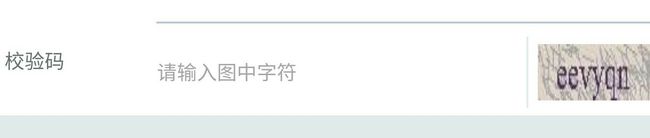
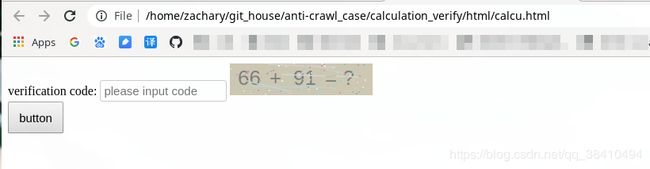
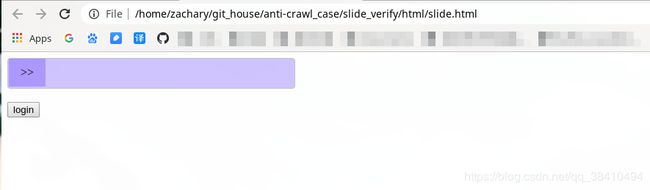
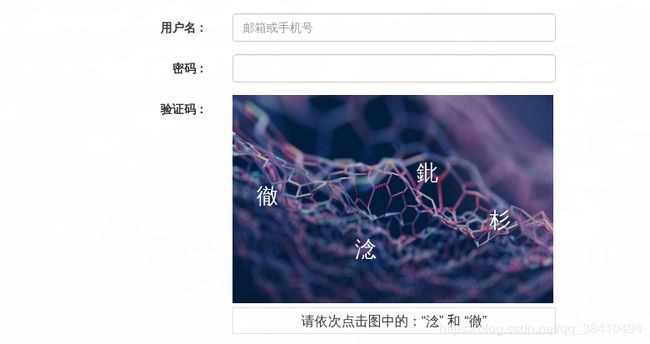
- pandas介绍
June �
可视化python数据分析大数据机器学习
本文的主要内容是基于中国大学mooc(慕课)中的“Python数据分析与可视化”课程进行整理和总结。pandas是python第三方库,是基于Numpy的一种工具,经常与numpy与matplotlib一起使用,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是
- 2024年最新办公室文员必备python神器,将PDF文件表格转换成excel表格!
2401_84691713
程序员pythonpdfexcel
初始化DataFrame数据对象、用于DataFrame数据保存data_frame=pd.DataFrame()读取PDF表格pdf文件路径pdf_file=‘/usr/load/data.pdf’读取pdf数据pdf_data=pdfplumber.open(pdf_file)遍历PDF数据forpageinpdf_data.pages:每一页的Tbale表格数据table=page.extr
- Python中time模块用法示例详解
阿鈞ajunwiwx
谜之操作python人工智能机器学习目标检测opencv
前言仅供个人学习用,如果对各位朋友有参考价值,给个赞或者收藏吧^_^一、time模块介绍time模块是Python中处理时间相关操作的核心工具,提供了时间获取、格式化、转换、延迟以及计时等多种功能。总的来说time模块中时间可以有3种格式:时间戳,时间元组和时间字符串,其中时间字符串可以自行定制格式。time模块的方法大部分是针对这几种时间格式进行输出,处理和转化。时间戳:是指格林威治时间1970
- Python酷库之旅-第三方库Pandas(018)
神奇夜光杯
pythonpandas开发语言标准库及第三方库基础知识学习与成长
目录一、用法精讲44、pandas.crosstab函数44-1、语法44-2、参数44-3、功能44-4、返回值44-5、说明44-6、用法44-6-1、数据准备44-6-2、代码示例44-6-3、结果输出45、pandas.cut函数45-1、语法45-2、参数45-3、功能45-4、返回值45-5、说明45-6、用法45-6-1、数据准备45-6-2、代码示例45-6-3、结果输出46、pa
- Python酷库之旅-第三方库Pandas(062)
神奇夜光杯
pythonpandas开发语言人工智能excel第三方库学习与成长
目录一、用法精讲241、pandas.Series.view方法241-1、语法241-2、参数241-3、功能241-4、返回值241-5、说明241-6、用法241-6-1、数据准备241-6-2、代码示例241-6-3、结果输出242、pandas.Series.compare方法242-1、语法242-2、参数242-3、功能242-4、返回值242-5、说明242-6、用法242-6-1
- 【分布式日志篇】从工具选型到实战部署:全面解析日志采集与管理路径
网罗开发
人工智能实战java集springboot人工智能分布式
