hello World!"))
# {'errcode': 0, 'errmsg': 'ok'}
消息类型
目前企业微信群机器人支持消息类型:
- 文本类型
- Markdown类型
- 图片类型
- 图文类型
文本类型
{
"msgtype": "text",
"text": {
"content": "早上好",
"mentioned_list":["wangqing","@all"],
"mentioned_mobile_list":["13000000000","@all"]
}
}
| 参数 | 必须 | 说明 |
|---|---|---|
| msgtype | true | 消息类型,文本类型为text |
| content | true | 文本内容,不超过2048个字节,必须是utf-8 |
| mentioned_list | false | userid列表,@某人,@all为提醒所有人 |
| mentioned_mobile_list | false | 手机号列表,提醒手机号对应的群成员,@all为提醒所有人 |
userid 根据企业决定,我司为姓名的拼音,转拼音见文末
不确定 userid 可以直接用 mentioned_mobile_list ,给电话即可
import json
import requests
URL = "" # Webhook地址
def post(url, data=None):
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def text(content, mentioned_list=[], mentioned_mobile_list=[]):
data = {
"msgtype": "text",
"text": {
"content": content,
"mentioned_list": mentioned_list,
"mentioned_mobile_list": mentioned_mobile_list
}
}
return post(URL, data)
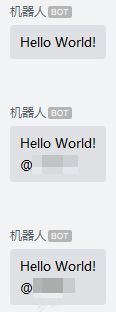
if __name__ == "__main__":
print(text("Hello World!"))
print(text("Hello World!", mentioned_list=["wangqing"]))
print(text("Hello World!", mentioned_mobile_list=["13000000000"]))
Markdown类型
{
"msgtype": "markdown",
"markdown": {
"content": "实时新增用户反馈<font color=\"warning\">132例</font>,请相关同事注意。\n
>类型:<font color=\"comment\">用户反馈</font> \n
>普通用户反馈:<font color=\"comment\">117例</font> \n
>VIP用户反馈:<font color=\"comment\">15例"
}
}
| 参数 | 必须 | 说明 |
|---|---|---|
| msgtype | true | 消息类型,Markdown类型为markdown |
| content | true | Markdown内容,不超过4096个字节,必须是utf-8 |
备注:
- 不可@某人
- 支持的Markdown语法有:标题、加粗、链接、行内代码、引用、字体颜色
import json
import requests
URL = "" # Webhook地址
def post(url, data=None):
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def markdown(markdown):
data = {
"msgtype": "markdown",
"markdown": {
"content": markdown
}
}
return post(URL, data)
if __name__ == "__main__":
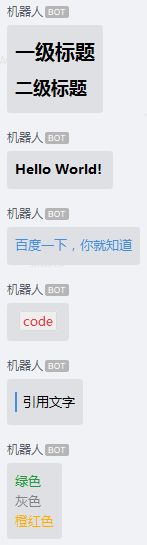
"""Markdown类型"""
print(markdown("# 一级标题\n ## 二级标题"))
print(markdown("**Hello World!**"))
print(markdown("[百度一下,你就知道](http://www.baidu.com/)"))
print(markdown("`code`"))
print(markdown("> 引用文字"))
print(markdown('绿色\n 灰色\n 橙红色'))
图片类型
{
"msgtype": "image",
"image": {
"base64": "DATA",
"md5": "MD5"
}
}
| 参数 | 必须 | 说明 |
|---|---|---|
| msgtype | true | 消息类型,图片类型为image |
| base64 | true | 图片的base64编码 |
| md5 | true | 图片的md5 |
1.jpg

import json
import base64
import hashlib
import requests
URL = "" # Webhook地址
def post(url, data=None):
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def image(file):
with open(file, "rb") as f:
_base64 = f.read()
md5 = hashlib.md5(_base64).hexdigest()
_base64 = base64.b64encode(_base64).decode("utf-8")
data = {
"msgtype": "image",
"image": {
"base64": _base64,
"md5": md5
}
}
return post(URL, data)
if __name__ == "__main__":
"""图片类型"""
print(image("1.jpg"))

图文类型
{
"msgtype": "news",
"news": {
"articles" : [
{
"title" : "中秋节礼品领取",
"description" : "今年中秋节公司有豪礼相送",
"url" : "URL",
"picurl" : "http://res.mail.qq.com/node/ww/wwopenmng/images/independent/doc/test_pic_msg1.png"
}
]
}
}
| 参数 | 必须 | 说明 |
|---|---|---|
| msgtype | true | 消息类型,图文类型为news |
| articles | true | 图文消息,最多支持8条 |
| title | true | 标题,不超过128个字节,超过截断 |
| description | false | 描述,不超过512个字节,超过截断 |
| url | true | 点击后跳转的链接 |
| picurl | false | 图片链接,支持JPG、PNG,大图 1068*455,小图150*150 |
配合图床 或 上传图片接口(需要权限) 使用

import json
import requests
URL = "" # Webhook地址
def post(url, data=None):
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def news(title, url, description=None, picurl=None):
data = {
"msgtype": "news",
"news": {
"articles": [
{
"title": title,
"description": description,
"url": url,
"picurl": picurl
}
]
}
}
return post(URL, data)
if __name__ == "__main__":
"""图文类型"""
print(news("百度一下,你就知道", "http://www.baidu.com/",
description="百度搜索是全球最大的中文搜索引擎,2000年1月由李彦宏、徐勇两人创立于北京中关村",
picurl="https://s1.ax1x.com/2020/07/08/UEL956.jpg"))

