python基础---进程、线程、协程
pyhon—-进程线程、与协程基础概述
什么是进程?
进程,是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。前面的话我也没懂,用非官方的白话来解释就是——执行中的程序是进程,比如qq不是进程,但是当我们双击qq开始使用它的时候,它就变成了一个进程。我们写的python程序,只有当我们执行它的时候,它才是进程。我们正在执行的IE浏览器,QQ,pycharm都是进程,从操作系统的角度来讲,每一个进程都有它自己的内存空间,进程之间的内存是独立的。
什么是线程?
线程,有时被称为轻量级进程,是程序执行流的最小单元。我们可以理解为,线程是属于进程的,我们平时写的简单程序,是单线程的,多线程和单线程的区别在于多线程可以同时处理多个任务,这时候我们可以理解为多线程和多进程是一样的,我可以在我的进程中开启一个线程放音乐,也可以开启另外的线程聊qq,但是进程之间的内存独立,而属于同一个进程多个线程之间的内存是共享的,多个线程可以直接对它们所在进程的内存数据进行读写并在线程间进行交换。
进程与线程之间的关系
先推荐一个链接,这篇文章用漫画的形式讲解了进程与线程的关系:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
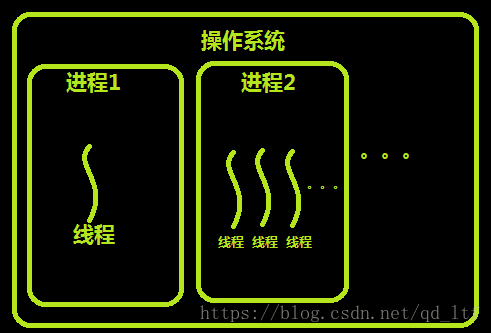

如上图,假装我们已经看完了上面的连接。这里来为偷懒的同志们解释一下,左图为进程与线程之间的关系。每个进程都有属于自己的线程,至少一个。右图是进程、单线程进程,多线程进程在内存中的情况。
关于python线程的那个传说:
在python界一直有着一个古老的传说,那就是python的多线程是鸡肋,那么这个传说的信度到底有多少呢?如果我们的代码是CPU密集型(涉及到大量的计算),多个线程的代码很有可能是线性执行的,所以这种情况下多线程是鸡肋,效率可能还不如单线程,因为有context switch(其实就是线程之间的切换和线程的创建等等都是需要消耗时间的);但是:如果是IO密集型,多线程可以明显提高效率。例如制作爬虫,绝大多数时间爬虫是在等待socket返回数据。这个时候C代码里是有release GIL的,最终结果是某个线程等待IO的时候其他线程可以继续执行。
那么,为什么我们大python会这么不智能呢?我们都知道,python是一种解释性语言,在python执行的过程中,需要解释器一边解释一边执行,我们之前也介绍了,同一个进程的线程之间内存共享,那么就会出现内存资源的安全问题,python为了线程安全,就设置了全局解释器锁机制,既一个进程中同时只能有一个线程访问cpu。作为解释型语言,python能引入多线程的概念就已经非常不易了,目前看到的资料php和perl等多线程机制都是不健全的。解释型语言做多线程的艰难程度可以想见。。。具体下面的链接推荐:python的最难问题。
正是由于python多线程的缺陷,我们在这里需要引入协成的概念。
什么是协程?
协程是一种用户态的轻量级线程。如果说多进程对于多CPU,多线程对应多核CPU,那么事件驱动和协程则是在充分挖掘不断提高性能的单核CPU的潜力。我们既可以利用异步优势,又可以避免反复系统调用,还有进程切换造成的开销,这就是协程。协程也是单线程,但是它能让原来要使用异步+回调方式写的非人类代码,可以用看似同步的方式写出来。它是实现推拉互动的所谓非抢占式协作的关键。对于python来说,由于python多线程中全局解释器导致的同时只能有一个线程访问cpu,所以对协程需求就相比于其他语言更为紧迫。
进程、线程与协程
从硬件发展来看,从最初的单核单CPU,到单核多CPU,多核多CPU,似乎已经到了极限了,但是单核CPU性能却还在不断提升。server端也在不断的发展变化。如果将程序分为IO密集型应用和CPU密集型应用,二者的server的发展如下:
IO密集型应用: 多进程->多线程->事件驱动->协程
CPU密集型应用:多进程–>多线程程
python——进程基础
我们现在都知道python的多线程是个坑了,那么多进程在这个时候就变得很必要了。多进程实现了多CPU的利用,效率简直棒棒哒~~~
拥有一个多进程程序:

