镇楼图

官方说明:
CoreML让你将很多机器学习模型集成到你的app中。除了支持层数超过30层的深度学习之外,还支持决策树的融合,SVM(支持向量机),线性模型。由于其底层建立在Metal 和Accelerate等技术上,所以可以最大限度的发挥CPU和GPU的优势。你可以在移动设备上运行机器学习模型,数据可以不离开设备直接被分析。
Vision:这部分是关于图像分析和图像识别的。其中包括人脸追踪,人脸识别,航标(landmarks),文本识别,区域识别,二维码识别,物体追踪,图像识别等。
其中使用的模型包括:Places205-GoogLeNet,ResNet50,Inception v3,VGG16。
这些模型最小的25M,对于app还是可以接受的,最大的有550M,不知道如何集成到app中。
NLPAPI:这部分是自然语言处理的API,包括语言识别,分词,词性还原,词性判定,实体辨识。
咱们先从比较简单的vision框架开始说起
一个大概的流程就是 :
第一步:先创建一个 识别请求(VNRequest的子类,具体要实现什么功能,就选择那个子类,比如区域识别就使用VNDetectRectanglesRequest,人脸识别就使用VNDetectFaceRectanglesRequest),
使用的构造器就是VNRequest类的构造器
public init(completionHandler: Vision.VNRequestCompletionHandler? = nil)
第二步:搞定构造方法中的这个参数completionHandler, completionHandler是在图片分析处理完成以后进行的回调的,也就是说咱们希望获得的数据就由他来提供,Vision.VNRequestCompletionHandler 的定义如下:
public typealias VNRequestCompletionHandler = (VNRequest, Error?) -> Swift.Void
第三步:创建一个执行一个加载目标图片并执行“识别请求(VNRequest)”的handler,创建这个handler需要使用的类是:VNImageRequestHandler,brief:Performs requests on a single image.
构造方法蛮多的,就不一一解释了,最主要的是把要处理的图片扔给它就OK了,
第四步:前面的工作做完就可以开始执行了
open func perform(_ requests: [VNRequest]) throws
他的参数就是咱们第一步创建的识别请求
下面来一段最简单的代码试一下
let faceDetectRequest = VNDetectFaceRectanglesRequest { (request, error) in
//创建人脸识别请求
//VNDetectFaceRectanglesRequest这个类继承自VNImageBasedRequest,而VNImageBasedRequest继承自VNRequest
//关于VNRequest的几个属性呢都比较简单,一看即懂。比较重要的呢就是results这个集合,这个集合中装的就是vision框架后者model处理后的结果数据,具体使用后面再说
guard let detectFacerequest = request as? VNDetectFaceRectanglesRequest else
{
//获得被执行的识别请求,装的就是vision框架后者model处理后的结果数据
return
}
guard let results = detectFacerequest.results else { return}
//获取数据
for result in results{
guard let faceObservation = result as? VNFaceObservation else{return}
//results中元素一般情况下是VNObservation的子类对象,VNObservation中最重要的属性就是confidence,代表了识别结果的可能性,results数组中数据的顺序也是按照confidence进行排列的。VNFaceObservation继承自VNDetectedObjectObservation,VNDetectedObjectObservationopen中比较重要的属性是 var boundingBox: CGRect { get },boundingBox就是图片中人脸的位置,只不过要注意的就boundingBox是一个相对值,大于0小于1,实际使用需要进行转换,并且origin是从左下角开始的
let imageWidth = CGFloat(375.0)
let imageHeight = CGFloat(375.0 * (self.imageView.image?.size.height)! / (self.imageView.image?.size.width)!)
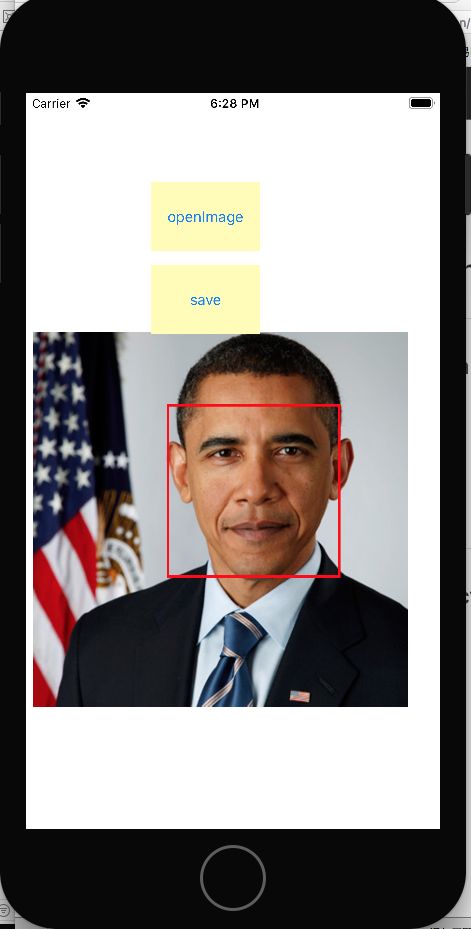
print("x:",(1.0-faceObservation.boundingBox.origin.x) * imageWidth,"y:",(1.0-faceObservation.boundingBox.origin.y)*imageHeight,"width:",faceObservation.boundingBox.size.width * imageWidth,"height:",faceObservation.boundingBox.height * imageHeight)
let boundingFrame = CGRect(x: faceObservation.boundingBox.origin.x * imageWidth, y: (1.0-faceObservation.boundingBox.origin.y)*imageHeight - faceObservation.boundingBox.height * imageHeight, width: faceObservation.boundingBox.size.width * imageWidth, height: faceObservation.boundingBox.height * imageHeight);
//这些代码就是对boundingBox进行转换的
let boundingView = UIView(frame: boundingFrame);
boundingView.backgroundColor = .clear;
boundingView.layer.borderColor = UIColor.red.cgColor;
boundingView.layer.borderWidth = 2.5
self.imageView.addSubview(boundingView)
}
}
let handle = VNImageRequestHandler(cgImage: imageData!)
//创建一个执行一个加载目标图片并执行“识别请求(VNRequest)”的handler
try! handle.perform([faceDetectRequest])
//执行识别请求
来一张效果图
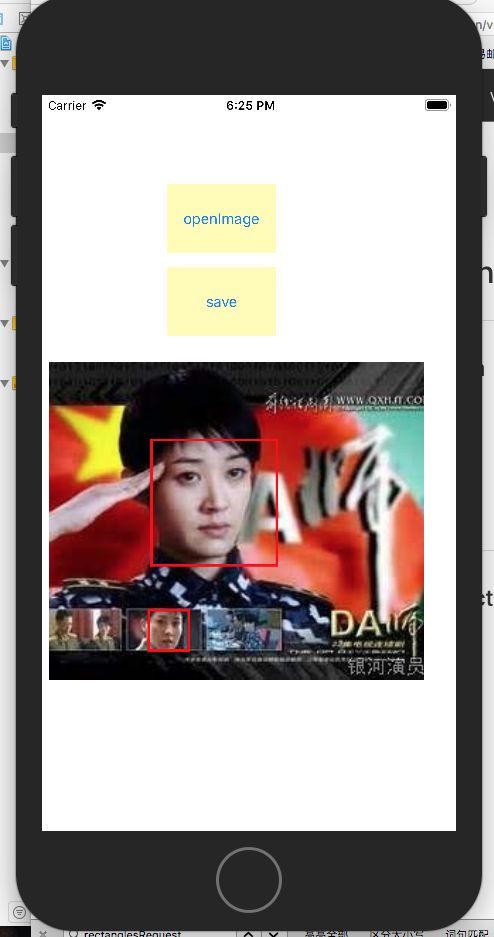
9.12更新
人脸特征识别
先来张效果图

