猫眼top前100电影爬取demo(正则初试)
import json
import requests
import re
def get_one_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?.*?>(.*?).*?releasetime.*?>(.*?).*?integer">(.*?).*?fraction">'
'(.*?).*? ',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index':item[0],
'title':item[1],
'image':item[2],
'actor':item[3].strip()[3:],
'time':item[4],
'score':item[5]+item[6]
}
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
def main(number):
url = 'https://maoyan.com/board/4?offset=' + str(number)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
for i in range(10):
main(i * 10)
def get_one_page(url):
首先获取页面信息(这里通过尝试,并没有网页没有对爬虫进行限制),定义了一个函数
requests库简单应用
https://www.cnblogs.com/ronghe/p/9159686.html
这里参考上丄博客;
1,requests.get("http://www.baidu.com")
使用基本get请求,获取网页内容,返回一个Response对象
>>> print(type(requests.get("http://www.baidu.com")))
接下来对于这个对象进行处理:Response 对象包含服务器返回的所有信息,也包含请求的 Request 信息
| r.status_code | HTTP 请求的返回状态码 |
返回请求状态码,这里200为返回正常
| r.text | HTTP 响应内容的字符串形式,即:URL 对应的页面内容 |
| r.encoding 为预计编码方式 r.apparent_encoding 为实际网页编码方式 |
通过响应属性里面的r.text HTTP 响应内容的字符串形式,即:URL 对应的页面内容
得到我们想要的原网页代码信息。
异常处理(防止程序直接崩溃掉)
异常处理格式:
try:
程序部分
expect Exception as 异常名称:
异常处理部分这里异常一般定义在循环里边,对于循环体进行异常处理,跳出此次循环接着进行下次循环
def parse_one_page(html):
yield 这里是个生成器。
其次获取网页源代码后,进行提取需要的数据
这里使用正则表达式,依据网页源码进行对比,将需要的数据放在()里,进行数据提取。
这里正则需要与源码进行比对,否则会出错:
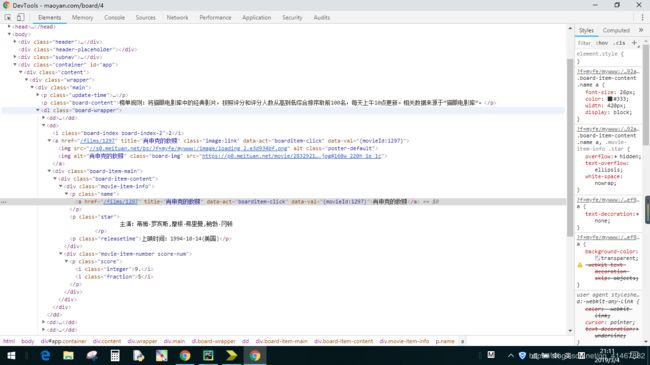
这里源码进行比对
def write_to_file(content):
这里写入文件,
遗留问题:
写入的时候只能使用‘a‘的方式进行写入,其他方式会出现问题,具体后续补加。
写入分别写入排名,标题,图片链接,主演上映时间与评分

问题遗留:
所有的代码具体问题后续补加,这里先贴代码以及简单思路。