MySQL知识点总结(重点分析事务)
范式
数据库三种范式如下。
| 范式 | 描述 | 反例 |
|---|---|---|
| 第一范式 | 每个字段都是原子的,不能再分解 | 某个字段是JSON串,或者是数组 |
| 第二范式 | 1) 表必须有主键,可以是多个顺序属性的组合。2) 非主属性必须完全依赖主属性(这里指的是组合主键),而不能部分依赖。 | 好友关系表中,主键是关注人ID和被关注人ID,表中存储的姓名等字段只依赖主键中的一个属性,不完全依赖主键 |
| 第三范式 | 没有传递依赖(非主属性必须直接依赖主属性,不能间接依赖主属性) | 在员工表中,有部门ID和部门名称等,部门名称直接依赖于部门ID,而不是员工ID |
一般工程中,对于数据库的设计要求达到第三范式,但这不是一定要遵守的,所以在开发中,为了性能或便于开发,出现了很多违背范式的设计。如冗余字段、字段中存一个JSON串,分库分表之后数据多维度冗余存储、宽表等。
B+树
关于B树和B+树的概念,请见漫画算法:什么是 B+ 树?
B+树的逻辑结构
下面来看一下数据库中主键索引对应的B+树的逻辑结构。

该结构有几个关键特征(与一般的B+树有点不同)
- 在叶子节点一层,所有记录的主键从小到大的顺序排列,并且形成了一个双向链表,叶子节点的每一个Key指向一条记录。
- 在非叶子节点一层,每个非叶子节点都指向叶子节点中值最小的Key(但非叶子节点不存储记录),同层的非叶子节点也形成一个双向链表。
基于B+树的这几个特征,就可以很容易的实现范围查询、前缀匹配模糊查询、排序和分页(查询条件应是索引)。这里有几个要注意的问题。
- 模糊查询不应该使用后缀匹配或者中间匹配,因为索引的排序是按照从小到大排序的,只有前缀相同的才会被排列在一起,否则就用不上索引了,只能逐个遍历。
- 对于ofset这种特性,其实是用不到索引的。比如
select *** where *** limit 100, 10,数据库需要遍历前面100条数据才知道offset=100的位置在哪。合理的分页方法就是不使用offset,把offset变成条件来查询。比如变成select *** where *** and id > 100 limit 10,这样才能利用索引的遍历,快速定位id=100的位置。
事务与锁
事务的四大特性ACID。
- 原子性(A):事务要么不执行,要么完全执行。(如果执行到一半机器宕机了,已执行的部分需要回滚回去)。
- 一致性©:各种约束条件,比如主键不能为空,参照完整性等。
- 隔离性(I):只要事务不是串行的,就需要隔离(一般都是并行的,效率更高嘛)。
- 持久性(D):一旦事务提交了,数据不能丢失。
事务与事务并发地操作数据库的表记录,可能会导致下面几类问题。
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务A读取了另一个未提交的事务B的数据,但是事务A提交之前,事务B又回滚了,导致事务A刚刚读到的就是一个脏数据(RC隔离级别可解决)。 |
| 不可重复读 | 同一个事务两次查询同一行记录,得到的结果不一样。因为另一个事务对该行记录进行了修改操作(行排它锁可解决)。 |
| 幻读 | 同一个事务两次查询某一范围,得到的记录数不一样,因为另一个事务在这个范围内进行了增加或删除操作(临键锁可解决)。 |
| 丢失更新 | 两个事务同时修改同一行记录,事务A的修改被后面的事务B覆盖了(需要自己加锁来解决)。 |
下面来看一下InnoDB的事务隔离级别。可解决上面的三个问题,最后一个问题只能在业务代码中解决。
