Python3实现某网站自动签到并且发短信到手机

本文原创作者: Lhaihai
原创投稿详情:重金悬赏 | 合天原创投稿等你来!
0x00 前言
这几天学了学python爬虫,就想用python实现一下自动签到领取积分,毕竟我比较懒,能不动手就让代码去做吧!
0x01 安装环境
python 需要用到的库
pipinstall selenium #模拟浏览器行为的库
pipinstall twilio #发送短信
安装ChromeDriver
ChromeDriver是Chrome浏览器的自动化测试工具
1、先查看Chrome浏览器的版本
点击 Chrome 的菜单,帮助->关于Chrome,即可查看 Chrome 的版本号

这里我的版本号是65.0
2、下载ChromeDriver
官方下载链接:
https://sites.google.com/a/chromium.org/chromedriver/downloads
这里我就下载 ChromeDriver 2.37

3、配置环境变量
Windows下,直接把ChromeDriver .exe放在Python的Scripts目录下

Linux和Mac也是一样把文件移动到属于环境变量的目录里或者将可执行文件配置到环境变量。
例如下面移动文件到/usr/bin 目录,首先进入其所在路径,然后将其移动到/usr/bin:
sudo mv chromedriver /usr/bin
4、测试一下哈
在命令行输入 chromedriver,如果有类似输出就说明chromedriver的环境变量配置好了

然后再写代码测试一下
fromselenium import webdriver
browser= webdriver.Chrome()
运行,会弹出Chrome浏览器,就可以开始写登录代码了。

0x02 登录
selenium是什么
官方的话:selenium一个Web应用程序测试的工具,而且Selenium测试直接运行在浏览器中,就像真正的用户在操作一样
简单的说,就是我们可以用selenium来控制浏览器然后完成一系列操作,比如打开某个网页,点击超链接、按钮,在文本框输入字符,获取网页的内容,模拟鼠标操作(右键,双击)
Selenium 支持非常多的浏览器,如Chrome、Firefox、Edge等,最新版本的Selenium已经不支持无界面浏览器PhantomJS,但是Chrome和Firefox已经支持无界面。
我们可以用下面的方式初始化一个浏览器对象
fromselenium importwebdriver
browser=webdriver.Chrome()
browser=webdriver.Firefox()
browser=webdriver.Edge()
browser=webdriver.PhantomJS()
browser=webdriver.Safari()
设置Chrome浏览器无界面:
fromselenium importwebdriver
fromselenium.webdriver.chrome.options importOptions #导入Options
chrome_options=Options()
chrome_options.add_argument('--headless') #无界面模式
chrome_options.add_argument('--disable-gpu') #Windows平台需要加上
browser=webdriver.Chrome(chrome_options=chrome_options) #把无界面设置导入
想要了解更多,可以查看官方文档:https://developers.google.cn/web/updates/2017/04/headless-chrome
打开一个网页
Selenium提供了get()方法来访问网页
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com') #打开百度
print(browser.page_source)
browser.close()
selenium怎么获取网页信息
获取节点
selenium获取节点(节点可以理解是网页的按钮,输入框等,学过HTML的同学知道其实它就是一个标签或者标签里面的内容、属性)的方法很多,下面是获取单个节点的方法,返回的是WebElement类型
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
想获取多个节点的话,就是element后面加上s例如:find_elements_by_id
查找多个节点函数返回的结果是一个列表,列表的每个节点是WebElement类型
节点交互
输入文字用send_keys() 方法,清空文字用clear() 方法,另外按钮点击用click() 方法。例如:
phonenumber=browser.find_element_by_id('userEmail') #通过id捕获到用户名输入框
phonenumber.send_keys(Username) #在用户名文本框输入用户名
获取节点信息
WebElement 类型有相关的方法和属性来直接提取节点信息,如属性、文本等等
input=browser.find_element_by_by_id('userEmail')
print(input.get_attribute('class') #获取class的名字
print(input.id) #获取id
print(input.location) #location可以获取该节点在页面中的相对位置
print(input.tag_name) #tag_name可以获取标签名称
print(input.size) #size可以获取节点的大小
知识点介绍好了,开始实战,打开合天的首页,F12->点一下左边的小箭头->再点输入手机的文本框->就会显示出文本框的信息来。查看发现它的id是userEmail,就可以通过id来获取这个节点。

