RabbitMQ基础理论概述
一、什么叫消息队列
我的理解是,不同的程序之前传送数据,这些数据可以是简单的文本数据,也可以是复杂的对象数据。
这些数据由生产者发出,按照先后顺序(先被生产者发出的数据排在前面)顺序,被多个消费者拉取。
生产者发出消息之后,不需要等等消息处理结果的返回,就可以先做其它的事情。
等到消息处理结果返回之后,再做对应的处理。
二、什么情况下用消息队列,消息队列的好处
1、异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
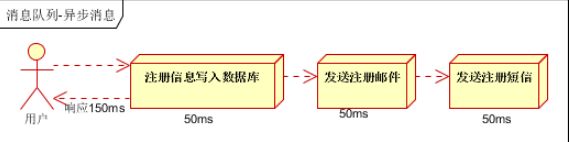
(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间

(3)、引入消息队列
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
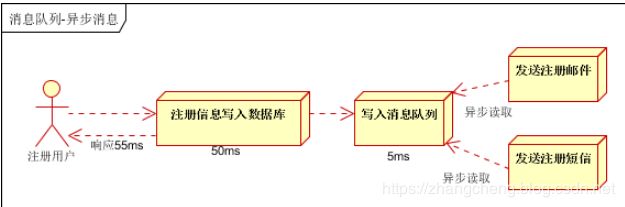
用户的响应时间相当于是注册信息写入数据库的时间+写入到消息队列的时间,一旦写入消息队列之后,马上返回,至于后面的发送邮件和注册短信服务,有消息队列自行处理,发送者这个时候先不管。
所以由此可见,我们可以将一些不是必须即可返回消息的任务,交个消息队列去处理。
生产者发送消息到消息队列之后,马上返回,干其它的事情。
剩下的这些不是需要即刻返回的任务(消息消费者),从消息队列中去取数据,做出相应的处理,然后再返回到生产者端。
2、应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图
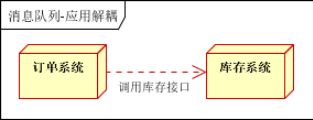
传统模式的缺点:
这两个系统之后过于耦合,万一库存系统出问题,订单系统也会失败
引入应用消息队列后的方案,如下图:

订单系统发送消息到消息队列,发送完成之后,订单系统就可以看其它的事情,不用管了。这条消息存在消息队列里面,由库存系统自己去拉取,昨晚具体操作之后,再返回结果到订单系统。订单系统收到库存系统的执行成功的操作之后(用某个状态标识来判断成功或者失败),再执行对应的操作。
3、流量削锋
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
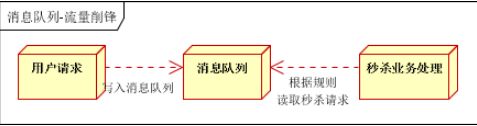
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
实际上就是利用消息队列的最大数量,限制请求次数,反正系统崩溃。
三、AMQP协议模型:
RabbitMQ就是基于AMQP协议模型的,我们来看下这个模型:
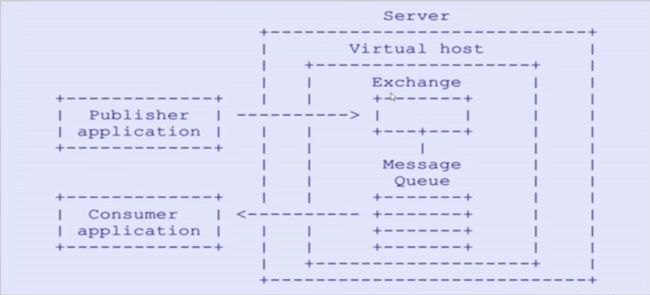
说明:
publisher生产者发送消息到server(消息服务器),
server里面有多个virtualHost(虚拟主机,可以看成server里面的第一个路由器,消息先按虚拟主机来划分存储位置),
每个virtualHost里面又有多个或者一个(靠自己定义)Exchange(交换器),生产者把消息发送到交换器就结束任务了
(剩下的事情怎么处理,于生产者无关)
Consumer消费者从messageQueue里面拉取消息,做出对应的处理
那么这个时候问题来了,生产者只把消息发送到Exchange(交换器)就完事了,消费者从messageQueue里面拉取的消息是从哪里来的呢?
这个时候就需要靠Routing Key来判断,发送的消息里面是带有Routing Key的,Exchange(交换器)会将Routing Key和对应的消息队列进行绑定。这样就可以判断消息应该存储到哪个消息队列了。
四、RabbitMQ运行流程图解:
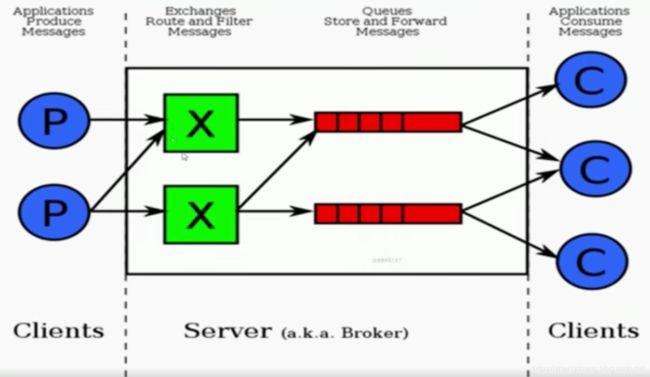