| 名称 | 描述 |
|---|---|
| READ_UNCOMMITTED(RU) | 跟没有一样,几乎不使用。 |
| READ_COMMITTED(RC) | 只能读取另一个事务已提交的事务,能防止脏读。 |
| REPEATABLE_READ(RR) | 可重复读(在一个事务内多次查询的结果相同,其它事务不可修改该查询条件范围内的数据,会根据条件上Gap 锁) |
| SERIALIZABLE | 所有的事务依次逐个执行,相当于串行化了,效率太低,一般也不使用。 |
关于数据库的锁,请详见这篇。MySQL中的“锁”事
事务实现原理1(Redo Log)
Write-Ahead
为了保证数据的持久性,需要每提交一个事务就刷一次磁盘,但是这样效率太低了,所以就有了Write-Ahead。
Write-Ahead:先在内存中提交事务,然后写日志(在InnoDB中就是redo log,日志是为了防止宕机导致内存数据丢失),然后再后台任务中把内存中的数据异步刷到磁盘。
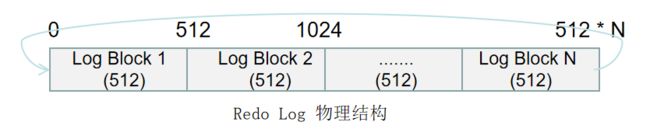
Redo Log的逻辑与物理结构
从逻辑上来讲,日志就是一个无限延长的字节流,从数据库启动开始,日志就一直在增加,直到数据库关闭。
在逻辑上,日志是按照时间顺序从小到大用LSN(是一个64位的数)来编号的,因为事务有大有小,所以日志是个变长记录(每一段数据量都不一样)。

从物理上来讲,日志不可能是一个无限延长的字节流,因为每个文件有大小限制。在物理上是整块的读取和写入(这里就是Redo Log 块,一个块就是512字节),而不是按字节流来处理的。而且日志是可以被覆写的,因为当数据被刷到磁盘上后,这些日志也就没有用了,所以他们是可以被覆盖的。可循环使用,一个固定大小的文件,每512字节一个块。
Physiological Logging
在InnoDB中,Redo Log采用先以Page为单位记录日志(物理记法),每个Page里再采用逻辑记法(记录Page里的哪一行修改了)。这种记法就叫做Physiological Logging。
之所以采用这种记法,是逻辑日志和物理日志的对应关系决定的。
- 一条逻辑日志可能会产生多个Page的物理日志。因为一个表可能有多个索引,每个索引都是一个B+树,更新一条记录(一个逻辑日志),但这可能会同时更新多个索引,导致产生了多个Page的物理日志。
- 就算一条逻辑日志对应一个Page,也可能会修改这个Page的多个位置(在中间插入一条记录,需要修改Page的多个位置)。
事务崩溃恢复分析
未提交的事务日志也在Redo Log中
因为不同事务的日志在Redo Log中是交叉存在的,所以没法把未提交的事务与已提交的事务分开。ARIES算法的做法就是,不管事务有没有提交,它的日志都会被记录到Redo Log上并刷到磁盘中。当崩溃恢复的时候,会把Redo Log全部重放一遍(不管是提交的还是未提交都都重做了,也就是完全恢复到崩溃之前的状态),然后再把未提交的事务给找出来,做回滚处理。
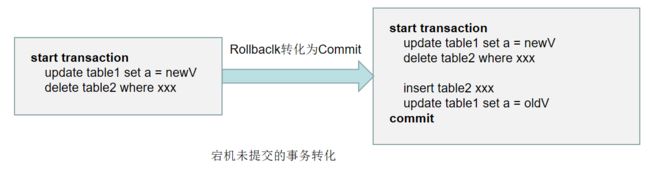
Rollback转化为Commit
其实事务的回滚都是反向提交。也就是根据事务中的SQL语句生成反向对应的SQL语句执行,然后Commit(这种逆向的SQL语句也会被记录到Redo Log中,防止恢复中宕机,但是会与正常的日志区分开),所以回滚是逻辑层面上的回滚,在物理层面其实是个提交。
ARIES算法
如下图,有六个事务,每个事务所在的线段表示事务在Redo Log中的起始位置和结束位置。发生宕机时,需要回滚事务T3、T4、T5。
