Python爬虫实例 wallhaven网站高清壁纸爬取。
文章目录
- Python爬虫实例 wallhaven网站高清壁纸爬取
- 一.数据请求
- 1.分析网页源码
- 2.全网页获取
- 二、数据处理
- 1.提取原图所在网页链接
- 2.获取高清图片地址及title
- 三、下载图片
- 四、附录
- **完整代码:**
- **部分成果展示:**
Python爬虫实例 wallhaven网站高清壁纸爬取
本文记录使用python爬虫在wallhaven网站上爬取排行榜中的高清壁纸的过程。
一.数据请求
网站wallhaven简介:
一个网页十分美观舒适的网站,可下载丰富的高清壁纸,图片像素质量极高,分类合理。个人非常推荐这个网站的壁纸,特别好评。
爬取地址:https://wallhaven.cc/toplist
此为壁纸的排行榜,我们将从排行榜中获取壁纸。
1.分析网页源码
wallhaven月榜单:
右键单击第一张图片检查网页
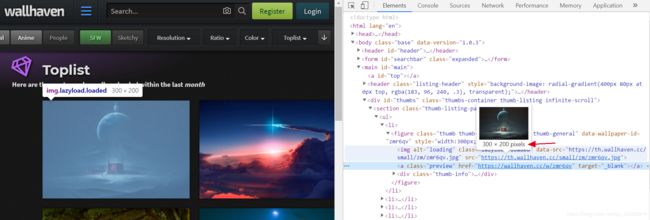
查看代码发现该图片只是一张预览图片,分辨率仅为300*200,明显不符合要求。
观察下方a标签

发现这个class为preview的标签中存在个href地址链接到该高清图片的正确地址,点击该地址跳转
这里才是我们想要的内容,继续检查图片源码
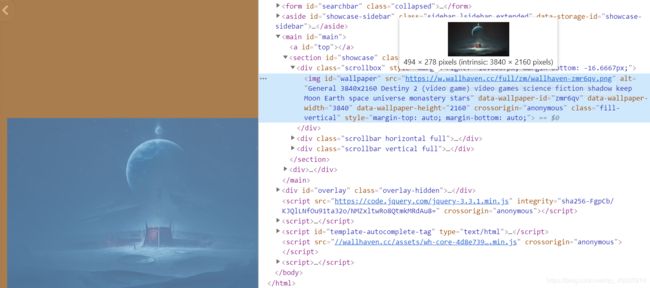
找到了我们要的图片链接,在img标签中。
2.全网页获取
方式一:request
from urllib import request
url = 'https://wallhaven.cc'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.122 Safari/537.36 '
} # 请求头,用于反反爬
req = request.Request(url, headers=headers)
resp = request.urlopen(req)
print(resp.read())
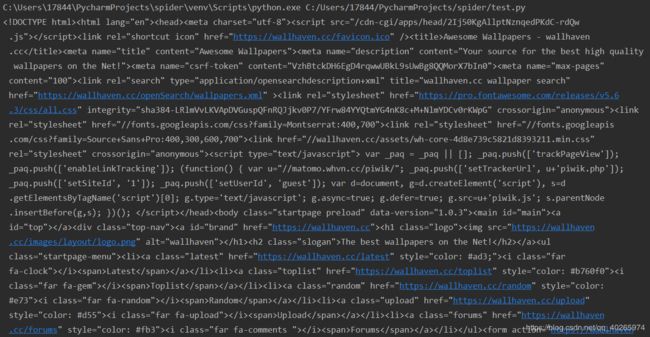
成功爬取到整个网页内容。