密码框和登录按钮也是如此,类似操作拿到密码框的id是passwordIn,登录按钮的id是registButIn。
于是我们初步的代码已经出来了。
version 1.0
这是第一个版本,
from selenium import webdriver
import time
Username = 'xxxxxxxxx' #登录的手机号码
Password = 'xxxxxxxxxx' #密码
loginUrl = 'http://www.xxxxxx.com/loginLab.do' #xxxxxx登录网址
browser = webdriver.Chrome()
browser.maximize_window() #浏览器最大化
browser.get(loginUrl) #Chrome浏览器打开登录页面
phonenumber = browser.find_element_by_id('userEmail') #通过id捕获到用户名输入框
phonenumber.send_keys(Username) #在用户名文本框输入用户名
password = browser.find_element_by_id('passwordIn') #通过id捕获到密码输入框
password.send_keys(Password) #在密码框输入密码
siginbutton = browser.find_element_by_id('registButIn') #捕获到登录按钮
siginbutton.click() #点击登录按钮
time.sleep(3) #暂停3s
browser.close() #关闭浏览器
运行,试了几次竟然都成功登录了:-(
我之前测试的时候,老是没有登录成功,原因是登录按钮没有获取到,就算暂停了程序(time.sleep())等一等还是有这个问题。所以我就写了个函数来检查登录按钮是否获取成功
def isFindElement(element):
# print('check:')
# print(element)
if element: #如果捕获到元素,就返回true,否则返回false
return True
else:
return False
def SignIn()
#略略略
#-----
siginbutton = browser.find_element_by_id('registButIn')
while(not isFindElement(siginbutton)): #循环判断登录按钮是否获取成功,成功就退出
time.sleep(0.5)
print('signin-false')
siginbutton = browser.find_element_by_id('registButIn')
siginbutton.click()
之前测试的时候,check起码打印两次:-( ,
但是想到这个方法的估计也就像我一样是个不怎么了解selenium的新手
后来了解到selenium的等待,赶紧优化一下
version 2.0
介绍两个新概念
selenium 的隐性等待和显性等待
隐性等待
隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。
implicitly_wait(10) #等待10s
温馨提示:隐性等待在整个driver的周期都起作用,所以只要设置一次即可
显性等待
WebDriverWait,配合该类的until()和until_not()方法,就可以根据判断条件而进行灵活地等待了。
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
代码具体什么意思可以去看一下手册,这里我们只要会调用就好了。
fromselenium.webdriver.support.wait importWebDriverWait #导入了新的库
fromselenium.webdriver.support importexpected_conditions asEC #导入了新的库
fromselenium.webdriver.common.by importBy #导入了新的库
defhetianlab()
#省略十万行代码
locator =(By.ID, 'registButIn') #通过id发现的登录按钮
try:
#等待30s,默认0.5s检查一次是否捕获到登录按钮
WebDriverWait(browser,30).until(EC.presence_of_element_located(locator))
siginbutton =browser.find_element_by_id('registButIn')
siginbutton.click()
print('登录按钮点击成功')
except:
print("registButIncan't find")
温馨提示:最长等待时间取决于隐性等待和显性等待的最大值。上面例子为30s,如果隐性等待时间大于显性等待时间,那么最长等待时间就是隐性等待时间
顺便包装为函数方便调用,添加上获取积分的代码,前面为了方便测试就没有设置为无界面模式,现在可以设置为无界面模式了
version 2.0 代码
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2018/4/17 12:55
# @Author : Lhaihai
# @File :
# @Software: PyCharm
"""
Description : 自动登录,签到一下,并且拿到自己当前积分有多少,最后发送短信给手机
"""fromselenium importwebdriver
fromselenium.webdriver.chrome.options importOptions
fromselenium.webdriver.support.wait importWebDriverWait
fromselenium.webdriver.support importexpected_conditions asEC
fromselenium.webdriver.common.by importBy
importtime
chrome_options=Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')def SignIn(Username,Password):
loginUrl='http://www.xxxxxxx.com/loginLab.do'
browser = webdriver.Chrome(chrome_options=chrome_options) #设置为无界面模式
browser.maximize_window()
browser.implicitly_wait(10) #隐性等待10s
browser.get(loginUrl)
phonenumber = browser.find_element_by_id('userEmail')
phonenumber.send_keys(Username)
password = browser.find_element_by_id('passwordIn')
password.send_keys(Password)
locator = (By.ID, 'registButIn')
try:
WebDriverWait(browser,30).until(EC.presence_of_element_located(locator)) #显性等待30s
siginbutton = browser.find_element_by_id('registButIn')
siginbutton.click()
print('登录按钮点击成功')
except:
print("registButIn can't find")
time.sleep(3)
#signImg捕获用户头像,没错就是头像,其实把鼠标放到头像上就会显示我的主页,selenium也有模拟鼠标操作的,那就是ActionChains,这里简单起见就直接使用.click()了
signImg = browser.find_element_by_class_name('siLg-img')
signImg.click() #点击
myindex = browser.find_element_by_link_text('我的主页')
myindex.click() #点击我的主页
heshibi = browser.find_elements_by_class_name('allNum') #获得登录次数和积分数量
Msg = '签到成功\n登录次数:' + heshibi[0].text + ',积分:' + heshibi[1].text
print(Msg)
browser.close()
if __name__ == '__main__':
SignIn('username','password') #填写你的用户名和密码
0x03 发送短信
这时候我们已经可以成功登录hetianlab并且拿到自己账号合氏币的数量。接下来我们进行最后一步,发送短信到自己手机上。
1、注册Twilio账号
访问http://twilio.com/(需要自备梯子)填写注册表单。注册了新账户后,你需要验证一个手机号码,短信将发给该号码(这项验证是必要的,防止有人利用该服务向任意的手机号码发送垃圾短信)。 收到验证号码短信后,在Twilio网站上输入它,证明你拥有要验证的手机。
现在,就可以用twilio模块向这个电话号码发送短信了。
2、获取一个Twilio电话号码:
我在Dashboard找了好久没发现Phone的选项,后来翻了翻官方教程https://support.twilio.com/hc/en-us/articles/223136107-How-does-Twilio-s-Free-Trial-work-/,然后点里面的链接打开 :-( 。
其实你可以用右上角的UPGRADE搜索框搜索,或者直接打开这个网址 https://www.twilio.com/console/phone-numbers/getting-started
挑一个地区和号码,确定。恭喜你,获得一个免费的电话号码了。
3、要验证接收短信的手机号码,要不然就会出现下面的报错
twilio.base.exceptions.TwilioRestException: HTTP 400 error: Unable to create record: The number +8613xxxxxx30 is unverified. Trial accounts cannot send messages to unverified numbers; verify +8613xxxxxx30 at twilio.com/user/account/phone-numbers/verified, or purchase a Twilio number to send messages to unverified numbers.
在Verified验证手机号码