在图中,绿线表示两个Checkpoint点和Crash(宕机)点。蓝线表示三个阶段工作的起始位置。
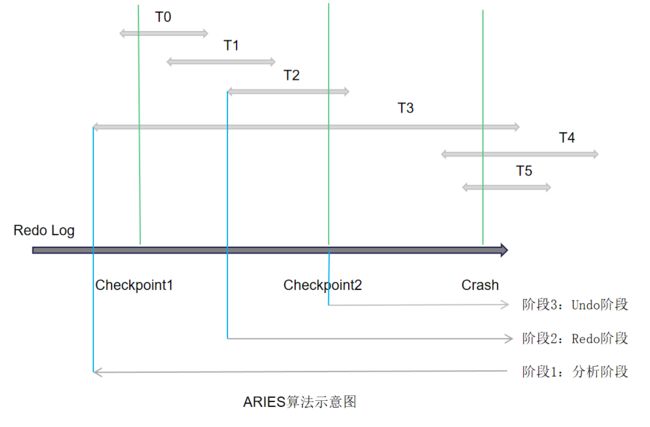
阶段1:分析阶段
在分析阶段,要解决两个问题。
1)确定哪些数据页是脏页,为阶段2的Redo做准备(找出从最近的Checkpoint到Crash之间所有未刷盘的Page)。
2)确定哪些事务未提交,未阶段3的Undo做准备(因为未提交的事务也写进了Redo Log中,需要将这些事务找出来,并做回滚)。
ARIES的Checkpoint机制,一般使用的是Fuzzy Checkpoint,它在内存中维护了两个表,活跃事务表和脏页表。
1)活跃事务表:当前所有未提交事务的集合,每个事务维护了一个关键变量lastLSN(该事务产生的日志中最后一条日志的LSN)。
2)脏页表:当前所有未刷到磁盘上得Page的集合(包括未提交事务和已提交事务),recoveryLSN是导致该页为脏页的最早LSN(最近一次刷盘后最早开始的事务产生的日志的LSN)。
每次Fuzzy Checkpoint,就是把这两个表的数据生成一个快照,形成一条checkponit日志,记入Redo Log中。
下图展示了事务的开始标志(S表示Start transaction),结束标志(C表示Commit)以及Checkpoint在Redo Log中的位置(这里只展示了活跃事务表,脏页表也是类似的,唯一不同的就是脏页集合只会增加,不会减少,脏页集合中可能有些页是干净的,但由于Redo Log是幂等的,所以不影响)。

阶段2:进行Redo
阶段1中已经准备好了脏页集合,取集合中脏页的recoveryLSN的最小值(也就是最早开始脏的那一页),得到firstLSN,在Redo Log中从firstLSN开始遍历到末尾,把每条Redo Log对应的Page全部重新刷到磁盘中。但是这些脏页中可能有些页并不是脏的,所以这里要做幂等。也就是利用Page中的一个PageLSN字段(它记录了当前Page刷盘时最后一次修改它的日志对应的LSN),在Redo重放的时候,判断如果日志的LSN比磁盘中得PageLSN要小,那就直接略过(这点非常类似TCP的超时重发中的判重机制)。在Redo完成后,保证了所有的脏页都刷到了磁盘中,并且未提交事务也写入了磁盘中,这时需要对未提交事务进行回滚,也就是阶段3。
阶段3:进行Undo
阶段1中已经准备好了未提交事务集合,从最后一条日志逆向遍历(每条日志都有一个preLSN字段,指向前一条日志),直到未提交事务中的第一条日志。
从后往前开始回滚,每遇到一条属于未提交事务集合中事务的日志,就生成一条对应的逆向SQL(这里需要用到对应的历史版本数据)执行,这条逆向SQL也会被记录到Redo Log中,但与一般的日志有所不同,称为Compensation Log Record(CLR),逆向执行完事务后(遇到事务的开始标志)就提交,这也就完成了回滚。
事务实现原理2(Undo Log)
Undo Log功能
上面在宕机回滚中,提到了生成逆向SQL,这个是需要使用到历史版本数据的。Undo Log就是用于记录和维护历史版本数据的(事务的每一次修改,就是一个版本)。其实这是用到了CopyOnWrite的思想,每次事务在修改记录之前,都会把该记录拷贝一份出来(将它备份在Undo Log中)再进行修改操作(这个思想类似JDK中CopyOnWriteArratList)。事务的RC、RR隔离级别就是通过CopyOnWrite实现的。