multiprocess Code 1
按照上面的方法,我们就在自己的代码中启动了一个子进程,需要注意的是要想启动一个子进程,必须加上那句if name == “main”,否则就会报错。 查看了官方文档说:Safe importing of main module,Make sure that the main module can be safely imported by a new Python interpreter without causing unintended side effects (such a starting a new process).大概就是说,如果我们必须确定当前已经引入了主模块,来避免一些非预期的副作用。。。总之,加上!就对了!!!
进程池:

multiprocessing Pool Code
上图中的方法就是进程池的使用,这里重点的介绍一些进程池相关的方法。
首先,我们为进程注入func,有两种方式:apply_async表示异步,就是子进程接收到请求之后就各自去执行了,而apply表示同步,子进程们将一个一个的执行,后一个子进程的执行永远以前一个子进程的结束为信号,开始执行。还是吃饭的例子。。。异步就是当我通知子进程要去吃饭的时候,他们就同时去吃饭了,同步就是他们必须一个一个的去,前一个没回来,后一个就不能去。
close方法:说关闭进程池,至此,进程池中不在有进程可以接受任务。
terminate和join是一对方法,表示的内容截然相反,执行terminate是结束当前进程池中的所有进程,不管值没执行完。join方法是阻塞主进程,等待子进程执行完毕,再继续执行主进程。需要注意的是:这两个方法都必须在close方法之后执行。当然我们也可以不执行这两个方法,那么子进程和主进程就各自执行各自的,无论执行到哪里,子进程会随着主进程的结束而结束。。。
获取进程池中进程的执行结果:
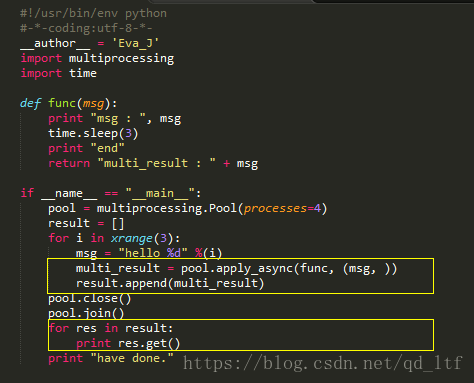
multiprocessing get result example Code
进程之间的内存共享:
我们之前说过,正常情况下,每个进程都拥有自己的内存空间,因此进程间的内存是无法共享的。
但是python却提供了我们方法,让我们程序的子进程之间实现简单的数据共享。
一个是Array数组,一个是multiprocessing模块中的Manager类。需要注意的是,Array数组的大小必须固定,Manager需要在linux系统下运行。
python——线程与多线程基础
我们之前已经初步了解了进程、线程与协程的概念,现在就来看看python的线程。下面说的都是一个进程里的故事了,暂时忘记进程和协程,先来看一个进程中的线程和多线程。这篇博客将要讲一些单线程与多线程的基础,它们在执行中对cpu资源的分配,帮助还不了解多线程的小伙伴一招get写多线程代码的技能。已经了解的请自行跳过。
单线程
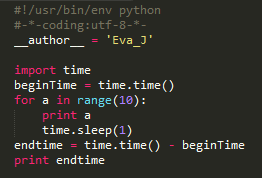


从上面的图中我们可以看出,这段代码执行了10秒多,这就是一段单单线程的一条道走到黑的代码,它们顺序执行,该sleep的时候就sleep,该print的时候就print。右边的图是python执行的时候所占用的cpu的情况。
多线程
但是,我们是无法忍受一共打印10个数,每个数之间还要sleep这个事实的,所以又出现了多线程,当一个线程sleeping的时候,cpu就去执行其他线程的内容了。例如:
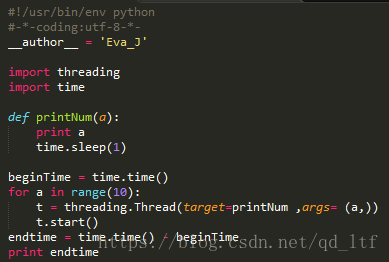