可以发送短信验证码或者接受电话获得验证码
4、正式发送短信
从官方文档https://www.twilio.com/docs/libraries/python拿到下面代码
from twilio.rest import Client
# Your Account SID from twilio.com/console
account_sid = "AC9810ae2342f0014cd05e338bce9be8cb"
# Your Auth Token from twilio.com/console
auth_token = "your_auth_token"
client = Client(account_sid, auth_token)
message = client.messages.create(
to="+15558675309", #接收短信的手机
from_="+15017250604", #自己twilio的号码
body="Hello from Python!") #短信的内容
print(message.sid)
只需要把auth_tocken和from_换成自己的,再修改一下to和body
auth_tocken: 打开Dashboard,加密的就是你的auth_tocken

message 的from_ 填上你的twilio手机号码,虽然你选择号码的时候看起来是这样子:+1(855) 912-6770
(这个号码是我重新去twilio买电话号码那随机拿的一个,并不是我的:) )但是最后你会获得一个号码:类似+15017250604 ,
运行一下,就可以收到短信了,短信的号码是会换了,玩多了你就发现自己手机一大片都是twilio的短信

最后封装一下函数,类似下方,
from twilio.rest import Client
def sendMessage(toPhoneNumber,Msg):
# Your Account SID from twilio.com/console
account_sid = "AC9810ae2342f0014cd05e338bce9be8cb"
# Your Auth Token from twilio.com/console
auth_token = "your_auth_token"
client = Client(account_sid, auth_token)
message = client.messages.create(
to='+86'+toPhoneNumber, #接收短信的手机
from_="+15017250604", #自己twilio的号码
body=Msg) #短信的内容
print(message.sid)
我保存为twilioToMyPhone.py,放到python.exe当前目录下

以后想发送短信就直接调用:
importtwilioToMyPhone
twilioToMyPhone.sendMessage('phonenumber',Msg)
5、在version2.0 加上发送短信的代码
在开头导入库
importtwilioToMyPhone
在browser.close()之前,Msg= ''签到成功......'之后加上发送短信的一句代码
Msg = '签到成功\n登录次数:' + heshibi[0].text + ',积分:' + heshibi[1].text
twilioToMyPhone.sendMessage('phonenumber',Msg)
browser.close()
差不多大功告成了,就算可以一键登录,不用手动打开浏览器,我还是想跟懒一点:)
最后一步,设置每天自动启动py
tip1:
to="+15558675309"
to的值是接收短信的手机号码,注意的是,中国大陆的电话号码要在前面加上+86
tip2:
python文件的命名不能是twilio.py
如果你像我一样给它这样命名,在importtwilio库的时候会失败,
哈哈,宛如一个智障(自我嘲讽一波)
找找stackoverflow.com发现下面这个:

https://stackoverflow.com/questions/41013556/importerror-cannot-import-name-twiliorestclient
tip3:
github项目
https://github.com/twilio/twilio-python/
0x04 设置每天自动启动python
.bat 运行python
问题来了,想要运行python代码,总不能启动pycharm然后点击运行吧,所以使用DOS命令来运行python代码
而.bat 是windows的批处理文件,可以双击.bat文件来运行我们的python代码
具体什么意思么,.py文件不能像exe一样双击运行,但是.bat文件可以,这是为了方便我们下一步的任务启动器
类似下图,