方式二:requests_html
from requests_html import HTMLSession # 用于数据请求、数据提取、相较于其他库更加简洁方便
session = HTMLSession()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'} # 请求头,用于反反爬
r = session.get('https://wallhaven.cc', headers=headers)
print(r.text)
同样成功。
二、数据处理
1.提取原图所在网页链接
(此处直接将所有链接获取,后续用try方式排除异常链接)
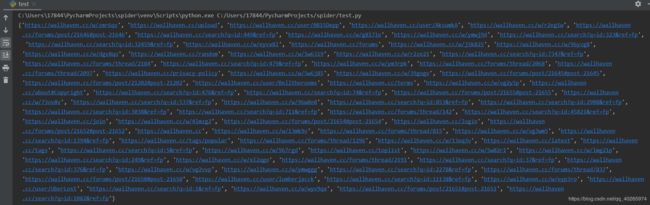
links和absolute_links两个属性分别返回HTML对象所包含的所有链接和绝对链接(均不包含锚点)。
print(r.html.links)
print(r.html.absolute_links)
此处选用html.links
2.获取高清图片地址及title
通过替换url再次请求得到src下的地址和后面的alt标签
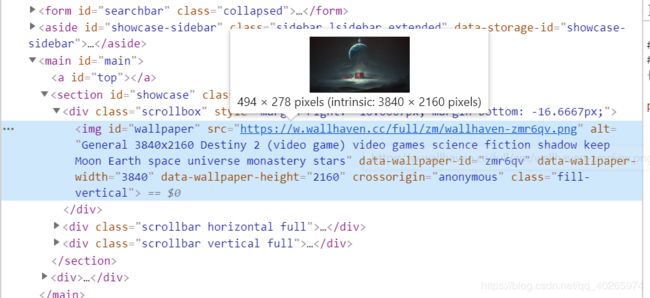
for url in urls:
try:
session1 = HTMLSession()
r1 = session1.get(url)
sr = r1.html.find("img#wallpaper", first=True)
image_url = sr.attrs['src']
image_title = sr.attrs['alt']
print(image_url)
print(image_title)
#down_pic(image_url)
except BaseException as e:
print(e)
成功抛出了异常链接
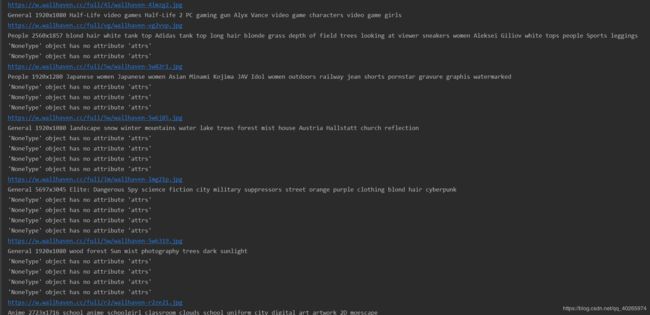
三、下载图片
通过request库函数中的request.urlretrieve(image_url, path)来下载图片,path为存储的位置。
def down_pic(image_url):
try:
path = 'D:\爬取内容\一年榜\{}'.format((image_title.split('/')[-1]) + (image_url.split('/')[-1]))
print(path)
opener = request.build_opener()
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36')]
request.install_opener(opener)
request.urlretrieve(image_url, path)
except Exception as m:
print(m)
打印的部分结果:

注:
split:字符串分割,用于上面分别为【title】.【后缀】,确保图片格式同源。
此处必须加上请求头,这里网站有简单的反爬,加上请求头即可。
opener = request.build_opener()
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36')]
四、附录
完整代码:
爬取更多页图片请将range调大至更高页。
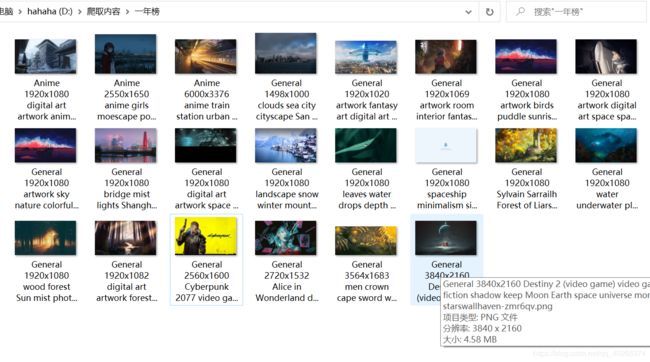
上面展示了月榜单的图片,实际爬取的是年榜单,修改get网址即可,不再作说明。
from requests_html import HTMLSession # 用于数据请求、数据提取、相较于其他库更加简洁方便
from urllib import request # 本例中该库只用于下载保存图片
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'} # 请求头,用于反反爬
session = HTMLSession()
urls = []
for i in range(1, 3):
# r = session.get('https://wallhaven.cc/toplist?page={}'.format(i))
r = session.get('https://wallhaven.cc/search?categories=110&purity=100&topRange=1y&sorting=toplist&order=desc&page={}'.format(i))
urls = r.html.links
print(urls)
def down_pic(image_url):
try:
path = 'D:\爬取内容\一年榜\{}'.format((image_title.split('/')[-1]) + (image_url.split('/')[-1]))
print(path)
opener = request.build_opener()
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36')]
request.install_opener(opener)
request.urlretrieve(image_url, path)
except Exception as m:
print(m)
for url in urls:
try:
session1 = HTMLSession()
r1 = session1.get(url)
sr = r1.html.find("img#wallpaper", first=True)
image_url = sr.attrs['src']
image_title = sr.attrs['alt']
print(image_url)
print(image_title)
down_pic(image_url)
except BaseException as e:
print(e)
部分成果展示:
备注:1.网站非中文网,下载速度较慢,下载时间较长。
2.相关知识参见博主相关博客。