第二天——召回算法和业界最佳实践(一)
目录
1推荐系统的Match模块介绍
1.1业界通⽤推荐系统架构
1.2Match算法典型应用
2Collaborative Filtering 算法介绍
2.1Collaborative Filtering 定义
2.2基于共现关系的Collaborative Filtering算法
2.2.1 User-based CF(基于用户的协同过滤算法)
2.2.2 Item-based CF(基于物品的协同过滤算法)
2.3UserCF、ItemCF 优缺点对⽐
2.4最新CF算法实践
1推荐系统的Match模块介绍
1.1业界通⽤推荐系统架构
Deep Neural Networks for YouTube Recommendations, RecSys ’16

Match & Rank
- 定义:Match基于当前user(profile、history) 和context,快速在全库⾥找到TopN最相关的item,给Rank来做⼩范围综合多⽬标最⼤化。
- 通常做法:通常情况下,⽤各种算法做召回,⽐如user/item/model-based CF,Contentbased,Demographic-based、DNN-Embedding-based等等,做粗排之后交由后⾯的Rank层做更精细的排序,最终展现TopK item。
1.2Match算法典型应用
- 猜你喜欢 :多样推荐

- 相似推荐 :看了还看

- 搭配推荐 :买了还买

2Collaborative Filtering 算法介绍
2.1Collaborative Filtering 定义
- Collaborative Filtering (CF) is the most well-known technique for recommendation.
CF makes predictions (filtering) about a user’s interest by collecting preferences information from many users (collaborating)
- 数学形式化: 矩阵补全问题

2.2基于共现关系的Collaborative Filtering算法
基于邻域的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。
2.2.1 User-based CF(基于用户的协同过滤算法)
多⽤于挖掘那些有共同兴趣的⼩团体,通常新颖性较好,但是准确性稍差
基础算法:
当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
从上面的描述中可以看到,基于用户的协同过滤算法主要包括两个步骤:
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v) 为用户v曾经有过正反馈的物品集合。那么,我们可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度:

或者通过余弦相似度计算:

下面以图中的用户行为记录为例,举例说明UserCF计算用户兴趣相似度的例子。在该例中,用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算用 户A和用户B的兴趣相似度为:

同理,我们可以计算出用户A和用户C、D的相似度:
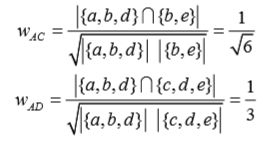

def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W同样以图2-6中的用户行为为例解释上面的算法。首先,需要建立物品—用户的倒排表(如图 2-7所示)。然后,建立一个4×4的用户相似度矩阵W,对于物品a,将W[A][B]和W[B][A]加1,对 于物品b,将W[A][C]和W[C][A]加1,以此类推。扫描完所有物品后,我们可以得到最终的W矩阵。 这里的W是余弦相似度中的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度。


利用上述算法,可以给图2-7中的用户A进行推荐。选取K=3,用户A对物品c、e没有过行为, 因此可以把这两个物品推荐给用户A。根据UserCF算法,用户A对物品c、e的兴趣是:

用户相似度计算的改进:
上一节介绍了计算用户兴趣相似度的最简单的公式(余弦相似度公式),但这个公式过于粗糙,本节将讨论如何改进该公式来提高UserCF的推荐性能。 首先,以图书为例,如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似, 因为绝大多数中国人小时候都买过《新华字典》。但如果两个用户都买过《数据挖掘导论》,那可以认为他们的兴趣比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。因此,John S. Breese在论文①中提出了 如下公式,根据用户行为计算用户的兴趣相似度:

2.2.2 Item-based CF(基于物品的协同过滤算法)
基于物品的协同过滤(item-based collaborative filtering)算法是目前业界应用最多的算法。 无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法。本节将从基础 的算法开始介绍,然后提出算法的改进方法,并通过实际数据集评测该算法
基础算法:
基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。 比如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过,ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品 B。基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供推荐解释,比如给用户推荐《天龙八部》的解释可以是因为用户之前喜欢《射雕英雄传》。如2-10所示,Hulu在个性化视 频推荐利用ItemCF给每个推荐结果提供了一个推荐解释,而用于解释的视频都是用户之前观看或 者收藏过的视频。