发送频率
每个机器人发送频率不超过20条/分钟
定时任务
利用 time.sleep()
import time
import json
import requests
URL = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=9b7cd418-1c44-457f-9273-56e6fa1e08a0" # Webhook地址
def post(url, data=None):
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def text(content, mentioned_list=[], mentioned_mobile_list=[]):
data = {
"msgtype": "text",
"text": {
"content": content,
"mentioned_list": mentioned_list,
"mentioned_mobile_list": mentioned_mobile_list
}
}
return post(URL, data)
def sleep(second=60, minute=0, hour=0, day=0):
secs = second + minute * 60 + hour * 3600 + day * 86400
time.sleep(secs)
if __name__ == "__main__":
"""定时任务"""
from datetime import datetime
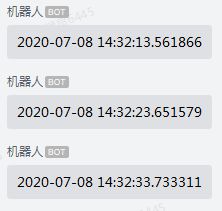
while True:
print(text(str(datetime.now())))
sleep(10)
每10s发一次信息
汇总
import time
import json
import base64
import hashlib
import requests
URL = "" # Webhook地址
def post(url, data=None):
"""发送POST请求"""
data = json.dumps(data, ensure_ascii=False)
data = data.encode(encoding="utf-8")
r = requests.post(url=url, data=data)
r = json.loads(r.text)
return r
def text(content, mentioned_list=[], mentioned_mobile_list=[]):
"""文本类型
:param content: 文本内容
:param mentioned_list: userid列表,@某人,@all为提醒所有人
:param mentioned_mobile_list: 手机号列表,@某人,@all为提醒所有人
"""
data = {
"msgtype": "text",
"text": {
"content": content,
"mentioned_list": mentioned_list,
"mentioned_mobile_list": mentioned_mobile_list
}
}
return post(URL, data)
def markdown(markdown):
"""Markdown类型
:param markdown: Markdown内容。支持标题、加粗、链接、行内代码、引用、字体颜色
"""
data = {
"msgtype": "markdown",
"markdown": {
"content": markdown
}
}
return post(URL, data)
def image(file):
"""图片类型
:param file: 图片路径
"""
with open(file, "rb") as f:
_base64 = f.read()
md5 = hashlib.md5(_base64).hexdigest()
_base64 = base64.b64encode(_base64).decode("utf-8")
data = {
"msgtype": "image",
"image": {
"base64": _base64,
"md5": md5
}
}
return post(URL, data)
def news(title, url, description=None, picurl=None):
"""图文类型
:param title: 标题
:param url: 点击后跳转的链接
:param description: 描述
:param picurl: 图片链接
"""
data = {
"msgtype": "news",
"news": {
"articles": [
{
"title": title,
"description": description,
"url": url,
"picurl": picurl
}
]
}
}
return post(URL, data)
def sleep(second=60, minute=0, hour=0, day=0):
"""定时任务"""
secs = second + minute * 60 + hour * 3600 + day * 86400
time.sleep(secs)
if __name__ == "__main__":
"""文本类型"""
print(text("Hello World!"))
print(text("Hello World!", mentioned_list=["wangqing"]))
print(text("Hello World!", mentioned_mobile_list=["13000000000"]))
"""Markdown类型"""
print(markdown("# 一级标题\n ## 二级标题"))
print(markdown("**Hello World!**"))
print(markdown("[百度一下,你就知道](http://www.baidu.com/)"))
print(markdown("`code`"))
print(markdown("> 引用文字"))
print(markdown('绿色\n 灰色\n 橙红色'))
"""图片类型"""
print(image("1.jpg"))
"""图文类型"""
print(news("百度一下,你就知道", "http://www.baidu.com/",
description="百度搜索是全球最大的中文搜索引擎,2000年1月由李彦宏、徐勇两人创立于北京中关村",
picurl="https://s1.ax1x.com/2020/07/08/UEL956.jpg"))
"""定时任务"""
from datetime import datetime
while True:
print(text(str(datetime.now())))
sleep(10)
IP白名单

转拼音
安装
pip install pypinyin
函数
from itertools import chain
from pypinyin import pinyin, Style
def to_pinyin(s):
return "".join(chain.from_iterable(pinyin(s, style=Style.TONE3)))
参考文献
- 如何配置群机器人? - 企业微信
- Python HTTP库——requests
- Python3-定时任务四种实现方式
- 机器人图标
- we-work-bot: 轻量级企业微信群聊机器人框架
- 企业微信【群机器人】轻松上手,企业应用App接收和回复用户消息
- base64数据编码 — Python文档
- hashlib安全哈希与消息摘要 — Python文档
- 路过图床 - 免费图片上传