网罗开发(小红书、快手、视频号同名) 大家好,我是展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、HarmonyOS、Java、Python等方向。在移动端开发、鸿蒙开发、物联网、嵌入式、云原生、开源等领域有深厚造诣。图书作者:《ESP32-C3物联网工程开发实战》图书作者:《SwiftUI入门,进阶与实战》超级个体:CO
- MySQL Connector/Python 接口 (一)
weixin_33750452
python数据结构与算法数据库
这里仅介绍MySQL官方开发的Python接口,参见这里:https://dev.mysql.com/doc/connector-python/en/Chapter1IntroductiontoMySQLConnector/Python这个接口是用纯Python写成的,仅依赖PythonStandardLibrary。MySQLConnector/Python支持以下几点:1、MySQLServe
- 华为OD机试D卷 --最大社交距离--24年OD统一考试(Java & JS & Python & C & C++)
飞码创造者
最新华为OD机试题库2024华为odjavajavascriptpythonc语言
文章目录题目描述输入描述输出描述用例1题目解析java源码js源码python源码c源码c++源码题目描述疫情期间需要大家保证一定的社交距离,公司组织开交流会议。座位一排共N个座位,编号分别为[0,N-1]。要求员工一个接着一个进入会议室,并且可以在任何时候离开会议室。满足:每当一个员工进入时,需要坐到最大社交距离(最大化自己和其他人的距离的座位);如果有多个这样的座位,则坐到索引最小的那个座位。
- 个人程序化交易软件有哪些?各自的优缺点及适用人群是什么?
财云量化
python炒股自动化量化交易程序化交易个人程序化交易软件优缺点适用人群股票量化接口股票API接口
炒股自动化:申请官方API接口,散户也可以python炒股自动化(0),申请券商API接口python炒股自动化(1),量化交易接口区别Python炒股自动化(2):获取股票实时数据和历史数据Python炒股自动化(3):分析取回的实时数据和历史数据Python炒股自动化(4):通过接口向交易所发送订单Python炒股自动化(5):通过接口查询订单,查询账户资产股票量化,Python炒股,CSDN
- 数字水印算法分类以及区别(含有变换域python代码链接)
Nefelibat
数字水印数字水印变换域
目录看代码前需要知道的理论知识使用场景分类水印算法运行名词解释历史信息的两个丢失其他抗打印水印数字水印技术变换域算法。去github上下载了一个用python写的源码:https://codeload.github.com/Messi-Q/python-watermark/zip/master然后自己跑了一下,该代码包括两个部分。一个是图像数字水印代码实现,一个是PDF数字水印代码实现。看代码前需
- 日志收集平台day01:项目设计
intqao
日志收集平台项目linuxkafkazookeepernginxpython
一、项目需求本项目的目的是模拟生产环境下对web服务器产生的日志进行收集并存入数据库,最终以web应用方式展示日志数据。二、技术选型环境:CentOs7web服务器:nginx/1.20.1(仅测试使用)消息队列:kafka2.12分布式应用程序协调服务软件:zookeeper3.6.3生产者:filebeat-7.17.5-1.x86_64消费者:使用python中的模块pykafka实现消费者
- 解释 Python 中的装饰器及其作用?