这里有个坑,当你原原本本按照上图打好了每一个字符,双击.bat,却发现没有成功运行(收到短信)
然后复制python F:\CodeDevelopment\PythonDevelopment\xxxxxxSignin.py 到DOS,发现有个方框在 F:\前面,去掉方框,再从DOS复制这条代码到.bat文件,就可以运行了。或者直接先在DOS敲好这句代码,然后复制到.bat。
![]()
当然,顺便运行看看能不能正常启动,类似下图就是成功了,但DOS会跳出一些INFO,目前还不知道为什么

![]()
任务计划程序
当当当,最最后一步,设置自动启动
不同操作系统都有自己的任务计划程序
Windows :任务计划程序,
Linux: Cron
Mac : Launchd
以Windows 10 为例子:
1、打开任务计划程序,直接搜索就好了,win+s弹出搜索框(开着小娜的话电脑CPU利用率一直挺高,关了就好很多了),然后输入任务计划程序

2、点击右边的创建任务

3、名字自己随便取吧,触发器->新建->设置每天某个时候启动,

但是如果我那个时候电脑没有开启呢?可以在设置勾上‘如果过了计划开始时间,立即启动任务’

4、最重要的操作来了,新建操作->浏览选上测试好的bat

5、乖巧等待它自动运行

0x05 后记
或许有大佬想问了,为啥不用request,而这么麻烦的用selenium。
我是学习了selenium后,想要练练手,仅此而用。
简单尝试了下request
importrequests
datas={
'username':'xxxxxxxxxxx',
'password':'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
}
r=requests.get('http://www.xxxxx.com/loginLab.do',data=datas)
print(r.text)
直接在登录页面post没成功,抓包发现
先是Post一个去/getRsaOfKey.action

返回一些字符串

接着 才是真的 POST /Login.action
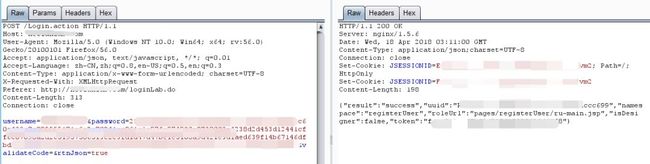
发现它post过去的密码是经过加密了的,而且还POST了两个认证参数
&validateCode=&rtnJson=true
所以我们构造POST的data为
datas={
'username':'xxxxxxxxxxxx',
'password':'xxxxxxxxxxxxxxxxxxxxxxxxx',
'validateCode':'true',
'rtnJson':'true',
}
因为是先POST去/getRsaOfKey.action拿到加密后的password,然后POST/Login.action
所以我直接request请求/Login.action
然后再request一下自己的主页看看登录次数
检查一下当前的登录次数:264

运行代码:

再运行一次:

登录成功了,以后登录就只需要运行下面短短20行左右代码,感谢合天小姐姐提醒我填了这个坑
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2018/4/24 13:02
# @Author : Lhaihai
# @File : Request模拟登陆xxxx.py
# @Software: PyCharm
"""
Description : 使用request来登陆
"""
import requests
from bs4 import BeautifulSoup
datas={
'username':'xxxxxxxxxxxxx',
'password':'xxxxxxxxxxxxxxxxxxxxxxxxx',
'validateCode':'true',
'rtnJson':'true',
}
url = 'http://www.xxxxxxx.com/Login.action'
myindexUrl = 'http://www.xxxxxxxx.com/profile.do?u=xxxxxxxxxxxx' #我的主页url
session = requests.session()
#模拟登陆
r = session.post(url,data=datas)
#输出响应报文状态码
print(r.status_code)
#请求访问主页
r2 = session.get(myindexUrl)
bs = BeautifulSoup(r2.text,'lxml')
for Msg in bs.find_all(class_='logoRight'):
for ms in Msg.find_all(name='p'):
print(ms.string)
写得挺长的,或许有些错误。虚心请教各位大表哥,如果发现错误,请指点一下小弟。
(完)
![]()
看不过瘾?合天2017年度干货精华请点击《【精华】2017年度合天网安干货集锦》
![]()

需要学习Python编程的,可以在合天学习以下实验
Python编程指南

点击文末阅读原文,可直接学习!
