CVPR2017 | G-RMI_Google大佬构建的姿态估计baseline
CVPR2017 Google | Towards accurate multi-person pose estimation in the wild
Official Code: pytorch
1.文章概述
正如文章中提到的in the wild,本文的目的是利用top-down类姿态估计算法,尝试解决现实生活中各种实际存在的复杂情况下的人体姿态估计问题。其中最常见的是在人与人彼此靠近时,人体目标框中存在多个人体肢体的场景。文章利用fastrcnn检测图片中可能容纳人体的目标框位置和大小,并估计每个框中可能包含的人体关键点。对于每种关键点类型,使用全卷积ResNet预测一个关键点热度图和两个关键点偏移量(X轴,Y轴)。为了结合这些输出,引入了一种新颖的热图-偏移聚合方法来获得精准的关键点预测。为了避免重复关键点的预测,通过直接基于OKS指标(OKS-NMS)的新型基于关键点的非最大抑制(NMS)机制,而不是较粗糙的基于boundingbox 的IOU NMS。作者还提出了一种新颖的基于关键点的置信度估计器,与使用Faster-RCNN检测框的得分进行结合得到最终姿态置信度,该方法能够对检测的AP有极大改善。本文提出的一种image_crop策略也被后续很多文章使用。
综上所述,本文提出了四种有效提升关键点预测精度的Trick:
1.多输出姿态估计网络
2.热图-偏移解码器
3.keypoint_rescore
4.keypoint_oks_nms
5.image_crop
2.多输出姿态估计网络
如下图所示,本文提出的人体姿态估计网络存在两个输出,其一与传统的网络类似:输出N个Heatmap。第二个输出为:2N个2D偏置向量图。N表示关键点类型个数。其中制作两者的标签时:Heatmap图中关键点坐标半径内的值为1,其余为0;2D偏置向量中离关键点坐标越近的向量模长越小。如下图所示展示了最终网络通过整合Heatmap和偏置向量图得到最终精确的人体关键点位置。网络的backbone为Resnet101。具体的整合方式在下述解码器部分讲解。需要注意的是下图只是一种概念上的说明,事实上2D偏置图是Heatmap图的两倍。(因为包含了x坐标和y坐标)

如下图的loss为多输出姿态估计网络的损失函数,从中可以看出结合了2D向量的值和Heatmap的置信度值。
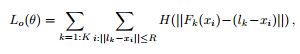
3.热图-偏移解码器
由于基于heatmap的方法,由于网络降采样的问题,最终的输出特征图和输入图之间存在分辨率的差别,在将关键点反算回去时存在固有的偏差。基于此,如下图所示,本文利用多输出姿态估计网络输出的2D偏移向量结合Heatmap得到更加精准的关键点。

得到Heatmap和偏移向量后,最终的解码过程如下代码所示:
imgs.shape[0]:表示minibatch数量
self.num_classes:表示关键点种类数
offsets_x_pred,offsets_y_pred:表示2D偏移向量的值
maps_pred:表示Heatmap上关键点置信度值
从下面的代码中可以看出,最终通过Heatmap上关键点的最高置信度位置,结合2D向量计算的距离得到一个新的score值,最终通过最大化该score值得到最后精确的关键点位置。
for i in range(imgs.shape[0]):
for k in range(self.num_classes):
offsets_x_ij = self.offset_x_ij + offsets_x_pred[i][k]
offsets_y_ij = self.offset_y_ij + offsets_y_pred[i][k]
distances_ij = torch.sqrt(offsets_x_ij * offsets_x_ij + offsets_y_ij * offsets_y_ij)
distances_ij[distances_ij > 1] = 1
distances_ij = 1 - distances_ij
score_ij = (distances_ij * maps_pred[i][k]).sum(3).sum(2)
v1,index_y = score_ij.max(0)
v2,index_x = v1.max(0)
keypoints[i][k][0] = index_y[index_x]
keypoints[i][k][1] = index_x
4.keypoint_rescore
我们对位置进行最大化处理,对关键点进行平均处理,从而得到最终的实例级别的姿态检测分数,具体实现代码如下所示:
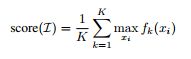
for img in kpts.keys():
img_kpts = kpts[img]
for n_p in img_kpts:
box_score = n_p['score']
kpt_score = 0
valid_num = 0
for n_jt in range(0, num_joints):
t_s = n_p['keypoints'][n_jt][2]
if t_s > in_vis_thre:
kpt_score = kpt_score + t_s
valid_num = valid_num + 1
if valid_num != 0:
kpt_score = kpt_score / valid_num