程序员黄同学
PythonPython面试题python前端开发语言
一、装饰器的基本概念装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。这个新的函数通常会在原函数的基础上添加一些额外的功能,比如日志记录、权限验证、性能统计等。装饰器的语法糖形式为@decorator_name,可以放在函数定义的上方。二、装饰器的作用代码复用:通过装饰器,我们可以将一些通用的功能抽象出来,避免在每个函数中重复编写相同的代码。增强可读性:装饰器可以将与业务逻辑无关
- 【成人版python基础入门】第一章 开篇——与 Python 的浪漫相遇
精通代码大仙
pythonpython开发语言
开篇——与Python的浪漫相遇在这个数字化日益menjadi成主流的时代,掌握一门编程语言似乎已经成为了每个人不可推卸的责任。如果你正在寻找一种既强大又易学的语言,那么Python就是你心中的“白月光”。这不仅仅是因为它简洁明了的语法,良好的社区支持,更因为它那无可比拟的跨平台性——无论你的电脑是Windows、MacOS还是Linux,Python都将无差别地陪伴在你身边。现在,让我们一起进入
- 【成人版python基础入门】第一章 循环与条件判断——让程序“活”起来
精通代码大仙
pythonpython服务器
循环与条件判断——让程序“活”起来在与Python的第一次浪漫相遇之后,我们已经学会了如何使用变量、数据类型、输入输出和基本运算符。现在,是时候让我们的程序“活”起来,让它能够像人一样思考和做出决策。这一篇教程将带你深入学习Python的循环和条件判断,这些基本概念是编写复杂程序的基石。通过风趣的例子和实际代码示例,我们将一起探索Python的逻辑世界。条件判断:if、elif、else语句条件判
- 探秘Python字节码:解读pycdc的强大反编译实力
晏肠冲Jessie
探秘Python字节码:解读pycdc的强大反编译实力Pycdc.7z项目地址:https://gitcode.com/open-source-toolkit/a35f1在这个数字时代,深入了解代码的本质成为了众多开发者追求的目标。针对Python编程语言,一款名为pycdc的工具以其独特魅力,正逐渐成为探索字节码奥秘的首选武器。本文旨在全面剖析pycdc,引导您发现它如何助力技术探索,教育学习,
- 探秘Python世界:高效反编译工具pycdc与pycdas详解
曹勇宁
探秘Python世界:高效反编译工具pycdc与pycdas详解项目地址:https://gitcode.com/open-source-toolkit/faa06在当今快速发展的编程领域,Python作为一种强大而灵活的编程语言,其源代码的加密与解密成为了开发者关注的焦点。针对Python3.9及以上版本的.pyc文件反编译挑战,一款名为pycdc及其辅助工具pycdas的开源项目应运而生,它填
- 《CPython Internals》阅读笔记:p336-p352
codists
读书笔记python
《CPythonInternals》学习第17天,p336-p352总结,总计17页。一、技术总结1.GDBGDB是GNUDbugger的缩写。(1)安装sudoaptinstallgdb(2)创建.gdbinit文件touch~/.gdbinitvim~/.gdbinit(3)配置.gdbinit文件add-auto-load-safe-path/project/cpython注:1./proj
- 如何使用Langchain加载Blackboard文档
PPIG564
langchain前端python
在当今数字化和网络化的学习环境中,Blackboard已成为许多教育机构的关键工具。为了有效地集成和利用Blackboard中的数据,开发人员可以使用特定的工具来加载和处理这些数据。Langchain是一个强大的Python库,能够帮助我们轻松地处理Blackboard中的文档数据。在本文中,我们将深入了解如何使用Langchain来加载Blackboard文档。技术背景介绍BlackboardL
- 华为OD机试E卷 --最大社交距离--24年OD统一考试(Java & JS & Python & C & C++)
飞码创造者
最新华为OD机试题库2024华为odjavajavascriptc语言python
文章目录题目描述输入描述输出描述用例题目解析JS算法源码Java算法源码python算法源码c算法源码c++算法源码题目描述疫情期间需要大家保证一定的社交距离,公司组织开交流会议。座位一排共N个座位,编号分别为[0,N-1]。要求员工一个接着一个进入会议室,并且可以在任何时候离开会议室。满足:•每当一个员工进入时,需要坐到最大社交距离(最大化自己和其他人的距离的座位);•如果有多个这样的座位,则坐
- 如何使用 Python 连接 MySQL 数据库?
