千万级MySQL分页优化
https://blog.csdn.net/persistencegoing/article/details/84376427
对于只有几万条数据的表这样做当然没问题,也不会在用户体验上有何不妥,但是要是面对成百万上千万的数据表时,这样就不足以满足我们的业务需求了,如何做到对千万级数据表进行高效分页?首先要学会使用 explain 对你的SQL进行分析,如果你还不会使用 explain 分析SQL语句 传送门 http://blog.itpub.net/559237/viewspace-496311
一丶合理使用 mysql 查询缓存 结合复合索引进行查询分页
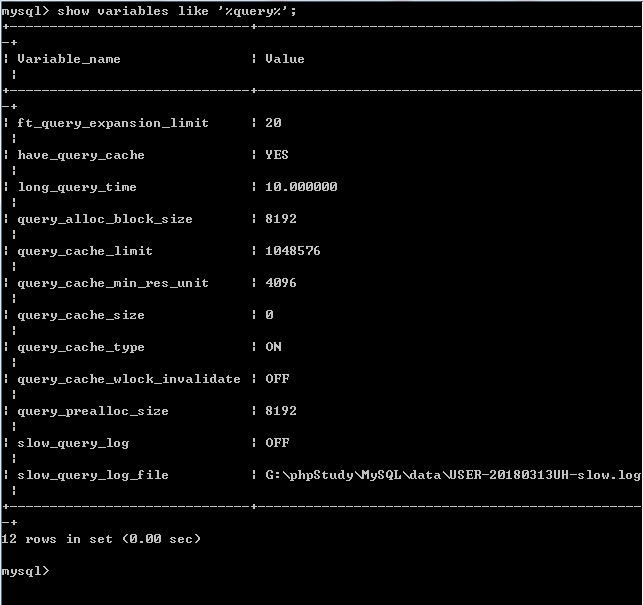
开启查询缓存的原因是为了增大吞吐率,提升查询的性能
query_caceh_type 是否开启查询缓存
0 表示不开启查询缓存,
1 表示始终开启查询缓存(不要缓存使用sql_no_cache) ,
2 表示按需开启查询缓存 (需要缓存使用 sql_cache)。
query_cache_size 给缓存分配的最大内存空间
对于查询缓存的一些操作。
FLUSH QUERY CACHE; // 清理查询缓存内存碎片。
RESET QUERY CACHE; // 从查询缓存中移出所有查询。
FLUSH tabName; //关闭所有打开的表,同时该操作将会清空查询缓存中的内容。
分页说到底也是查询的一种,既然是查询我们就可以为他设置索引来提高查询速度
https://blog.csdn.net/csdn265/article/details/51789754(复合索引)
二丶SQL语句的优化(不使用索引)