并发的事务,要同时读写同一行数据,只能读取数据的历史版本,而不能读取当前正在被修改的数据(所以这样就有了丢失更新的问题,当然这个可以通过加锁等方式解决)。这种机制称为Multiversion concurrency control 多版本并发控制(MVCC)。基于MVCC的这种特性,通常select语句都是不加锁的,因为他们读到的都是历史版本的数据,这种读,叫做“快照读”。
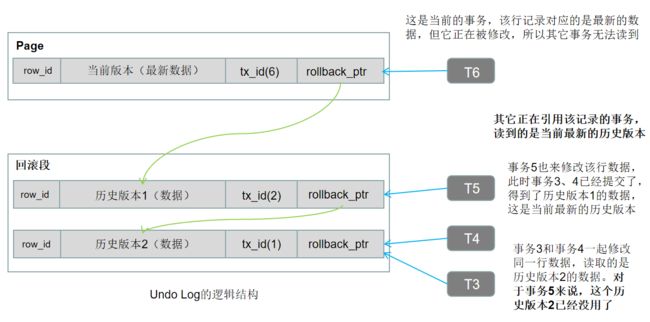
Undo Log结构
Undo Log并不是log,而是数据(所以Undo Log也会被记录到Redo Log中,在宕机后用Redo Log来恢复Undo Log),它记录的不是事务执行的日志,而是数据的历史版本。一旦事务提交后,就不需要Undo Log了(它只在事务提交过程中有用)。
所以Undo Log应该叫做记录的备份数据,也就是在事务提交之前的备份数据(因为可能有其它事务还在引用历史版本数据),事务提交后它就没有用了。
Undo Log的结构除了主键ID和数据外,还有两个字段。一个是修改该记录的事务ID,一个是rollback_ptr(指向之前的一个版本,所以它用来串联所有的历史版本)。
BinLog与主从复制
Binlog与Redo Log
- Redo Log主要是用于实现事务的日志,而Binlog主要是用于主从复制的日志(也可以用于实现主动更新缓存)。
- Redo Log是InnoDB引擎中的,并且事务在日志中是交叉排列(可并行写入)的。而Binlog是MySQL层面的,事务在日志中是连续排列(只能串行写入)的,并且全局只有一份。
- Redo Log可以并行写入,而且未提交的事务也会被写入。Binlog只能串行写入(可通过Group Commit解决效率问题,类似pipeline机制),并且Binlog中只记录已提交的事务。
内部XA
内部XA就是内部的分布式事务,也就是Redo Log与Binlog之间的事务,一般使用2阶段提交方案。
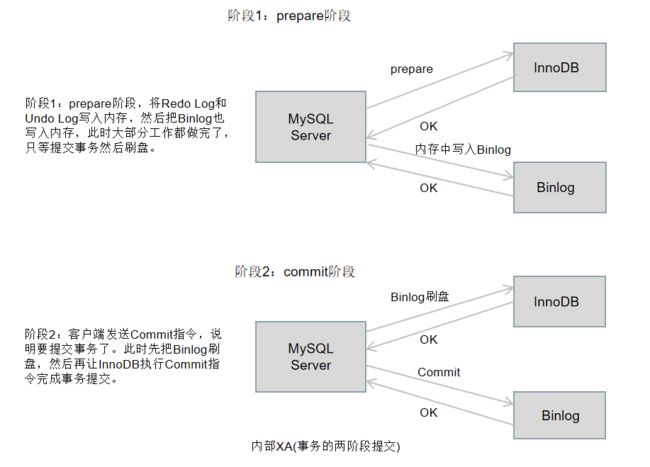
Binlog中只记录已提交的事务,所以以Binlog刷盘成功来判断一个事务是否被提交。如果宕机了,分以下三种情况讨论。
- 在阶段1宕机,此时Binlog全在内存中或还没写入内存,Redo Log可以自己回滚,没有影响。
- 在阶段2宕机,此时Binlog还没刷盘完,Binlog可以通过类似Checksum的方法来判断不完整的部分,并把这段截断。Redo Log同上。
- 在阶段2宕机,此时Binlog刷盘结束,InnoDB还没提交,因为Binlog已经持久化了,可以根据Binlog来恢复事务的提交。
主从复制
MySQL有三种主从复制的方式。同步复制因为效率太低,一般不会使用,而异步复制虽然快,但是容易丢失数据,所以一般使用半同步复制。
| 复制方式 | 描述 |
|---|---|
| 同步复制 | 等待所有的slave都接收到了Binlog,才向客户端返回事务提交成功 |
| 异步复制 | 只要Master事务提交成功,立刻向客户端返回事务提交成功,然后通过后台线程异步地向slave同步Binlog。 |
| 半同步复制 | Master事务提交成功后,向slave同步Binlog,只要有部分slave(默认是1)接收到了Binlog,就向客户端返回事务提交成功。 |
并行复制
下图展示了MySQL的主从复制的原理,其中阶段2使用了并行回放。这就是并行复制。

所谓的并行回放,其实就是一次性从RelayLog中取出多个事务,然后通过多个线程并行的执行。