集成confluence6.7.1、jira7.8和crowd3.2.1 SSO登录 统一账户管理
摘要
端午节闲来无事,想起公司的jira confluence 还没集成单点登录(也是应领导的需求),所以就有了这篇文章,记录下过程,以备后查。
由于先前已经有了jira和confluence服务器,也已经使用了很长时间,上面的数据很多不适合重新做,所以就在已有jira、confluence的情况下集成SSO(crowd)。
如果小伙伴们需要部署新的jira和confluence网上有很多教程,在这里我就不赘述了,破解工具(confluence、crowd)已经放到百度云上 链接:https://pan.baidu.com/s/11kKunO6tsMpm-L6Y9KaZFg 密码:popp
服务器架构如下:
| 名称 | 服务器 |
|---|---|
| jira | http://172.16.165.174:8080 |
| confluence | http://192.168.6.107:8090/ |
| crowd | http://172.16.165.175:8095/ |
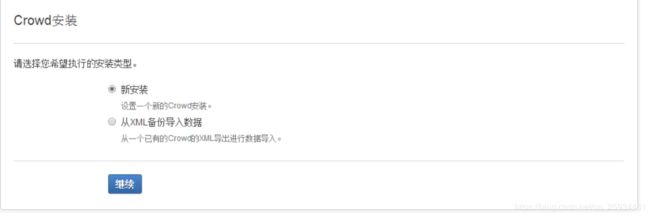
一、想要集成SSO单点登录,需要先安装crowd
用途:在安装了confluence,jira,fisheye后发现每次登录它们就得重新输入用户名密码,所以安装crowd, Atlassian单点登录的产品,可以用于集中用户、用户组管理,方便权限控制。
1.下载crowd
$ wget https://product-downloads.atlassian.com/software/crowd/downloads/atlassian-crowd-3.2.1.tar.gz
2.安装&破解&汉化
[crowd@crowd ~]$ tar xf atlassian-crowd-3.2.1.tar.gz -C /opt/
[crowd@crowd ~]$ vim /opt/atlassian-crowd-3.2.1/crowd-webapp/WEB-INF/classes/crowd-init.properties
.......
crowd.home=/var/crowd-home #最后一行crowd安装路径
[crowd@crowd ~]$ /opt/atlassian-crowd-3.2.1/start_crowd.sh ##启动
登陆8095端口查看,出现界面表示没有问题,点击set upcrowd

破解crowd:
[crowd@crowd ~]$ cp /opt/atlassian-crowd-3.2.1/crowd-webapp/WEB-INF/lib/atlassian-extras-3.2.jar /tmp/atlassian-extras-2.6.jar
把atlassian-extras-2.6.jar导出到windows 打开crowd_keygen.jar 链接:https://pan.baidu.com/s/11kKunO6tsMpm-L6Y9KaZFg 密码:popp



数据库初始化完成后(需要一段时间),继续默认下一步即可。
3.启动
启动:
/crowd/atlassian-crowd-3.3.4/start_crowd.sh
停止:
/crowd/atlassian-crowd-3.3.4/stop_crowd.sh
4.汉化
将汉化包crowd-language_zh_CN-2.7.0.jar放入/opt/atlassian-crowd-3.2.1/crowd-webapp/WEB-INF/lib

二、Crowd 与 JIRA、Confluence集成
1、配置crowd
新建目录,点击crowd的diectories(目录),点击add diectory,选择internal,点击next;
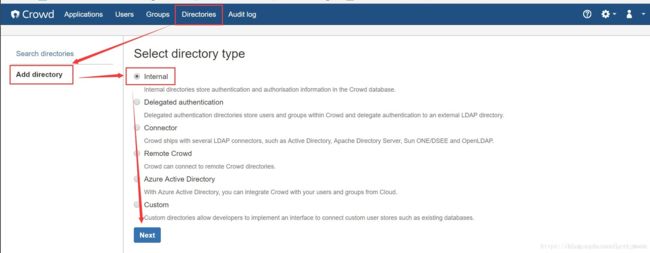
填写目录名称,点击continue;
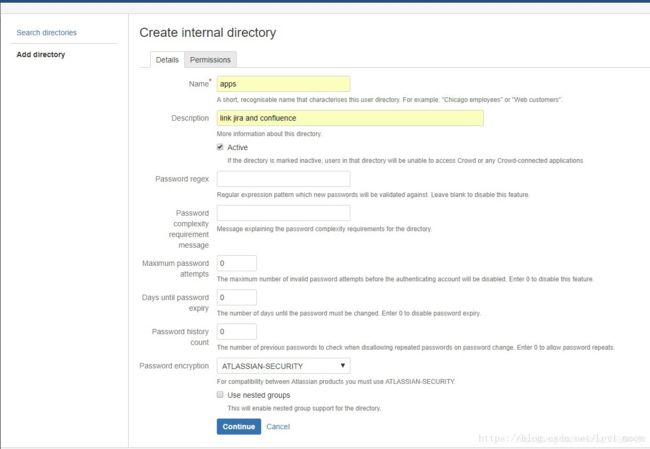
点击update,完成目录的添加