程序员黄同学
Python面试题Python数据库数据库pythonmysql
在Python开发中,连接MySQL数据库是一个常见的需求。我们可以使用多种库来实现这一功能,其中最常用的是mysql-connector-python和PyMySQL。下面我将详细介绍如何使用这两个库来连接MySQL数据库,并提供一些实际开发中的建议和注意事项。1.使用mysql-connector-python连接MySQL数据库mysql-connector-python是MySQL官方提供
- 基于数据可视化+SpringBoot+Vue的医院综合管理平台设计和实现(源码+论文+部署讲解等)
java李杨勇
Java精品毕设实战案例Java毕业设计实战案例信息可视化springbootvue.js医院综合管理平台Java毕业设计
博主介绍:✌全网粉丝50W+,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等
- SessionNotCreatedException:消息:无法创建新服务:通过 Python 使用 ChromeDriver 和 SeleniumGrid 的 ChromeDriverService
潮易
python开发语言
SessionNotCreatedException:消息:无法创建新服务:通过Python使用ChromeDriver和SeleniumGrid的ChromeDriverService首先,你需要确保你的系统中已经安装了Chrome浏览器以及对应的ChromeDriver版本。然后,你需要在你的项目中安装Selenium库,可以通过pipinstallselenium命令进行安装。接下来,你需要
- 使用 Nocalhost 开发 Rainbond 上的微服务应用
u012804784
android微服务microservices架构计算机
优质资源分享学习路线指引(点击解锁)知识定位人群定位Python实战微信订餐小程序进阶级本课程是pythonflask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。Python量化交易实战入门级手把手带你打造一个易扩展、更安全、效率更高的量化交易系统本文将介绍如何使用Nocalhost快速开发Rainbond上的微服务应用的开发流程以及实践操作步骤。Nocalhost可
- Dapr 远程调试之 Nocalhost
虚幻私塾
python计算机
优质资源分享学习路线指引(点击解锁)知识定位人群定位Python实战微信订餐小程序进阶级本课程是pythonflask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。Python量化交易实战入门级手把手带你打造一个易扩展、更安全、效率更高的量化交易系统虽然Visualstudio、Visualstudiocode都支持debug甚至远程debug,Dapr搭配Bridge
- 【数据治理】数据治理框架概述
野老杂谈
数据治理数据治理框架DAMA-DMBOKCOBIT企业数据治理数据管理
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏:⭐️全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.⭐️AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。⭐️大数据平台建设指南:全面讲解从数据采集到数据可视化的整个过程,掌握构建现代化数据平台的核心技术和方法。⭐️《遇见Python:初识、了解与热恋》:涵盖了Pytho
- 如何使用 Python 进行文件读写操作?
大G哥
python前端linux数据库开发语言
大家好,我是V哥。今天的内容来介绍Python中进行文件读写操作的方法,这在学习Python时是必不可少的技术点,希望可以帮助到正在学习python的小伙伴。以下是Python中进行文件读写操作的基本方法:一、文件读取:#打开文件withopen('example.txt','r')asfile:#读取文件的全部内容content=file.read()print(content)#将文件指针重置
- python数据处理的全流程
若木胡
toolspython开发语言
Python数据处理全流程一、数据收集(一)从文件中读取数据读取文本文件CSV文件(逗号分隔值)CSV文件是一种常见的简单数据存储格式,使用逗号来分隔数据值。Python中的csv模块可以方便地读取和写入CSV文件。例如,读取一个简单的CSV文件,其中包含姓名和年龄两列数据:importcsvdata=[]withopen('example.csv','r')asfile:reader=csv.r
- Python的输入函数input()
蜗牛_Chenpangzi
Python学习笔记总集python字符串编程语言
前言此篇文章是我在B站学习时所做的笔记,部分为亲自动手演示过的,方便复习用。此篇文章仅供学习参考。提示:以下是本篇文章正文内容,下面案例可供参考input函数input函数的基本使用#输入函数inputpresent=input('大圣想要什么礼物呢?')print(present,
- python multiprocessing模块_Python multiprocessing模块
weixin_39646084
python
一、简介python多线程有个讨厌的限制,全局解释器锁(globalinterpreterlock),这个锁的意思是任一时间只能有一个线程使用解释器,跟单cpu跑多个程序一个意思,大家都是轮着用的,这叫“并发”,不是“并行”。手册上的解释是为了保证对象模型的正确性!这个锁造成的困扰是如果有一个计算密集型的线程占着cpu,其他的线程都得等着....,试想你的多个线程中有这么一个线程,得多悲剧,多线程
- python自动化扫描,多线程枚举获取wifi信息,让你走在任何一个地方都能上网
代码讲故事
深耕技术之源python自动化扫描无线网络网络连接
python自动化扫描,多线程枚举获取wifi信息,让你走在任何一个地方都能上网。无线网络在无线局域网的范畴是指“无线相容性认证”,实质上是一种商业认证,同时也是一种无线联网技术,以前通过网线连接电脑,而Wi-Fi则是通过无线电波来连网;常见的就是一个无线路由器,那么在这个无线路由器的电波覆盖的有效范围都可以采用Wi-Fi连接方式进行联网,如果无线路由器连接了一条ADSL线路或者别的上网线路,则又
- HQL之投影查询
归来朝歌
HQLHibernate查询语句投影查询
在HQL查询中,常常面临这样一个场景,对于多表查询,是要将一个表的对象查出来还是要只需要每个表中的几个字段,最后放在一起显示?