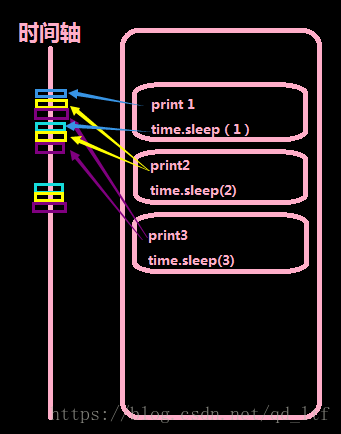
看上面的图,我们引入了threading模块,并使用Thread类实现了一个多线程的程序,这时,我们仅仅用了9毫秒的时间,就执行完了10个数字的打印。是因为我们将print这件事情,放到了多个线程中去执行,那么这几个线程就几乎同步去做事,表面上线程都在执行完打印之后进入了休眠状态,但是一个线程休息的间隙,cpu就可以去完成其他线程的任务了。看最右侧的时间图,我放大了时间轴,其实每一个颜色块就代表了他们在cpu中执行时占用的时间,它们之间的差别很小,大概是秒的-3次方这个数量级,足矣被我们忽略了,所以我们感觉他们是同时执行的,当线程执行sleep的时候,他们也几乎会同时开始计时,同时结束。我们看中间的结果图,打印的并不像上面单线程那么漂亮,这也是各个线程抢占输出资源的结果。于是我们知道了,多线程的执行几乎是同步的,并且共享内存,但是它会产生资源抢占的情况。
get一段多线程代码
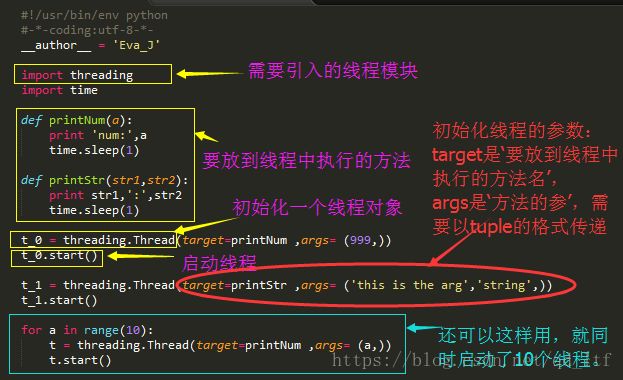
看上面的图,就是这样,其实开启一个线程非常简单,只需要引入一个threading包,然后初始化一个Thread的对象,将方法名和其参数作为Thread类初始化的参数传进去,再使用Thread的对象调用start方法,我们就启动了一个新的线程。我们可以在自己的程序中按照需求起一个或很多个线程。就像上面那样。
threading Code
python——线程与多线程进阶
之前我们已经学会如何在代码块中创建新的线程去执行我们要同步执行的多个任务,但是线程的世界远不止如此。接下来,我们要介绍的是整个threading模块。threading基于Java的线程模型设计。锁(Lock)和条件变量(Condition)在Java中是对象的基本行为(每一个对象都自带了锁和条件变量),而在Python中则是独立的对象,所以python的threading模块中还提供了Lock,Rlock,Condition,Event等常用类,它们在python中是独立于Tread模块的,但是却与线程紧密相关,不可分割。
需要注意的是:python的线程中没有优先级、线程组,也不能被停止、暂停、恢复、中断,线程只能随着线程中的代码执行完毕而被销毁。查了n多资料之后终于接受了以上事实,个人觉得这是python的一个坑,导致了我在实现线程池的时候无法停止已经注入了方法且执行超时的线程。
threading模块提供的类:
Thread, Lock, Rlock, Condition, [Bounded]Semaphore, Event, Timer, local.
threading 模块提供的常用方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
threading模块常用类详解
Thread类:我们使用Thread类来创建新的线程
start 线程准备就绪,等待CPU调度
setName 为线程设置名称
getName 获取线程名称
setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
join 逐个执行每个线程,执行完毕后继续往下执行,该方法是有高级用法的,代码在下面
run 线程被cpu调度后执行Thread类对象的run方法
join进阶用法
Lock类和Rlock类:由于线程之间随机调度:某线程可能在执行n条后,CPU接着执行其他线程。为了多个线程同时操作一个内存中的资源时不产生混乱,我们使用锁
acquire 给线程上锁
release 给线程解锁

