【JavaWeb_Part02】与 MySQL 人鬼情未了
开篇
在上篇文章中,我们已经讲完了 MySQL 的大部分基础用法,并且每个用法都配有截图,理解起来应该不会有那么困难。对于初学者来说,可能会有点混乱,觉得难以理解。其实不然,如果你仔细看了上一篇文章,你会发现 MySQL 的一些基础用法其实都是一个套路,只要你理解了一个,其他的也都挺好理解的。
如果你想要去看一下第一篇文章,那么请用力戳我 。
上面已经说完了基础用法,那我们就接着上篇来一点复杂的东西讲讲吧。
MySQL 实操
1. MySQL 操作中的关键字
1.1 Join 连接查询
在前一篇文章中,我们大部分的操作都是单表操作,现在我们来尝试一下连接两张表进行查询。为此,我另外新建了一张表名为 ucount,里面有两个字段,name 以及 count。count 表的一些操作我在这里就不写了,如果有不明白的,请去看上一篇文章。
//连接两张表进行连接查询
select a.name, b.count from user a, ucount b where a.name = b.name;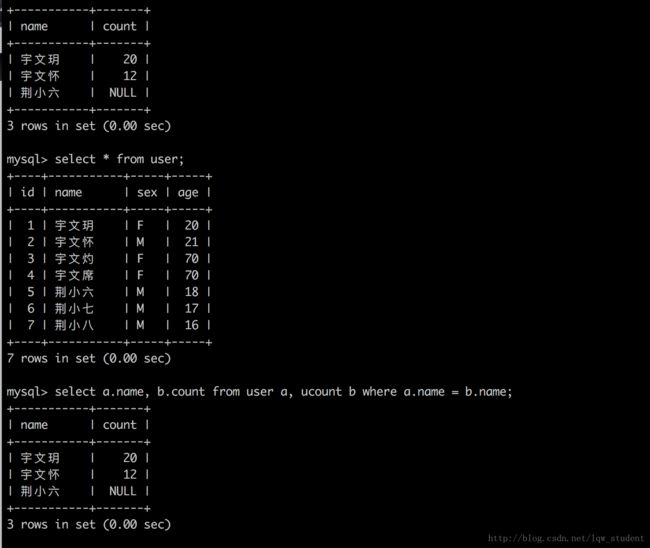
从上面我们已经看到结果了,下面我把上面的 SQL 语句解释一下。可能有些人看到 a,b 就有点懵。先别急,我们来一起捋一捋这段跟鬼似的 SQL 语句。把其他的先抛开不看,我们只看 user 到 where 之间的这段 SQL。
user a, ucount b
单独抽出来可能好理解一点,这就是给表起一个别名,方便书写 SQL 语句而已,并没有多高深的技术。知道了别名后,上面的那段代码就是小意思了。意思就是“查询 user 表中的 name 和 ucount 表中的 count ,从 表 user(a)和表 ucount(b)中查询,查询条件就是 user(a) 表中的 name 和 ucount(b) 表中的 name 相同”。
当然如果你实在是不能理解别名的含义,可以不使用别名查询也是可以的。
select user.name, ucount.count from user, ucount where user.name = ucount.name;
你会发现,两次查询的结果是相同的。只不过用别名简化了 SQL 语句。(实际上也没有简化多少,自己骗自己,假装简化了。)
1.2 Alter 关键字
为了测试 alter 关键字的作用,我这里新建一个表 test。
删除表中的某一个字段
alter table table_name drop field;alter table test drop i; //删除表 test 中的 i 这个字段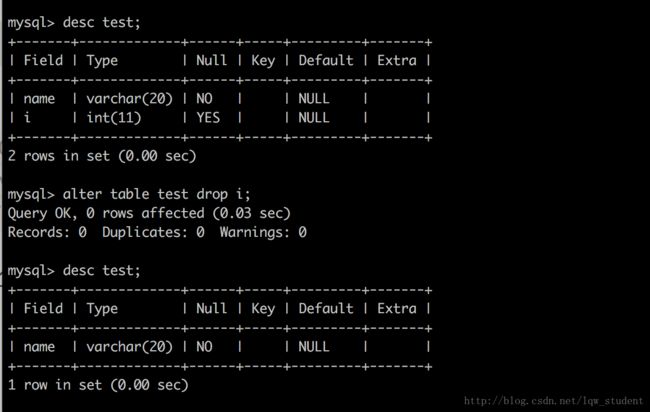
有删除,就肯定会有增加,下面我们看一下增加字段的方法
给表增加一个字段
alter table table_name add field type; //field 字段名称,Type 字段类型alter table test add c int; //增加一个 int 类型的字段 c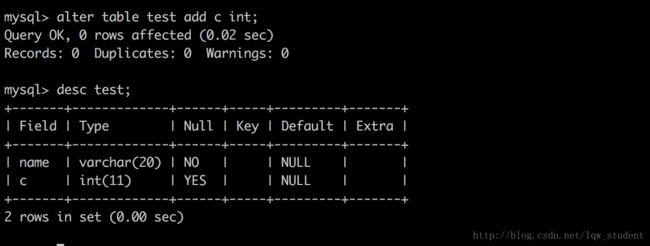
修改表的字段类型
alter table table_name modify field type; //field 字段名称 Type 字段类型alter table test modify c varchar(20); //修改字段 c 的类型为 varchar(20)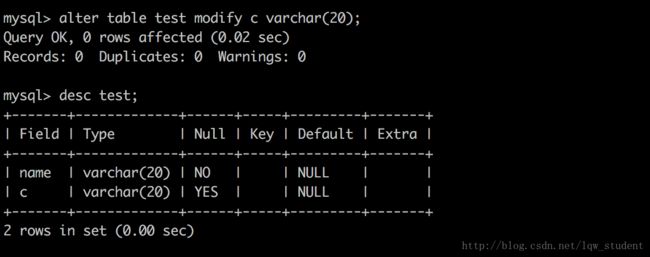
同时修改 field 和 Type
//同时修改字段名称 field 和类型 type
alter table table_name change old_field_name new_field_name type; alter table test change c d Integer; //将字段名为 c 更改成 d,同时将类型更改成 Integer