# rescoring
n_p['score'] = kpt_score * box_score
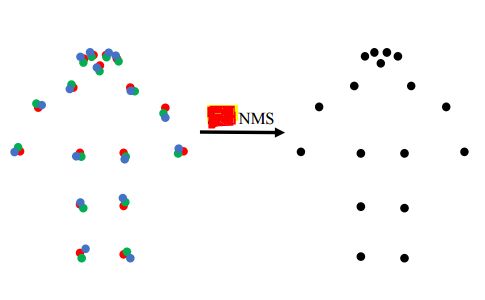
5.keypoint_oks_nms
标准NMS基于目标框的交叠比(IoU)来测量重叠率。本文提出了一种考虑关键点的更精确的变体。使用关键点相似度(OKS)来测量两个候选整体检测的重叠。通常,在人体目标检测器的输出处使用一个相对较高的iou 阈值来过滤高度重叠的框。姿态估计器输出的更合适的oks阈值,更适合于确定两个候选检测姿态之间的重叠。实现代码如下所示:
def oks_iou(g, d, a_g, a_d, sigmas=None, in_vis_thre=None):
if not isinstance(sigmas, np.ndarray):
sigmas = np.array([.26, .25, .25, .35, .35, .79, .79, .72, .72, .62, .62, 1.07, 1.07, .87, .87, .89, .89]) / 10.0
vars = (sigmas * 2) ** 2
xg = g[0::3]
yg = g[1::3]
vg = g[2::3]
ious = np.zeros((d.shape[0]))
for n_d in range(0, d.shape[0]):
xd = d[n_d, 0::3]
yd = d[n_d, 1::3]
vd = d[n_d, 2::3]
dx = xd - xg
dy = yd - yg
e = (dx ** 2 + dy ** 2) / vars / ((a_g + a_d[n_d]) / 2 + np.spacing(1)) / 2
if in_vis_thre is not None:
ind = list(vg > in_vis_thre) and list(vd > in_vis_thre)
e = e[ind]
ious[n_d] = np.sum(np.exp(-e)) / e.shape[0] if e.shape[0] != 0 else 0.0
return ious
def oks_nms(kpts_db, thresh, sigmas=None, in_vis_thre=None):
"""
greedily select boxes with high confidence and overlap with current maximum <= thresh
rule out overlap >= thresh, overlap = oks
:param kpts_db
:param thresh: retain overlap < thresh
:return: indexes to keep
"""
if len(kpts_db) == 0:
return []
scores = np.array([kpts_db[i]['score'] for i in range(len(kpts_db))])
kpts = np.array([kpts_db[i]['keypoints'].flatten() for i in range(len(kpts_db))])
areas = np.array([kpts_db[i]['area'] for i in range(len(kpts_db))])
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
oks_ovr = oks_iou(kpts[i], kpts[order[1:]], areas[i], areas[order[1:]], sigmas, in_vis_thre)
inds = np.where(oks_ovr <= thresh)[0]
order = order[inds + 1]
return keep
6.image_crop
作者首先通过目标框的高度和宽度,使所有的框具有相同的固定长宽比,而不扭曲图像的长宽比。在此之后,进一步放大了方框,以包含额外的图像上下文,该扩大比例在训练时随机为1–1.5,在测试时定义为1.25。最后将得到的crop框resize成网络的输入大小。实现代码如下所示:
def _xywh2cs(self, x, y, w, h):
center = np.zeros((2), dtype=np.float32)
center[0] = x + w * 0.5
center[1] = y + h * 0.5
if w > self.aspect_ratio * h:
h = w * 1.0 / self.aspect_ratio
elif w < self.aspect_ratio * h:
w = h * self.aspect_ratio
scale = np.array(
[w * 1.0 / self.pixel_std, h * 1.0 / self.pixel_std],
dtype=np.float32)
if center[0] != -1:
scale = scale * 1.25
return center, scale
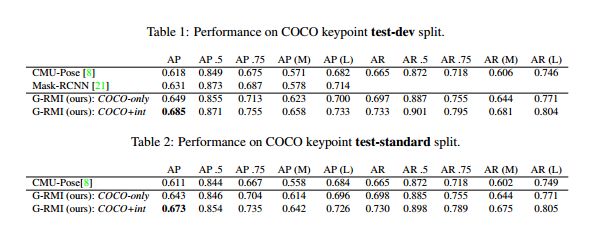
7.结果展示
如下图所示,本文提出的方法达到了当时的SOTA。需要注意的是本文提出的很多Trick你在现在的SOTA算法中都能看到被使用,包括keypoint_rescore,keypoint_oks_nms,image_crop,总之谷歌出品必属精品。