针对上面的场景,如果需要将一个对象查出来:
HQL语句写“from 对象”即可
Session session = HibernateUtil.openSession();
- Spring整合redis
bylijinnan
redis
pom.xml
<dependencies>
<!-- Spring Data - Redis Library -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redi
- org.hibernate.NonUniqueResultException: query did not return a unique result: 2
0624chenhong
Hibernate
参考:http://blog.csdn.net/qingfeilee/article/details/7052736
org.hibernate.NonUniqueResultException: query did not return a unique result: 2
在项目中出现了org.hiber
- android动画效果
不懂事的小屁孩
android动画
前几天弄alertdialog和popupwindow的时候,用到了android的动画效果,今天专门研究了一下关于android的动画效果,列出来,方便以后使用。
Android 平台提供了两类动画。 一类是Tween动画,就是对场景里的对象不断的进行图像变化来产生动画效果(旋转、平移、放缩和渐变)。
第二类就是 Frame动画,即顺序的播放事先做好的图像,与gif图片原理类似。
- js delete 删除机理以及它的内存泄露问题的解决方案
换个号韩国红果果
JavaScript
delete删除属性时只是解除了属性与对象的绑定,故当属性值为一个对象时,删除时会造成内存泄露 (其实还未删除)
举例:
var person={name:{firstname:'bob'}}
var p=person.name
delete person.name
p.firstname -->'bob'
// 依然可以访问p.firstname,存在内存泄露
- Oracle将零干预分析加入网络即服务计划
蓝儿唯美
oracle
由Oracle通信技术部门主导的演示项目并没有在本月较早前法国南斯举行的行业集团TM论坛大会中获得嘉奖。但是,Oracle通信官员解雇致力于打造一个支持零干预分配和编制功能的网络即服务(NaaS)平台,帮助企业以更灵活和更适合云的方式实现通信服务提供商(CSP)的连接产品。这个Oracle主导的项目属于TM Forum Live!活动上展示的Catalyst计划的19个项目之一。Catalyst计
- spring学习——springmvc(二)
a-john
springMVC
Spring MVC提供了非常方便的文件上传功能。
1,配置Spring支持文件上传:
DispatcherServlet本身并不知道如何处理multipart的表单数据,需要一个multipart解析器把POST请求的multipart数据中抽取出来,这样DispatcherServlet就能将其传递给我们的控制器了。为了在Spring中注册multipart解析器,需要声明一个实现了Mul
- POJ-2828-Buy Tickets
aijuans
ACM_POJ
POJ-2828-Buy Tickets
http://poj.org/problem?id=2828
线段树,逆序插入
#include<iostream>#include<cstdio>#include<cstring>#include<cstdlib>using namespace std;#define N 200010struct
- Java Ant build.xml详解
asia007
build.xml
1,什么是antant是构建工具2,什么是构建概念到处可查到,形象来说,你要把代码从某个地方拿来,编译,再拷贝到某个地方去等等操作,当然不仅与此,但是主要用来干这个3,ant的好处跨平台 --因为ant是使用java实现的,所以它跨平台使用简单--与ant的兄弟make比起来语法清晰--同样是和make相比功能强大--ant能做的事情很多,可能你用了很久,你仍然不知道它能有
- android按钮监听器的四种技术
百合不是茶
androidxml配置监听器实现接口
android开发中经常会用到各种各样的监听器,android监听器的写法与java又有不同的地方;
1,activity中使用内部类实现接口 ,创建内部类实例 使用add方法 与java类似
创建监听器的实例
myLis lis = new myLis();
使用add方法给按钮添加监听器
- 软件架构师不等同于资深程序员
bijian1013
程序员架构师架构设计
本文的作者Armel Nene是ETAPIX Global公司的首席架构师,他居住在伦敦,他参与过的开源项目包括 Apache Lucene,,Apache Nutch, Liferay 和 Pentaho等。
如今很多的公司
- TeamForge Wiki Syntax & CollabNet User Information Center
sunjing
TeamForgeHow doAttachementAnchorWiki Syntax
the CollabNet user information center http://help.collab.net/
How do I create a new Wiki page?