最终完成创建如下:
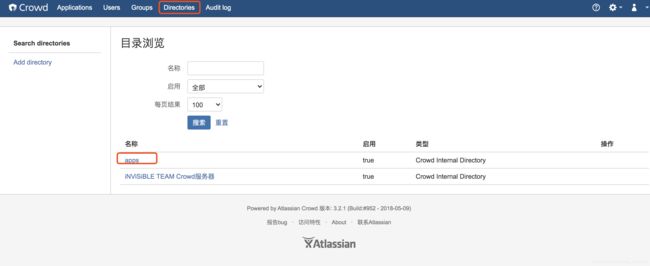
Crowd 与 JIRA 集成
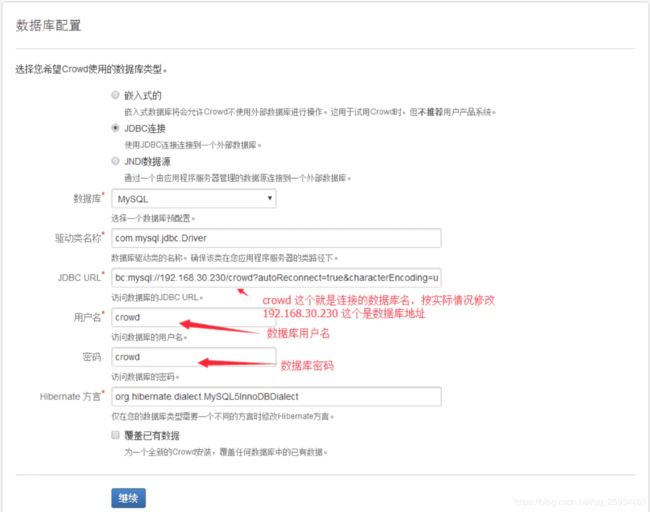
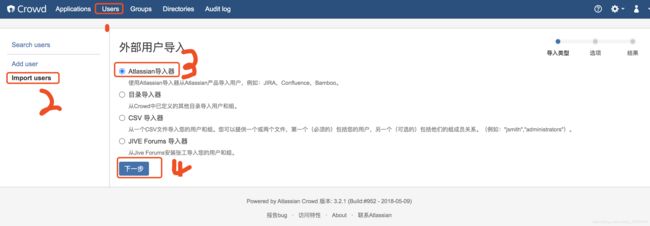
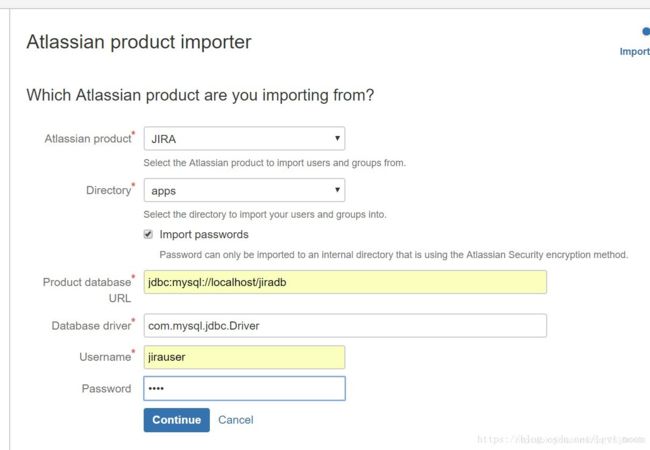
导入jira的用户,product选择jira,diectory选择apps,databases url填写jira数据库地址,点击continue
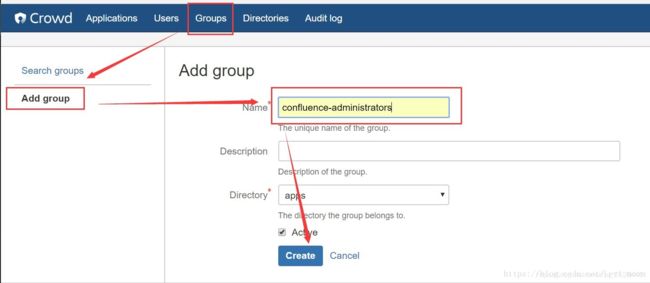
添加用户组,点击crowd的groups,选择add group,填写name(主要是填写confluence的用户组,jira的用户组在导入用户时,会自动创建),点击create
要保证有这些用户组;

