【深度学习】 Attention机制的几种实现方法总结(基于Keras框架)
说明
在讲解了Dense+Attention以及LSTM+Attention时,还是使用了别人的代码,因此很多同学对一些地方仍有不够清晰的认识,在这里分享下自己的经验,并基于实践重新设计了实验。这是本人在Attention实践后的经验之谈,所讲不一定完全正确,欢迎讨论。
目录
- 说明
- 1 前情提要
- 1.1 参数设定
- 1.2 数据集生成
- 2 模型构建
- 2.1 总体构建
- 2.1.1 搭建模型
- 2.1.2 获取注意力
- 2.1.3 训练模型并可视化注意力
- 3 注意力机制实现
- 3.1 Baseline
- 3.2 第一种Attention机制:多层感知机得到权重
- 3.3 第二种Attention机制:提取特征嵌入向量的每一维得到注意力权重
- 3.4 第三种Attention机制:给每一维分配注意力权重,最后按特征进行聚合回来
- 4 实验结果
- 进阶!灵魂拷问
- 完整代码
1 前情提要
我们的实验思路还是借鉴于前两篇,随机生成数据,并指定某一个特征为标签。这样,我们就期望Attention机制能够很好地捕捉到这个特征,即给这个特征分配的权重较高。
为了方便理解,这一次我们的数据集最初都由int型表示,实际上,很多实际问题的特征都是以编号ID的形式出现,这样做符合实际。我们的数据集期望设计成如下形式,特征:[5,2,1,9,2],标签始终为第个3特征 [1];特征:[7,2,9,5,3],标签[9]…以此类推。
首先先看下整个实验所需要的一些参数,这里假设有12个特征,每个特征大小假设都在区间[0,999]内,通过Embedding进行嵌入进行后续的训练,嵌入维度为32。我们选定第3个特征为标签,期望Attention机制捕捉到。数据集大小设置为10000,即有10000个[特征,标签]数据,数据集太小了容易欠拟合或过拟合,太大了容易一下就学到,不方便比较。经测试10000这个值比较适中,因此就选择了它。将数据集8:2分为训练集和测试集,训练的轮数为10次。
注意,这里做了简化,在实际中,每个特征的最大值和最小值是大概率不相同的,比如年龄{0,1,…,100}和性别{0,1},因此,每种特征的嵌入维度也应不一致(范围大种类多的应嵌入维度更高,需要更多的隐层特征进行表示)。
1.1 参数设定
datasize = 10000 #数据规模
feature_cnt = 12 #特征数量
feature_key = 3 #人为设得的重要特征,期望注意力机制能正确捕捉到。feature_key<=feature_cnt
feature_range = 1000 #特征的值域
feature_min = 0 #特征最小值
feature_max = feature_range-1 #特征最大值
data_split = 0.8 #数据集划分比例
epochs = 10 #训练轮数
dim = 32 #嵌入维度
1.2 数据集生成
这里可以直接输出来看,为了方便调试,我们将随机种子固定,多次实验时随机结果相同,便于调试。同时,我们的问题视为多分类问题,因此将标签由ID的形式转化为one-hot形式。
def generate_data(datasize,feature_cnt,feature_key,feature_min,feature_max,data_split):
np.random.seed(1327) #有预见的随机,方便调试
data_split = int(datasize*data_split)
data = np.random.randint(low = feature_min,high = feature_max+1,size=(datasize,feature_cnt)) #值在[low,high)
#print(data)
label = data[:,feature_key-1].reshape(len(data),1) #让标签与数据的某一维特征相同。 feature_key<=feature_cnt
#print(label)
label = [to_categorical(lab[0],feature_max+1) for lab in label] #将标签由数值转化为one-hot形式,用于多分类
label = np.array(label)
#print(label)
train_x = data[:data_split]
train_y = label[:data_split]
test_x = data[data_split:]
test_y = label[data_split:]
'''
print('-------------train datasize:',len(train_x))
print('train_x:\n',train_x)
print('train_y:\n',train_y)