再来一张

人脸特征识别需要使用的类:VNDetectFaceLandmarksRequest VNFaceObservation VNFaceLandmarks2D VNFaceLandmarkRegion2D
还是按照原先的套路,咱们踏着小碎步一步一步来。。。
Step1:创建识别请求,这次要用的识别请求是:VNDetectFaceLandmarksRequest
let faceLandmarksRequest = VNDetectFaceLandmarksRequest(completionHandler: faceLandmarkdsBundler);
Step2:顺手创建一个回调handler
let faceLandmarkdsBundler : (VNRequest,Error?) -> Void = { (request, error) in
guard let landmarksRequest = request as? VNDetectFaceLandmarksRequest else {print("analysis error");return}
guard let results = landmarksRequest.results else {print("data error");return}
for obj in results
{
guard let faceObservation = obj as? VNFaceObservation else {continue}
//前面这半段图样图森破,就不说了
loadFaceFeatures(feature: faceObservation.landmarks!.allPoints!)
}
}
详细说一下landmarks
这个属性是VNFaceLandmarks2D类型的,声明为:
open var landmarks: VNFaceLandmarks2D? { get }
landmarks在它所在的VNDetectFaceLandmarksRequest对象perform前为nil,perform以后,也就是说在回调的request中lanmarks才会有数据,具体数据就是人脸所有特征的点相对于图片的坐标。

allPoints : 所有特征点
faceContour:轮廓
leftEye:左眼
。。。
所有的特征都是VNFaceLandmarkRegion2D 类型的,在VNFaceLandmarkRegion2D
中,一个比较重要的属性和一个方法:
open var __normalizedPoints: UnsafePointer{ get }
open func __pointsInImage(imageSize: CGSize) -> UnsafePointer
这两个都是指针类型,指向的是一个装着特征点坐标的数组,第一个是相对于图片坐标系并且以1.0为图片尺寸的数组,第二个,是根据图片实际尺寸计算相对于图片坐标系并且单位为像素的数组。
Final Step:创建VNImageRequestHandler,然后perform 特征识别的request就ok了!