可以看到,这个RabbitMQ的流程和AMQP协议模型一模一样。
五、RabbitMQ 基本概念:
1、Message(消息):
由消息主体和消息头组成,消息主体就是要传递的数据,消息头是一些描述性的属性:
比如:routing-key(路由键)、
priority(相对于其他消息的优先权)、
delivery-mode(指出该消息可能需要持久性存储)等
2、Publisher
消息的生产者,也是一个向交换器发布消息的客户端应用程序。
3、Exchange
交换器,生产者把消息发送到交换器上,交换器上根据路由规则判断将消息存储到哪个具体的消息队列上。
4、Binding
绑定,消息队列和交换器之间的关联。
一个绑定就是基于生产者发送过来的消息头里面的路由键,将交换器和消息队列连接起来的路由规则,
所以可以将交换器理解成一个由绑定构成的路由表。
5、Queue
消息队列,消费者就是从这里将数据取出的。
6、Connection
网络连接,将生产者和消费者与消息中间件RabbitMQ联系起来。
7、Channel
信道,我感觉就和session会话差不多,所有的消息存取增删操作都是通过这个Channel来完成。
8、Consumer
消费者,从表示一个从消息队列中取得消息的客户端应用程序。
9、Virtual Host
我感觉就是一个RabbitMQ节点(server),通过Virtual Host划分出多份逻辑空间,
主要是用来做第一层消息路由的,比如订单消息发送到名称为A的Virtual Host,然后由A里面的交换器和队列来处理消息。
库存消息发送到名称为B的虚拟节点
10、Broker
节点,实际上就是一个RabbitMQ服务实例。
六、消息路由:
生产者把消息发布到 Exchange 上,消息最终到达队列并被消费者接收,而 Binding 决定交换器的消息应该发送到那个队列。Binding 就是发送过来的消息头里面的路由键和具体消息队列的关联。
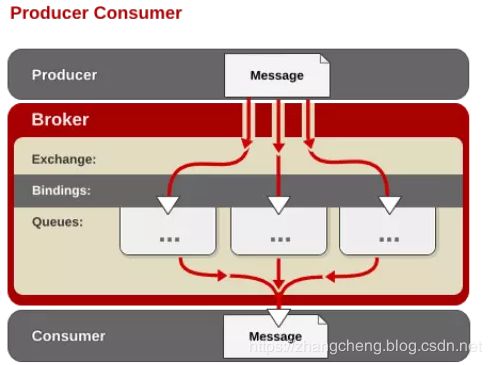
Exchange 类型:
交换器路由规则分为以下几种:
1、direct(完全匹配)

说明:
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致,才会将消息发送到对应的队列中。
2、fanout(不匹配,全发)

说明:
只要是跟这个交换器进行了绑定的消息队列,就发送消息到这些队列上。
3、topic(模糊匹配)

说明:
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配。比如模式为:usa.#,那么路由键只要是usa.开头的,都可以发送消息到binding.key为usa.开头的队列上。