print()
print('-------------test datasize:',len(test_x))
print('test_x:\n',test_x)
print('test_y:\n',test_y)
'''
return train_x,train_y,test_x,test_y
2 模型构建
2.1 总体构建
总体的框架是一个多分类模型,本文一共实现了3种不同思路的Attention机制,每一类Attention最后的应用又可以按平均或拼接进行划分。因此,一共有6种不同的组合,再加上不用Attention进行的实验对比,总共7种。注意,在这里,实现注意力时,我们总是给每一个输入的特征分配一个注意力,总体框架的代码如下:
2.1.1 搭建模型
def build_model(feature_cnt,feature_max,model_type,merge_type,dim):
K.clear_session() #清除之前的模型,省得压满内存
inputs = Input(shape=(feature_cnt,), dtype='int32')
embd = Embedding(feature_max+1,dim)(inputs)
embd = BatchNormalization()(embd)
Dropout(0.25)
if model_type != 'basic':
if model_type == 'att1':
hidden = attention_block_1(embd,feature_cnt,dim)
elif model_type == 'att2':
hidden = attention_block_2(embd,feature_cnt,dim)
elif model_type == 'att3':
hidden = attention_block_3(embd,feature_cnt,dim)
if merge_type == 'avg':
#hidden = GlobalAveragePooling1D()(hidden)
hidden = Lambda(lambda x:K.mean(x,axis = 1))(hidden)
else:
hidden = Flatten()(hidden)
else:
hidden = Flatten()(embd)
outputs = Dense(feature_max+1,activation='softmax')(hidden)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
2.1.2 获取注意力
def get_layer_output(model,layer_name,inputs):
layer = Model(inputs=model.input,
outputs=model.get_layer(layer_name).output)
layer_out = layer.predict(inputs)
# print(layer_out[0])
return np.mean(layer_out,axis=0)
2.1.3 训练模型并可视化注意力
def train(train_x,train_y,test_x,test_y,feature_cnt,feature_max,model_type,epochs,merge_type,dim):
model = build_model(feature_cnt,feature_max,model_type,merge_type,dim)
model.fit(train_x,train_y
,batch_size=64
,epochs = epochs
,validation_data = (test_x,test_y)
#,validation_split=0.1
)
if model_type != 'basic':
att = get_layer_output(model,'attention',test_x)
print(att)
plt.bar(np.arange(feature_cnt),att)
print(np.sum(att))
3 注意力机制实现
3.1 Baseline
Baseline采用Embedding之后拼接,之后直接接Softmax完成多分类。可以看到,很明显过拟合了。

3.2 第一种Attention机制:多层感知机得到权重
注意,在这里及后文融合策略都以平均为例,拼接的结果直接在后文显示。
输入注意力模块的形状是 ( b a t c h s i z e , f e a t u r e _ c n t , d i m ) (batchsize,feature\_cnt,dim) (batchsize,feature_cnt,dim),由于我们共设置了12个特征,那么我们自然想得到12个注意力权重,此时可将输入进行展开,展开后再不断地与Dense层相连,Dense的单元数逐步降低,直至降至12。将最后一个Dense层的激活函数设置为softmax,即可得到注意力权重。