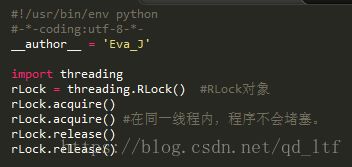
无论是lock还是rlock,提供的方法都非常简单,acquire和release。但是rlock和lock的区别是什么呢?RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。注意:如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的锁。
lock vs rlock Code
Condition类:条件变量对象能让一个线程停下来,等待其它线程满足了某个“条件”。如,状态的改变或值的改变。
- acquire 给线程上锁
- wait wait方法释放当前线程占用的锁,同时挂起线程,直至被唤醒或超时(需timeout参数)。当线程被唤醒并重新占有锁的时候,程序才会继续执行下去。
- notify 唤醒一个挂起的线程(如果存在挂起的线程)。注:notify()方法不会释放所占用的锁。
- notifyall 调用这个方法将通知等待池中所有线程,这些线程都将进入锁定池尝试获得锁定。此方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
比较经典的例子是下面这个生产者与消费者的例子,这个例子网上一搜到处都是,这里简单解释一下这段代码的意义,代码中写了两个类,Consumer和Producer,分别继承了Thread类,我们分别初始化这两个类获得了c和p对象,并启动这两个线程。则这两个线程去执行run方法(这里与Thread类内部的调度有关),定义了producer全局变量和condition对象为全局变量,当producer不大于1时,消费者线程被condition对象阻塞,不能继续消费(这里是不再递减),当producer不小于10时,生产者线程被condition对象阻塞,不再生产(这里是不再累加),代码在下面,拿去执行,断点一下就明白了。
condition Code
Event类:通用的条件变量。多个线程可以等待某个事件的发生,在事件发生后,所有的线程都会被激活。
event.wait(timeout) 当Flag为‘False’时,线程将被阻塞
clear 将“Flag”设置为False
set 将“Flag”设置为True
is_set 返回当前‘Flag’
这是一个比较关键的类,我在写线程池的时候看到python的threadpool模块也用到了。它的意义在于可以控制属于同一个线程类的多个实例化对象,让他们同时阻塞或者执行。配合队列来实现一个线程池非常好用。在接下里的博客中我们还要继续介绍。先放一个小例子在这里练练手,了解一下event的用法。
event Code
参考文献:
python多线程学习小结:http://www.myexception.cn/perl-python/1688021.html
python线程指南:http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
threading.RLock和threading.Lock:http://blog.sina.com.cn/s/blog_5dd2af0901012rad.html
python的进程、线程与协程:http://www.cnblogs.com/wupeiqi/articles/5040827.html
python——有一种线程池叫做自己写的线程池
python的线程一直被称为鸡肋,所以它也没有亲生的线程池,但是竟然被我发现了野生的线程池,简直不能更幸运。于是,我开始啃源码,实在是虐心,在啃源码的过程中,我简略的了解了python线程的相关知识,感觉还是很有趣的,于是写博客困难症患者一夜之间化身写作小能手,完成了一系列线程相关的博客,然后恍然发现,python的多线程是一个鸡肋哎。。。这里换来了同事们的白眼若干→_→。嘻嘻,但是鸡肋归鸡肋,看懂了一篇源码给我带来的收获和成就感还是不能小视,所以还是分享下。
别人的线程池
首先介绍别人写的线程池模块,野生threadpool,直接到pypi上去搜,或者pip安装,都可以get到。这里还是先贴上来:
threadpool Code

首先我们来看这个线程池的大致原理。在初始化中,它会根据我们的需求,启动相应数量的线程,这些线程是初始化好的,一直到程序结束,不会停止,它们从任务队列中获取任务,在没有任务的时候就阻塞,他们当我们有任务的时候,对任务进行初始化,放入任务队列,拿到任务的线程结束了自己的阻塞人生,欢欢喜喜的拿回去执行,并在执行完毕之后,将结果放入结果队列,继续到任务队列中取任务,如果没有任务就进入阻塞状态。看了一整天的源码竟让我三两句话解释清楚了,我到底是表达能力强还是理解能力差!!!我想静静~~~附上类图如下:
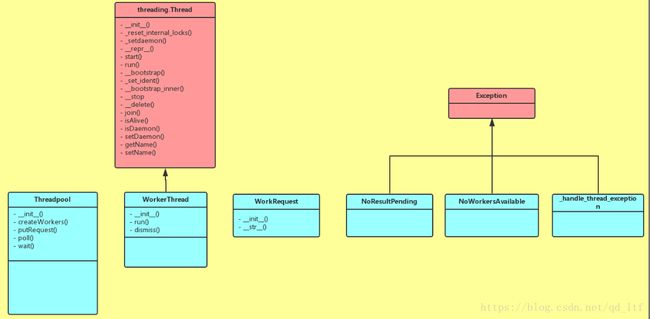
我的线程池
下面就来介绍我写的线程池了,上面的线程池有一个问题,那就是一开始创建了多少个线程,这些线程就一直存在内存中,即使没有工作,也不会销毁。于是我有了一个想法,就像其他语言中的线程池一样,写一个拥有最大线程数和最小线程数限制的线程池。