添加应用,点击crowd的application,选择add application,填写相关信息,点击next;
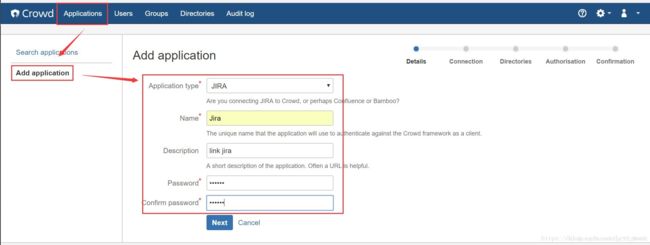
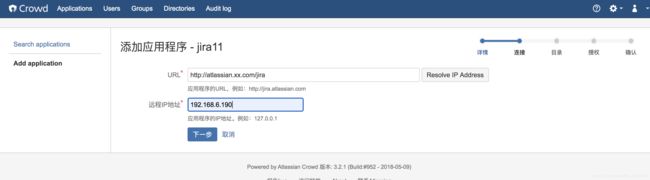
填写要添加应用的路径,,点击resolve IP address,自动解析ip地址,点击next
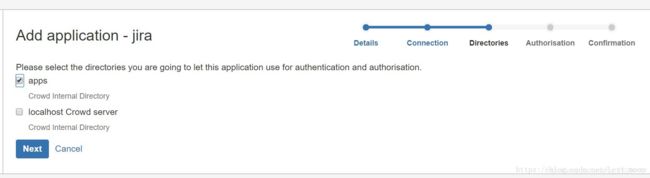
选择目录,选择创建的apps目录,点击next
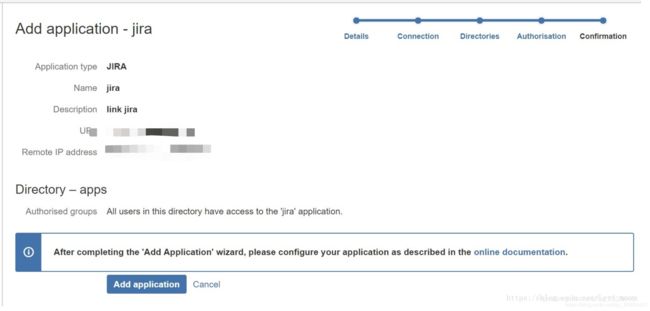
设置用户允许从指定目录访问新添加的应用程序,勾选allow all users to authenticate,点击next

点击add application,完成新应用的添加
使用 JIRA 管理员,登录 JIRA。点击用户管理 --> 用户目录 --> 添加目录,选择 “Atlassian 人群”,点击下一步
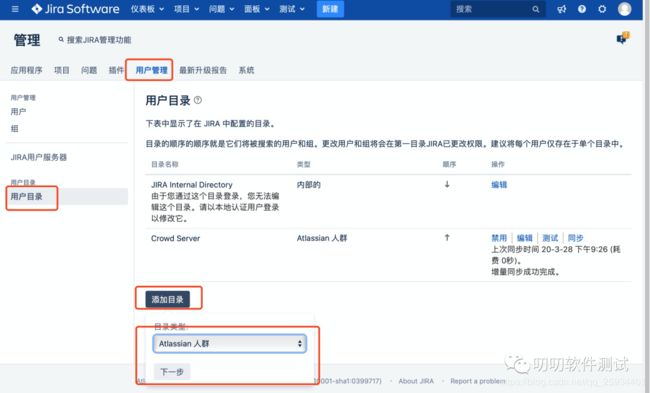
输入 Crowd 服务器的配置,点击测试,并保存。