注意,得到注意力权重后,我们要乘以对应的输入,因为维度不一致,所以需要RepeatVector这个操作。即第一个特征的注意力权重假设为 α 1 \alpha_1 α1,则其每一维(此处共32维)都要乘以 α 1 \alpha_1 α1。后同。
def attention_block_1(inputs,feature_cnt,dim):
h_block = int(feature_cnt*dim/32/2)
hidden = Flatten()(inputs)
while(h_block >= 1):
h_dim = h_block * 32
hidden = Dense(h_dim,activation='selu',use_bias=True)(hidden)
h_block = int(h_block/2)
attention = Dense(feature_cnt,activation='softmax',name='attention')(hidden)
# attention = Lambda(lambda x:x*category)(attention)
attention = RepeatVector(dim)(attention)
attention = Permute((2, 1))(attention)
attention_out = Multiply()([attention,inputs])
return attention_out

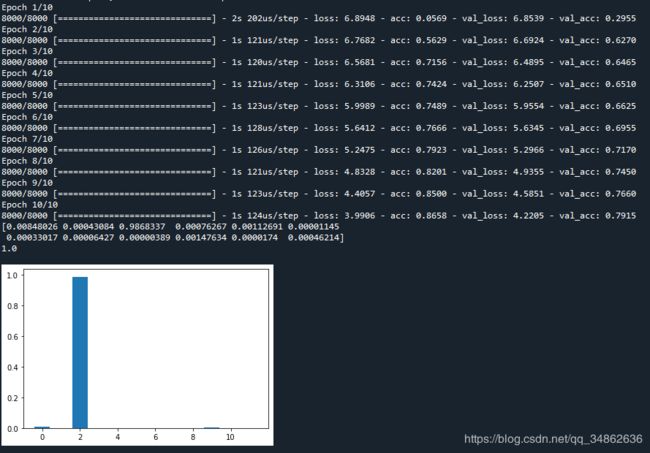
3.3 第二种Attention机制:提取特征嵌入向量的每一维得到注意力权重
题目的表述可能不准确,实际的实现方法就是前文提到的LSTM+Attention版本的代码,他将输入先进行一个转置,再对每一维进行softmax,得到每一维的注意力权重,最后合并成单独特征的注意力权重。
def attention_block_2(inputs,feature_cnt,dim):
a = Permute((2, 1))(inputs)
a = Reshape((dim, feature_cnt))(a) # this line is not useful. It's just to know which dimension is what.
a = Dense(feature_cnt, activation='softmax')(a)
a = Lambda(lambda x: K.mean(x, axis=1), name='attention')(a)
a = RepeatVector(dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
attention_out = Multiply()([inputs, a_probs])
return attention_out

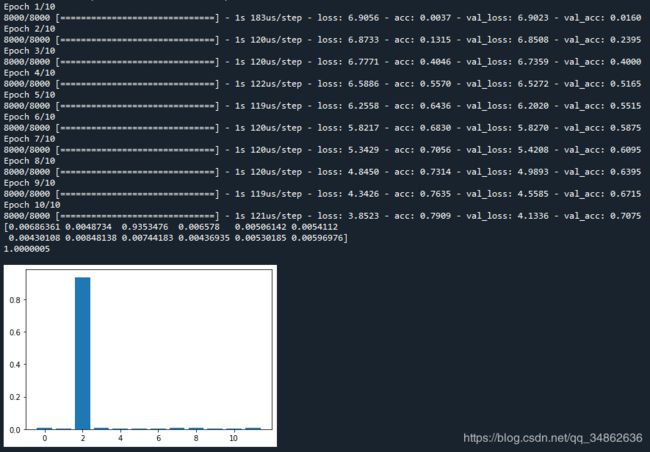
3.4 第三种Attention机制:给每一维分配注意力权重,最后按特征进行聚合回来
输入是(None,12,32)的,我们将其展开,可得到12*32=384维的张量。利用Dense+Attention那篇文章的思路,我们可以给384维的每一维先给个注意力权重,再按每一个特征32维进行聚合起来。即将32维的注意力权重累加,得到该特征对应的注意力权重。
def attention_block_3(inputs,feature_cnt,dim):
a = Flatten()(inputs)
a = Dense(feature_cnt*dim,activation='softmax')(a)
a = Reshape((feature_cnt,dim,))(a)
a = Lambda(lambda x: K.sum(x, axis=2), name='attention')(a)
a = RepeatVector(dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
attention_out = Multiply()([inputs, a_probs])
return attention_out

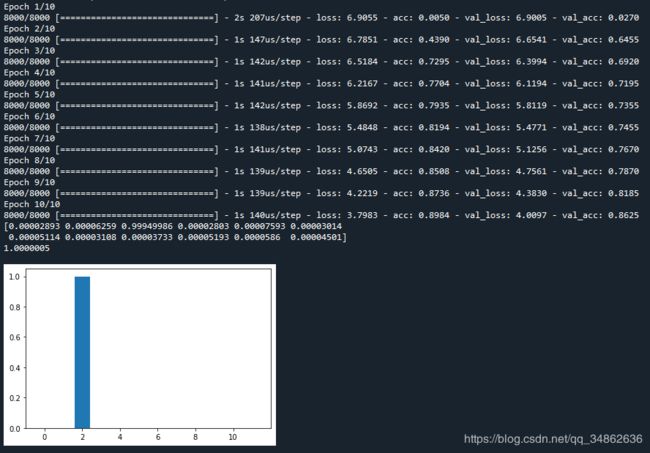
4 实验结果
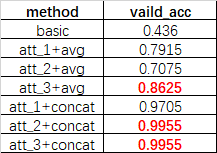
我们以验证集的正确率 valid_acc作为本实验最终的评价指标。共7个实验数据如下表所示。从实验结果上看,拼接的效果要好于平均,第三种Attention实现效果最好。
进阶!灵魂拷问
拷问1. 怎么看待这样的实验结果?