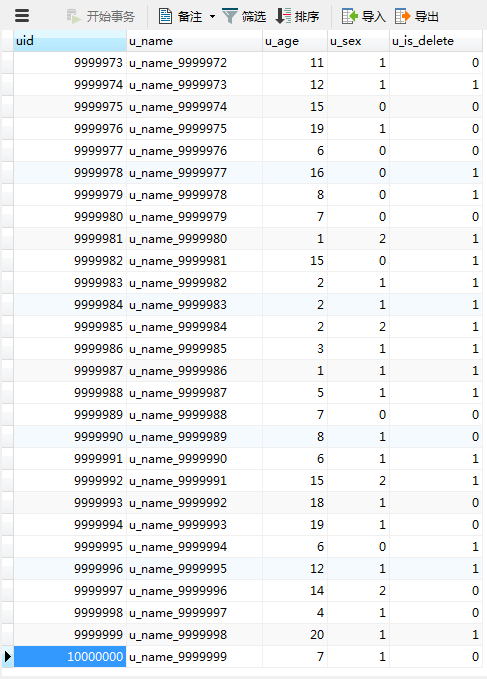
这里有一张千万级别的数据表,表结构如下
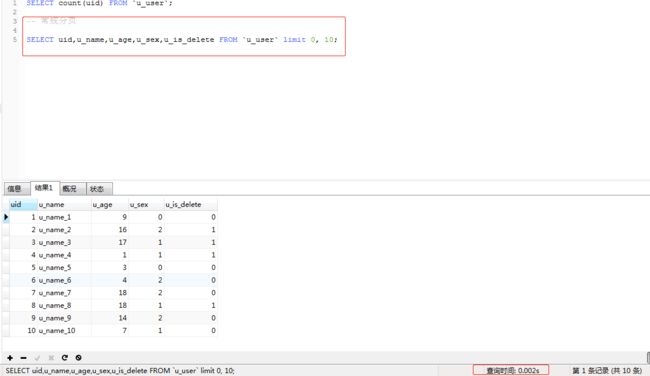
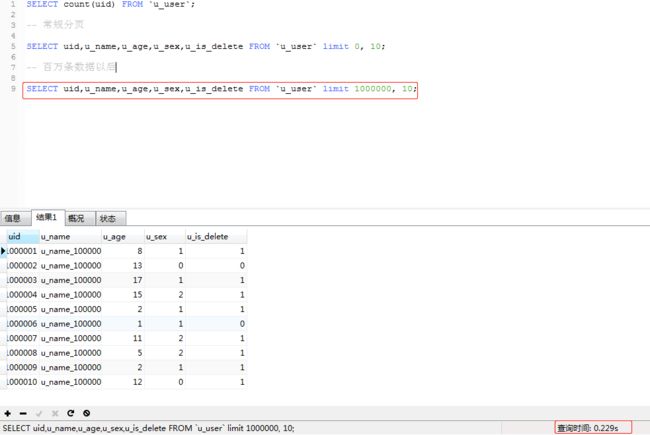
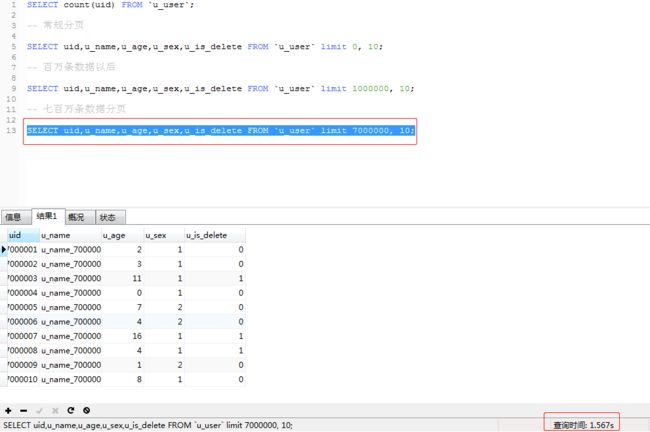

b.先去查询到最大偏移量然后再进行分页,这样看来时间好像变得更长了,显示这种方式不符合我们的场景,对这句SQL再次进行优化 (SELECT uid,u_name,u_age,u_sex,u_is_delete FROM u_user WHERE uid>7000000 LIMIT 10;)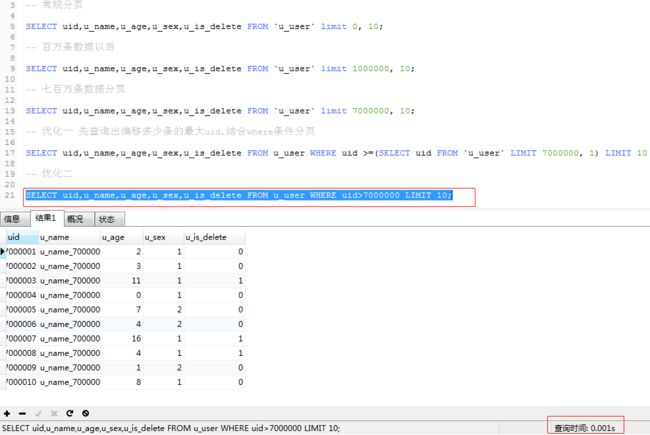
优化三:SELECT * FROM table WHERE id BETWEEN 1000000 AND 1000010; 这个比优化二和三还要快一些
优化二和三有个缺点就是uid中可能有缺码,但是大多数情况下都是修改字段而不会去物理删除,所以还是可以参考
优化四:SELECT * FROM table WHERE id IN(10000, 100000, 1000000...); 这个可以解决优化二和三的缺点(id缺码)但是效率没试过,可以确定的是比limit快
非常棒的查询时间,0.001s,几乎是秒查询,这样即使是千万级的数据表分页起来也能轻松应对
当然,这只是我能想到的实现千万级数据表分页的两种方案,若有其他方式,欢迎评论
希望大家关注我一波,防止以后迷路,有需要的可以加群讨论互相学习java ,学习路线探讨,经验分享与java求职
群号:721 515 304