修改表名
alter table old_table_name rename new_table_name; alter table test rename test1; //将表名为 test 修改成 test1;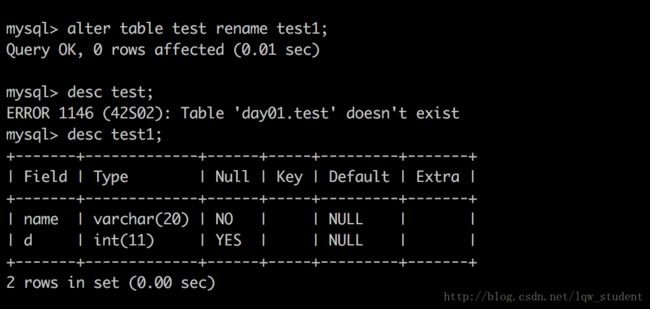
好了,alter 关键字暂时就讲这么多,其他的也暂时用不到。
1.3 正则表达式(regexp)
前面我们就已经说了可以模糊查询,还记得是通过哪一个关键字查询的么?没错,是 like。现在我们来讲一下正则表达式,它也是可以进行模糊查询的。MySQL 中的正则表达式不多,常用的就下面几个,我现在在下面列举出来。
^ 开始的一个字符串
$ 结束的一个字符串
. 任意单个字符
[...] 方括号中列出的任何字符
[^...] 任何字符方括号之间不会被列出
p1|p2|p3 交替;匹配的任何模式 p1, p2, 或 p3
* 前一个元素的零个或多个实例
+ 前面元素的一或多个实例
{n} 前一个元素的n个实例
{m,n} 前一个元素的 m 到 n 个实例
//查找所有以“荆”开头的字段
select name from user where name regexp "^荆";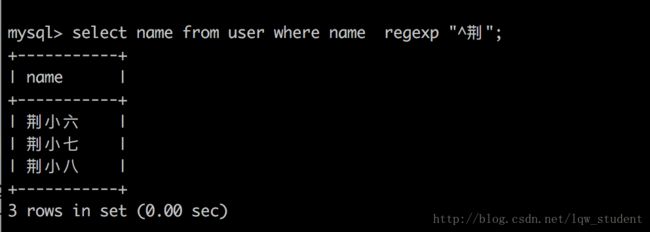
//查找所有以“八”结尾的字段
select name from user where name regexp "八$";
//查找所以名字中包含“文”的字段
select name from user where name regexp "[文]";
其他的我就不列举了,有兴趣的可以自己去尝试一下。
2. MySQL 中的事务管理
2.1 什么是事务?
事务是数据库处理操作,其中执行就好像它是一个单一的一组有序的工作单元。换言之,事务将永远不会是完全的,除非在组内每个单独的操作是成功的。如果事务中的任何操作失败,整个事务将失败。
实际上,许多SQL查询组成到一个组,将执行所有这些一起作为事务的一部分。
2.2 事务的特性
事务具有以下四个标准属性,通常由首字母缩写ACID简称:
原子性: 确保了工作单位中的所有操作都成功完成; 否则,事务被中止,在失败时会被回滚到事务操作以前的状态。
一致性:可确保数据库在正确的更改状态在一个成功提交事务。
隔离: 使事务相互独立地操作。
持久性: 确保了提交事务的结果或系统故障情况下仍然存在作用。
在 MySQL 中,事务以 BEGIN WORK 语句开始开始工作,并使用 COMMIT 或 ROLLBACK 语句结束。SQL 命令在开始和结束语句之间构成大量事务。
2.3 提交事务和回滚事务
这两个关键字 Commit 和 Rollback 主要用于 MySQL 的事务。
当一个成功的事务完成后,COMMIT 命令发出的变化对所有涉及的表将生效。
如果发生故障,ROLLBACK 命令发出后,事务中引用的每个表将恢复到事务开始之前的状态。
可以通过设置 AUTOCOMMIT 这个会话变量控制事务的行为。如果 AUTOCOMMIT 设置为 1 (默认值),那么每个 SQL 语句(在事务或不在事务)被认为是一个完整的事务并提交,在默认情况下是在当它完成时。当 AUTOCOMMIT 设置为 0 ,通过发出 SET AUTOCOMMIT = 0 命令, 随后的一系列语句就像一个事务,但并没有任何活动被提交直到一个明确的发出 COMMIT 语句。
结语
关于 MySQL 的知识其实还有很多,但是我们这两部分讲的知识已经足以让我们应付接下来的 Web 学习计划,所以下面的东西就暂时不讲了,如果后面需要 MySQL 这部分的知识,我们再回过头来了解这部分知识,有了一定基础的我们,相信那个时候再来了解这部分知识一定是手到擒来的。
最后说明一下,本人能力有限,写出来的东西难免会有错误,如有错误,还希望不吝赐教。同时也欢迎学习的小伙伴与我一起交流讨论。