A CollabNet TeamForge project can have any number of Wiki pages. All Wiki pages are linked, and
- 【Redis四】Redis数据类型
bit1129
redis
概述
Redis是一个高性能的数据结构服务器,称之为数据结构服务器的原因是,它提供了丰富的数据类型以满足不同的应用场景,本文对Redis的数据类型以及对这些类型可能的操作进行总结。
Redis常用的数据类型包括string、set、list、hash以及sorted set.Redis本身是K/V系统,这里的数据类型指的是value的类型,而不是key的类型,key的类型只有一种即string
- SSH2整合-附源码
白糖_
eclipsespringtomcatHibernateGoogle
今天用eclipse终于整合出了struts2+hibernate+spring框架。
我创建的是tomcat项目,需要有tomcat插件。导入项目以后,鼠标右键选择属性,然后再找到“tomcat”项,勾选一下“Is a tomcat project”即可。具体方法见源码里的jsp图片,sql也在源码里。
补充1:项目中部分jar包不是最新版的,可能导
- [转]开源项目代码的学习方法
braveCS
学习方法
转自:
http://blog.sina.com.cn/s/blog_693458530100lk5m.html
http://www.cnblogs.com/west-link/archive/2011/06/07/2074466.html
1)阅读features。以此来搞清楚该项目有哪些特性2)思考。想想如果自己来做有这些features的项目该如何构架3)下载并安装d
- 编程之美-子数组的最大和(二维)
bylijinnan
编程之美
package beautyOfCoding;
import java.util.Arrays;
import java.util.Random;
public class MaxSubArraySum2 {
/**
* 编程之美 子数组之和的最大值(二维)
*/
private static final int ROW = 5;
private stat
- 读书笔记-3
chengxuyuancsdn
jquery笔记resultMap配置ibatis一对多配置
1、resultMap配置
2、ibatis一对多配置
3、jquery笔记
1、resultMap配置
当<select resultMap="topic_data">
<resultMap id="topic_data">必须一一对应。
(1)<resultMap class="tblTopic&q
- [物理与天文]物理学新进展
comsci
如果我们必须获得某种地球上没有的矿石,才能够进行某些能量输出装置的设计和建造,而要获得这种矿石,又必须首先进行深空探测,而要进行深空探测,又必须获得这种能量输出装置,这个矛盾的循环,会导致地球联盟在与宇宙文明建立关系的时候,陷入困境
怎么办呢?