名称:Crowd Server
服务器的URL:Crowd的URL地址,比如:http://www.example.com:8095/crowd/
应用程序名称:与在 Crowd 里配置的 Application 名称一致
应用程序密码:与在 Crowd 里配置的 Application 密码一致
系统默认每 1 小时从 Crowd 同步一次用户(系统管理员可修改),点击同步按钮也可手动同步。
注销管理员用户,使用 Crowd 里的用户尝试登陆 JIRA,发现能够登录进去了。
2、Crowd 与 Confluence集成
参考 Crowd 与 JIRA 集成。
jira、confluence、crowd 以上三台服务器添加hosts
编辑:/etc/hosts
192.168.6.190 atlassian.xx.com
最终

3、配置jira、confluence、crowd域名
需要注意的地方是想要实现SSO单点登录 必须使用域名访问。
一开始没使用域名,这个也是坑我花费了很长的时间。
首先给各个服务配置上域名,在这里我使用的是nginx,配置如下:
[crowd@crowd ~]$ more atlassian.conf
server {
listen 80;
server_name atlassian.xx.com;
client_max_body_size 500m;
proxy_connect_timeout 120;
proxy_send_timeout 600;
proxy_read_timeout 600;
charset UTF-8;
location ^~ /jira {
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
client_max_body_size 32m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 240;
proxy_read_timeout 240;
#设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffer_size 128k;
#proxy_buffers缓冲区,网页平均在32k以下的设置
proxy_buffers 32 32k;
#高负荷下缓冲大小(proxy_buffers*2)
proxy_busy_buffers_size 128k;
#设定缓存文件夹大小,大于这个值,将从upstream服务器传
proxy_temp_file_write_size 128k;
#limit_except PUT GET POST HEAD OPTIONS { deny all;}
add_header Cache-Control no-cache;
add_header Cache-Control no-store;
add_header pragma no-cache;
add_header Cache-Control must-revalidate;
add_header expires 0 ;
proxy_pass http://172.16.165.174:8080/jira;
}
location / {
try_files $uri @confluence;
}
location @confluence {
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
internal;
proxy_pass http://wiki;
}
location ^~ /crowd {
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
client_max_body_size 32m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 240;
proxy_read_timeout 240;
#设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffer_size 128k;
#proxy_buffers缓冲区,网页平均在32k以下的设置
proxy_buffers 32 32k;
#高负荷下缓冲大小(proxy_buffers*2)
proxy_busy_buffers_size 128k;
#设定缓存文件夹大小,大于这个值,将从upstream服务器传
proxy_temp_file_write_size 128k;
#limit_except PUT GET POST HEAD OPTIONS { deny all;}
add_header Cache-Control no-cache;
add_header Cache-Control no-store;
add_header pragma no-cache;
add_header Cache-Control must-revalidate;
add_header expires 0 ;
proxy_pass http://172.16.165.175:8095/crowd;
}
}
再修改jira、confluence服务的context-path配置
Crowd
默认支持,无需修改。
JIRA
# server.xml,在 Context 标签中添加 path="/jira"
$ vi /opt/jira/atlassian/jira/conf/server.xml
<Context path="/jira" docBase="${catalina.home}/atlassian-jira" reloadable="false" useHttpOnly="true">
# 重启生效
Confluence
# server.xml,在 Context 标签中添加 path="/confluence"
$ vi /opt/confluence/atlassian/confluence/conf/server.xml
