像Excel一样使用Python(二)

像excel一样使用python,上一期介绍了生成、查看、替换等功能,这一期介绍数据预处理,包括数据表合并、排序、分组等。
1.合并
Excel里智能复制粘贴来合并表格,或者通过VLOOKUP函数分步实现。python中,可以直接使用merge函数来合并两个表,可选参数较多,这里只介绍最常用的几个参数:
df1.merge(df2,how='inner',on=None,left_on=None,right_on=None)
或:pandas.merge(df1,df2,how='inner'…)
将df1与df2合并,how为合并方式,有“inner、outer、left、right”4种选择,分别为“求交集、并集、固定左边、固定右边”。On代表用于连接的键名,如果两表合并对象的列名不同,使用left_on=None, right_on=None来分别指定。在默认情况下,merge会自动以重叠的列名按inner的方式合并。
importpandasaspd
frompandasimportDataFrame,Series
df1=DataFrame({'gene':['arx1','arx2','arx3','arx4'],
'size':[411,530,289,450]})
df2=DataFrame([['arx2','kana-A'],['arx3','kana-B'],
['arx4','pdm-V'],['arx5','pdm-V1']],
columns=['gene','homo'])
df_inner=pd.merge(df1,df2,how='inner',on='gene')
printdf_inner
输出:
gene size homo
0 arx2 530 kana-A
1 arx3 289 kana-B
2 arx4 450 pdm-V
2.排序
在excel中,使用数据-排序可以对数据表直接进行排序。

在python中,可以使用sort_values和sort_index函数进行排序。
printdf1.sort_values(by=['size'])
输出:
gene size
2 arx3 289
0 arx1 411
3 arx4 450
1 arx2 530
而sort_index可以按索引进行排序。
df_inner.set_index('size')
#将size列作为索引df_inner.sort_index()
# 使用索引进行排序
3.分组
在excel中,使用“公式-插入函数-LOOKUP-选择分组列与分组条件”进行分组。
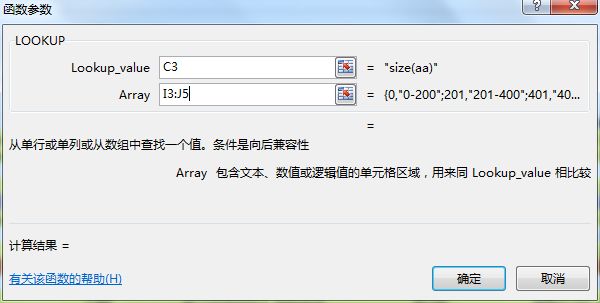
在python中,使用where函数对值进行判断。
df1['group']=np.where(df1['size'] >300,'long','short')
printdf1
输出:
gene size group
0 arx1 411 long
1 arx2 530 long
2 arx3 289 short
3 arx4 450 long
4.分列
即将一列按固定规则分为多列。在excel中,可使用“数据-分列”进行分拆。

在python中,使用split函数。若以“-”为分隔符,对“homo”列中的所有元素进行分割,index与df2保持一致,列重新取名为“category”和“number”,则表达式如下:
df3=DataFrame((x.split('-')forxindf2['homo']),index=df2.index,columns=['category','number'])
printdf3
输出:
category number
0 kana A
1 kana B
2 pdm V
3 pdm V1
5.数据提取
按索引进行提取使用loc函数。
printdf1.loc[:2]
#提取从0至1的数据printdf1.loc[1]
# 提取索引为1的数据
按位置提取,使用iloc函数,将横纵方向标签均从0开始计算。
printdf1.iloc[2,2]
#第三行第三列的数据printdf1.iloc[:3,:3]
# 前三行前三列的数据
同时又按索引又按位置提取,使用ix函数。
df1=df1.set_index('gene')
#将gene设为索引列printdf1.ix[:'arx2',:3]
# 索引arx2之前及0-2列部分
按条件提取,可使用isin函数。Isin函数用来判断是否为给定值,是返回“True”,否返回“False”。将isin函数嵌套如loc函数中,可以输出结果为“True”的数据。
printdf1['group'].isin(['long'])
输出:
0 True
1 True
2 False
3 True
Name: group, dtype: bool
printdf1.loc[df1['group'].isin(['long'])]
输出:
gene size group
0 arx1 411 long
1 arx2 530 long
3 arx4 450 long
6.数据筛选
Excel中可以使用“数据-筛选”根据字段进行筛选。
Python中可使用与、或、非,”&”、”|”、”!=”和loc函数一起进行筛选。例如筛选size>400,homo带有kana的数据:
printdf_inner.loc[(df_inner['size'] >400)&(df_inner['homo'].isin(['kana-A']))]
或者使用query函数进行搜索。
printdf_inner.query('size>400')
本文参考:
Python For Data Analysis
蓝鲸网站分析博客,作者蓝鲸(王彦平)