基于物品的协同过滤算法主要分为两步:
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成推荐列表。
物品的相似度:

这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。 从上面的定义可以看到,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。这里面蕴涵着一 个假设,就是每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表, 那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它 们就可能属于同一个领域,因而有很大的相似度。 和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即 对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两 两在共现矩阵C中加1。

图2-11是一个根据上面的程序计算物品相似度的简单例子。图中最左边是输入的用户行为记 录,每一行代表一个用户感兴趣的物品集合。然后,对于每个物品集合,我们将里面的物品两两 加一,得到一个矩阵。最终将这些矩阵相加得到上面的C矩阵。其中C[i][j]记录了同时喜欢物品i 和物品j的用户数。最后,将C矩阵归一化可以得到物品之间的余弦相似度矩阵W。


用户活跃度对物品相似度的影响:
假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么, 他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本。从前面 对ItemCF的讨论可以看到,这意味着因为存在这么一个用户,有80万本书两两之间就产生了相似 度,也就是说,内存里即将诞生一个80万乘80万的稠密矩阵。 另外可以看到,这个用户虽然活跃,但是买这些书并非都是出于自身的兴趣,而且这些书覆 盖了当当网图书的很多领域,所以这个用户对于他所购买书的两两相似度的贡献应该远远小于一 个只买了十几本自己喜欢的书的文学青年。 John S. Breese在论文①中提出了一个称为IUF(Inverse User Frequence),即用户活跃度对数的 倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF 参数来修正物品相似度的计算公式:

当然,上面的公式只是对活跃用户做了一种软性的惩罚,但对于很多过于活跃的用户,比如 上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直 接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
物品相似度的归一化:
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。 其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度 矩阵w':
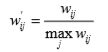
其实,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。 一般来说,物品总是属于很多不同的类,每一类中的物品联系比较紧密。举一个例子,假设在一个电影网站中,有两种电影——纪录片和动画片。那么,ItemCF算出来的相似度一般是纪录片和 纪录片的相似度或者动画片和动画片的相似度大于纪录片和动画片的相似度。但是纪录片之间的相似度和动画片之间的相似度却不一定相同。假设物品分为两类——A和B,A类物品之间的相似度为0.5,B类物品之间的相似度为0.6,而A类物品和B类物品之间的相似度是0.2。在这种情况下, 如果一个用户喜欢了5个A类物品和5个B类物品,用ItemCF给他进行推荐,推荐的就都是B类物品, 因为B类物品之间的相似度大。但如果归一化之后,A类物品之间的相似度变成了1,B类物品之 间的相似度也是1,那么这种情况下,用户如果喜欢5个A类物品和5个B类物品,那么他的推荐列表中A类物品和B类物品的数目也应该是大致相等的。从这个例子可以看出,相似度的归一化可以提高推荐的多样性。
那么,对于两个不同的类,什么样的类其类内物品之间的相似度高,什么样的类其类内物品相似度低呢?一般来说,热门的类其类内物品相似度一般比较大。如果不进行归一化,就会推荐 比较热门的类里面的物品,而这些物品也是比较热门的。因此,推荐的覆盖率就比较低。相反, 如果进行相似度的归一化,则可以提高推荐系统的覆盖率。
2.3UserCF、ItemCF 优缺点对⽐

2.4最新CF算法实践
基于ItemCF的推荐算法调⽤⽰意图

改进版 I2I
- motivation:热门⽤户、哈利波特效应、⽤户⾏为缺乏考虑
- solution:热门⽤户降权、热门Item降权
实时I2I
- motivation:新品推荐问题
- Solution:实时增量i2i
Hybrid I2I
- motivation:⽆监督学习,⽆法刻画场景差异
- solution:有监督Hybrid多种i2i算法