<Context path="/confluence" docBase="../confluence" debug="0" reloadable="false" useHttpOnly="true">
# 重启生效
访问地址列表如下:
jira:
http://atlassian.xx.com/jira
wiki:
http://atlassian.xx.com/confluence
crowd:
http://atlassian.xx.com/crowd/
三、单点登录(SSO)配置
在配置sso之前,各应用系统已配置好相应的域名
再次声明需要配置域名!!!
1、Confluence 配置 SSO
# copy /opt/atlassian-crowd-3.2.1/client/crowd-integration-client-3.2.1.jar 到 jira服务的 /opt/atlassian/jira/atlassian-jira/WEB-INF/lib/
# 编辑 seraph-config.xml
$ vi /opt/confluence/atlassian/confluence/confluence/WEB-INF/classes/seraph-config.xml
# 注释掉
<!--<authenticator class="com.atlassian.confluence.user.ConfluenceGroupJoiningAuthenticator"/>-->
# 打开注释
<authenticator class="com.atlassian.confluence.user.ConfluenceCrowdSSOAuthenticator"/>
# 修改 crowd.properties
$ vi /opt/atlassian/confluence/confluence/WEB-INF/classes/crowd.properties
#application.name:配置 crowd 里该 Application 的名称
#application.password:配置 crowd 里该 Application 的密码
#application.login.url:配置 crowd 的地址
#crowd.server.url:配置 crowd 的 services 地址
#crowd.base.url:配置 crowd 的 baseurl 地址
#session.tokenkey:与 crowd 管理页面的SSO cookie name保持一致
application.name confluence
application.password xx
application.login.url http://atlassian.xx.com/crowd/
crowd.server.url http://atlassian.xx.com/crowd/services/
crowd.base.url http://atlassian.x.com/crowd/
session.isauthenticated session.isauthenticated
session.tokenkey crowd.token_key
session.validationinterval 2
session.lastvalidation session.lastvalidation
# 重启 Confluence 生效
验证:
先登录crowd,然后在打开一个页面,输入confluence地址,发现不需要在手动输入账户密码,直接就登进去了
注意:必须使用带域名的地址,登录的用户必须是同步过的用户。
2、JIRA 配置 SSO
拷贝 /opt/atlassian-crowd-3.2.1/client/crowd-integration-client-3.2.1.jar 到 jira服务的 /opt/atlassian/jira/atlassian-jira/WEB-INF/lib/
编辑 seraph-config.xml
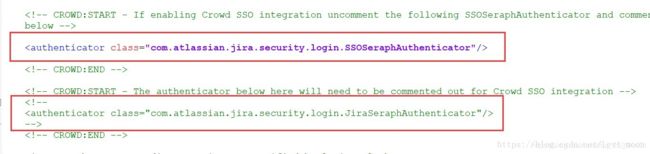
参考 Confluence 配置 sso,基本一样,只是 JIRA 的安装目录里没有 crowd.properties 文件,可以从 Confluence 或者 Crowd 拷贝一份,然后修改配置的内容即可。
$ cat /opt/atlassian/jira/atlassian-jira/WEB-INF/classes/crowd.properties
application.name jira
application.password confluence
application.login.url http://atlassian.xx.com/crowd/
crowd.server.url http://atlassian.x.com/crowd/services/
crowd.base.url http://atlassian.x.com/crowd/
session.isauthenticated session.isauthenticated
session.tokenkey crowd.token_key ##与crowd系统配置的token保持一致
session.validationinterval 2
session.lastvalidation session.lastvalidation
重启服务。
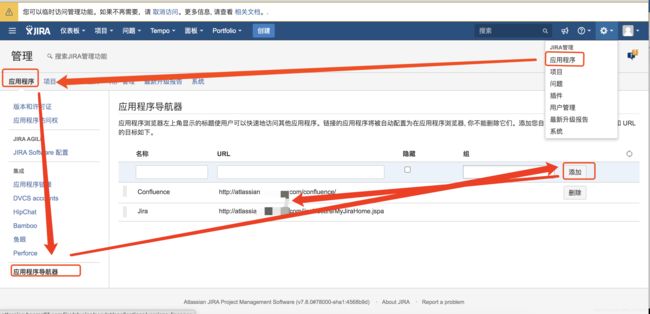
四、配置程序导航器
jira配置:

confluence配置:
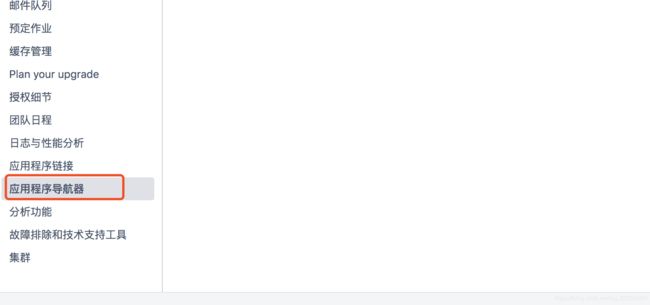


使用已有的账号登录jira或者confluence,点击导航器切换服务,看是否自动登录,是否需要再次登录,如果不需要说明sso单点登录配置成功。