回答:从整个实验结果来看,三种注意力机制都能很好地捕捉重要的特征,但不同方法间仍有差距,第一种方法接近于增加层的思想,用全连接层的深度来增加注意力的准确性,第三种方法接近于增加单元数的思想,对每一个最小单元都进行注意力,增加准确性。而第二种方法则介于两者之间,但在平均时表现不佳。
拷问2. 拼接一定会强于平均吗?
回答:事实可能并非如此,一方面,目前大多数论文还是用平均来达到加权平均的目的,这种输入多个,输出单个的模式也有广泛的应用。(如self-attention),另一方面可能是由本文构建的数据集过于简单造成的,拼接会增加更多的计算量,同时实际中,重要的特征也往往不止一个。
此外,还要警惕拼接可能产生的梯度消失与梯度爆炸的隐患。我们拼接的是乘了注意力权重的输入,因此,实际上输入的大小被我们缩小了(乘了个小于1的数),当特征数足够多的情况下,即设 n n n个特征,输入平均乘了 1 n \frac 1 n n1, n n n趋近于无穷,那么乘完之后的特征就会无穷小,导致梯度更新不了。
拷问3. 如果每个特征嵌入维度不一致,还能否进行Attention?
回答:这个时候就体现出第三种方法的优越性,当维度不一致时,只有第三种方法能计算出注意力权重,此时,平均也会因维度不同而无法进行,只能选择拼接。即第三种方法+拼接可以进行维度不一致的Attention。
完整代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 4 10:10:17 2020
@author: YLC
"""
# In[*]
import os
import numpy as np
import pandas as pd
import time
import math
import tensorflow as tf
from keras import Model
from keras.models import Sequential
import keras.backend as K
from keras.layers import *
from keras.models import load_model
from keras.utils import plot_model,to_categorical
from keras import regularizers
from keras.constraints import non_neg
from keras.initializers import RandomUniform,RandomNormal
from matplotlib import pyplot as plt
# In[*]
def generate_data(datasize,feature_cnt,feature_key,feature_min,feature_max,data_split):
np.random.seed(1327) #有预见的随机,方便调试
data_split = int(datasize*data_split)
data = np.random.randint(low = feature_min,high = feature_max+1,size=(datasize,feature_cnt)) #值在[low,high)
#print(data)
label = data[:,feature_key-1].reshape(len(data),1) #让标签与数据的某一维特征相同。 feature_key<=feature_cnt
#print(label)
label = [to_categorical(lab[0],feature_max+1) for lab in label] #将标签由数值转化为one-hot形式,用于多分类
label = np.array(label)
#print(label)
train_x = data[:data_split]
train_y = label[:data_split]
test_x = data[data_split:]
test_y = label[data_split:]
'''
print('-------------train datasize:',len(train_x))
print('train_x:\n',train_x)
print('train_y:\n',train_y)
print()
print('-------------test datasize:',len(test_x))
print('test_x:\n',test_x)
print('test_y:\n',test_y)
'''
return train_x,train_y,test_x,test_y
# In[*]
def build_model(feature_cnt,feature_max,model_type,merge_type,dim):
K.clear_session() #清除之前的模型,省得压满内存
inputs = Input(shape=(feature_cnt,), dtype='int32')
embd = Embedding(feature_max+1,dim)(inputs)
embd = BatchNormalization()(embd)
Dropout(0.25)
if model_type != 'basic':
if model_type == 'att1':
hidden = attention_block_1(embd,feature_cnt,dim)
elif model_type == 'att2':
hidden = attention_block_2(embd,feature_cnt,dim)
elif model_type == 'att3':
hidden = attention_block_3(embd,feature_cnt,dim)
if merge_type == 'avg':
#hidden = GlobalAveragePooling1D()(hidden)
hidden = Lambda(lambda x:K.mean(x,axis = 1))(hidden)
else:
hidden = Flatten()(hidden)