程序启动之初只将最小线程数的线程放在池中,并将线程设置为阻塞状态,用守护线程来查看任务队列,当任务队列中有任务时,则停止线程的阻塞状态,让它们到队列中去获取任务,执行,如果需要返回结果,则将结果返回结果队列。当任务很多,线程池中没有闲置的线程且当前线程数小于线程池最大线程数时,将创建新的线程(这里使用了yield)来接收新的任务,线程执行完毕后,则回到阻塞状态,长期闲置的线程会自动销毁,但池中线程永远不小于在最小线程数。当最小线程数和最大线程数相等的时候,内部就基本和野生线程相同啦
在参考了野生threadpool模块之后,我也学着继承原生的threading.Thread类,并重写了run方法,了解了给一个线程注入新方法的过程。并用到了Event方法和yield。如果不要返回值的话,我想效率还是很高的。尽管我在返回值方面还做了优化
银角大王的线程池:
threadpool Code
use example Code
这里安利下我男神,哈哈哈~武sir的方法和上面的例子中不同的是,自定义了线程的start方法,当启动线程的时候才初始化线程池,并根据线程池定义的数量和任务数量取min,而不是先开启定义的线程数等待命令,在一定程度上避免了空线程对内存的消耗。
with知识点
这里要介绍一个知识点。我们在做上下文管理的时候,用到过with。
我们如何自定义一个with方法呢?
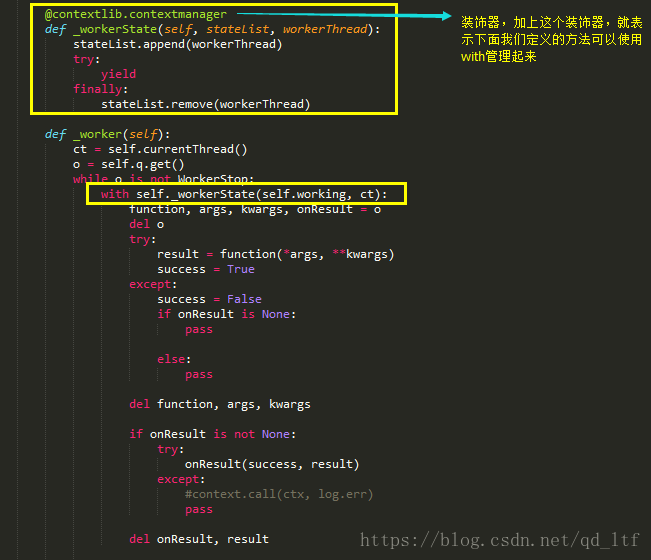
如此一来,我们便可以实现对线程状态的监控和管理了。将正在运行中的线程,加入到一个列表中,并使用yield返回,当线程执行完之后,再从这个列表中移除,就可以知道哪些线程是正在运行的啦。
python——协程
由于python中的多线程比较特殊,所以协程的概念就变得尤为珍贵了,对于cpu密集型的操作,使用协程的效率无疑要好过多线程很多。因为协程的创建及其间切换的时间成本要低于线程很多。也因为这一点,很多人说,协程才是python的未来,重要不重要!!!
python中提供协程的模块有两个,greenlet和gevent。greenlet和gevent最大的区别在于greenlet需要你自己来处理线程切换, 就是说,你需要自己指定现在执行哪个greenlet再执行哪个greenlet。ps:这两个包都不是python自带的,所以需要手动安装一下,pip就可以轻松搞定!
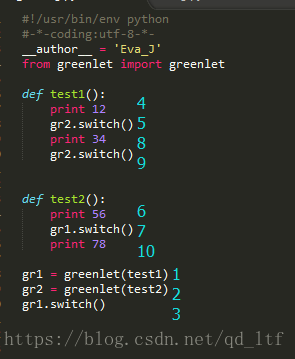

左侧图是greenlet的用法,我已经将执行顺序标注出来了,从图中我们不难看出greenlet的执行顺序是需要我们手动控制的,现在再看看右侧的图是gevent的用法,就智能多了,它不需要我们自己去支配,只要一个协程稍有空闲,gevent就帮你进行切换,已达到cpu的最大利用率。
greenlet Code
gevent example1 Code
这里再赠送一个gevent遇到IO操作自动切换的例子,这段代码一看就是一副高大上的样子,从老师那里偷来的,嘻:
gevent example2 Code
参考文献:
python的线程进程和协成:http://www.cnblogs.com/wupeiqi/articles/5040827.html
greenlet背景介绍与实现机制:http://blog.jobbole.com/77240/