- Oracle 11g新特性:Automatic Diagnostic Repository
daizj
oracleADR
Oracle Database 11g的FDI(Fault Diagnosability Infrastructure)是自动化诊断方面的又一增强。
FDI的一个关键组件是自动诊断库(Automatic Diagnostic Repository-ADR)。
在oracle 11g中,alert文件的信息是以xml的文件格式存在的,另外提供了普通文本格式的alert文件。
这两份log文
- 简单排序:选择排序
dieslrae
选择排序
public void selectSort(int[] array){
int select;
for(int i=0;i<array.length;i++){
select = i;
for(int k=i+1;k<array.leng
- C语言学习六指针的经典程序,互换两个数字
dcj3sjt126com
c
示例程序,swap_1和swap_2都是错误的,推理从1开始推到2,2没完成,推到3就完成了
# include <stdio.h>
void swap_1(int, int);
void swap_2(int *, int *);
void swap_3(int *, int *);
int main(void)
{
int a = 3;
int b =
- php 5.4中php-fpm 的重启、终止操作命令
dcj3sjt126com
PHP
php 5.4中php-fpm 的重启、终止操作命令:
查看php运行目录命令:which php/usr/bin/php
查看php-fpm进程数:ps aux | grep -c php-fpm
查看运行内存/usr/bin/php -i|grep mem
重启php-fpm/etc/init.d/php-fpm restart
在phpinfo()输出内容可以看到php
- 线程同步工具类
shuizhaosi888
同步工具类
同步工具类包括信号量(Semaphore)、栅栏(barrier)、闭锁(CountDownLatch)
闭锁(CountDownLatch)
public class RunMain {
public long timeTasks(int nThreads, final Runnable task) throws InterruptedException {
fin
- bleeding edge是什么意思
haojinghua
DI
不止一次,看到很多讲技术的文章里面出现过这个词语。今天终于弄懂了——通过朋友给的浏览软件,上了wiki。
我再一次感到,没有辞典能像WiKi一样,给出这样体贴人心、一清二楚的解释了。为了表达我对WiKi的喜爱,只好在此一一中英对照,给大家上次课。
In computer science, bleeding edge is a term that
- c中实现utf8和gbk的互转
jimmee
ciconvutf8&gbk编码
#include <iconv.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/stat.h>
int code_c
- 大型分布式网站架构设计与实践
lilin530
应用服务器搜索引擎
1.大型网站软件系统的特点?
a.高并发,大流量。
b.高可用。
c.海量数据。
d.用户分布广泛,网络情况复杂。
e.安全环境恶劣。
f.需求快速变更,发布频繁。
g.渐进式发展。
2.大型网站架构演化发展历程?
a.初始阶段的网站架构。
应用程序,数据库,文件等所有的资源都在一台服务器上。
b.应用服务器和数据服务器分离。
c.使用缓存改善网站性能。
d.使用应用
- 在代码中获取Android theme中的attr属性值
OliveExcel
androidtheme
Android的Theme是由各种attr组合而成, 每个attr对应了这个属性的一个引用, 这个引用又可以是各种东西.
在某些情况下, 我们需要获取非自定义的主题下某个属性的内容 (比如拿到系统默认的配色colorAccent), 操作方式举例一则:
int defaultColor = 0xFF000000;
int[] attrsArray = { andorid.r.
- 基于Zookeeper的分布式共享锁
roadrunners
zookeeper分布式共享锁
首先,说说我们的场景,订单服务是做成集群的,当两个以上结点同时收到一个相同订单的创建指令,这时并发就产生了,系统就会重复创建订单。等等......场景。这时,分布式共享锁就闪亮登场了。
共享锁在同一个进程中是很容易实现的,但在跨进程或者在不同Server之间就不好实现了。Zookeeper就很容易实现。具体的实现原理官网和其它网站也有翻译,这里就不在赘述了。
官
- 两个容易被忽略的MySQL知识
tomcat_oracle
mysql
1、varchar(5)可以存储多少个汉字,多少个字母数字? 相信有好多人应该跟我一样,对这个已经很熟悉了,根据经验我们能很快的做出决定,比如说用varchar(200)去存储url等等,但是,即使你用了很多次也很熟悉了,也有可能对上面的问题做出错误的回答。 这个问题我查了好多资料,有的人说是可以存储5个字符,2.5个汉字(每个汉字占用两个字节的话),有的人说这个要区分版本,5.0
- zoj 3827 Information Entropy(水题)
阿尔萨斯
format
题目链接:zoj 3827 Information Entropy
题目大意:三种底,计算和。
解题思路:调用库函数就可以直接算了,不过要注意Pi = 0的时候,不过它题目里居然也讲了。。。limp→0+plogb(p)=0,因为p是logp的高阶。
#include <cstdio>
#include <cstring>
#include <cmath&