else:
hidden = Flatten()(embd)
outputs = Dense(feature_max+1,activation='softmax')(hidden)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
# In[*]
def attention_block_1(inputs,feature_cnt,dim):
h_block = int(feature_cnt*dim/32/2)
hidden = Flatten()(inputs)
while(h_block >= 1):
h_dim = h_block * 32
hidden = Dense(h_dim,activation='selu',use_bias=True)(hidden)
h_block = int(h_block/2)
attention = Dense(feature_cnt,activation='softmax',name='attention')(hidden)
attention = RepeatVector(dim)(attention)
attention = Permute((2, 1))(attention)
attention_out = Multiply()([attention,inputs])
return attention_out
# In[*]
def attention_block_2(inputs,feature_cnt,dim):
a = Permute((2, 1))(inputs)
a = Reshape((dim, feature_cnt))(a) # this line is not useful. It's just to know which dimension is what.
a = Dense(feature_cnt, activation='softmax')(a)
a = Lambda(lambda x: K.mean(x, axis=1), name='attention')(a)
a = RepeatVector(dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
attention_out = Multiply()([inputs, a_probs])
return attention_out
# In[*]
def attention_block_3(inputs,feature_cnt,dim):
a = Flatten()(inputs)
a = Dense(feature_cnt*dim,activation='softmax')(a)
a = Reshape((feature_cnt,dim,))(a)
a = Lambda(lambda x: K.sum(x, axis=2), name='attention')(a)
a = RepeatVector(dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
attention_out = Multiply()([inputs, a_probs])
return attention_out
# In[*]
def train(train_x,train_y,test_x,test_y,feature_cnt,feature_max,model_type,epochs,merge_type,dim):
model = build_model(feature_cnt,feature_max,model_type,merge_type,dim)
model.fit(train_x,train_y
,batch_size=64
,epochs = epochs
,validation_data = (test_x,test_y)
#,validation_split=0.1
)
if model_type != 'basic':
att = get_layer_output(model,'attention',test_x)
print(att)
plt.bar(np.arange(feature_cnt),att)
print(np.sum(att))
# In[*]
def get_layer_output(model,layer_name,inputs):
layer = Model(inputs=model.input,
outputs=model.get_layer(layer_name).output)
layer_out = layer.predict(inputs)
# print(layer_out[0])
return np.mean(layer_out,axis=0)
# In[*]
datasize = 10000 #数据规模
feature_cnt = 12 #特征数量
feature_key = 3 #人为设得的重要特征,期望注意力机制能正确捕捉到。feature_key<=feature_cnt
feature_range = 1000 #特征的值域
feature_min = 0 #特征最小值
feature_max = feature_range-1 #特征最大值
data_split = 0.8 #数据集划分比例
epochs = 10 #训练轮数
dim = 32 #嵌入维度
train_x,train_y,test_x,test_y = generate_data(datasize,feature_cnt,feature_key,
feature_min,feature_max,data_split)
model_types = ['basic','att1','att2','att3']
model_type = model_types[1]
merge_types = ['avg','concat']
merge_type = merge_types[0]
train(train_x,train_y,test_x,test_y,feature_cnt,feature_max,model_type,epochs,merge_type,dim)