使用hive+hbase做数据分析
数据来源:中国软件杯—基于互联网大数据的招聘数据智能分析平台
使用工具:eclipse
环境搭建:hadoop,hive,mysql,hbase,tomcat
博客只做数据分析的流程与方法介绍,代码还在完善中,所以不做提供
闲话不多说,直接展示效果图
1.数据清洗
拿到数据集后发现数据并不是很规整,需要做一些处理,比如说去除制表符,去空或者是换行符等等,这里的处理方法比较简单,可以使用python或是java快速清洗处理。
2.数据分析(hive分析处理)
UDF分析:
UDF也就是用户自定义的函数,用于HiveQL语句中,HiveQL使用方法与Mysql类似
使用UDF做数据分析:(这里给出行键与薪资分类的方法)
1. 行键UDF的使用:
package com.org.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class get_rowkey extends UDF {
public String evaluate(int i,String key) {
long get_currentTimeMillis =System.currentTimeMillis();//获取当前时间的时间戳
long timestamp =get_currentTimeMillis+i;//参数i作为自增数,防止时间戳相同
String rowkey = timestamp+key;//参数key作为行键识别字符串,用于hbase的行键过滤器
return rowkey;
}
}
注意:类需要继承UDF,重写evaluate方法,在hiveql中自定义函数入口就是evaluate方法
使用eclipse打包,右键点击UDF的文件,选择Export
选择JAR file 进行打包
2. 薪资分区UDF:
package com.org.udf;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//薪资
public class get_salary {
//转换单位
public String evaluate(String job_salary) {
String pattern = "([^0-9_-]+)";//匹配除了数字与”—“符号
String pattern2 = "(^\\d+)";//匹配数字
Pattern r = Pattern.compile(pattern);// 创建 Pattern 对象 对单位进行判断
Pattern r2 = Pattern.compile(pattern2);
Matcher m = r.matcher(job_salary); // 现在创建 matcher 对象
Matcher m2 = r2.matcher(job_salary);
int salary = 0;
if (m.find( )&&m2.find()) {
if(m.group(1).equals("万/月")) {
salary = Integer.valueOf(m2.group(1))*10;//获取第一个数字,统一单位为千
return get_salary_range(salary);
}else if(m.group(1).equals("万/年")) {
salary = Integer.valueOf(m2.group(1))*10/12;
return get_salary_range(salary);
}else if(m.group(1).equals("万")) {
salary = Integer.valueOf(m2.group(1))*10/12;
return get_salary_range(salary);
}else if(m.group(1).equals("")) {
salary = Integer.valueOf(m2.group(1));
return get_salary_range(salary);
}else if(m.group(1).equals("元/月")) {
salary = Integer.valueOf(m2.group(1))/1000;
return get_salary_range(salary);
}else if(m.group(1).equals("元/天")) {
salary = Integer.valueOf(m2.group(1))*30/1000;
return get_salary_range(salary);
}else if(m.group(1).equals("k")||m.group(1).equals("K")) {
salary = Integer.valueOf(m2.group(1));
return get_salary_range(salary);
}else if(m.group(1).equals("元/小时")) {
salary = Integer.valueOf(m2.group(1))*30*9/1000;
return get_salary_range(salary);
}else if(m.group(1).equals("千/月")) {
salary = Integer.valueOf(m2.group(1));
return get_salary_range(salary);
}else {
salary = 0;
return get_salary_range(salary);
}
} else {
salary = 0;
return get_salary_range(salary);
}
}
//放到薪资对应区间
public String get_salary_range(int salarys) {
if(salarys>0&&salarys<4) {
return "0-04K以下";
}else if(salarys>=4&&salarys<=8) {
return "04K-08K";
}else if(salarys>8&&salarys<12) {
return "08K-12K";
}else if(salarys>=12&&salarys<16) {
return "12K-16K";
}else if(salarys>=16&&salarys<20) {
return "16K-20K";
}else if(salarys>=20&&salarys<=24) {
return "20K-24K";
}else if(salarys>24&&salarys<28) {
return "24K-28K";
}else if(salarys>=28&&salarys<32) {
return "28K-32K";
}else if(salarys>=32) {
return "32K以上";
}else {
return "查询失败";
}
}
}
接下来同样打包。
UDF应用:
添加jar包,创建临时函数
add jar /home/ubuntu/RowKey.jar;
add jar /home/ubuntu/Salary.jar;
create temporary function rowkey as 'com.org.udf.get_rowkey';
create temporary function salary as 'com.org.udf.get_salary';
HIveQL使用:
select rowkey(row_number() over(partition by 1 order by job_salary),"jobs_salary") as rowkey,
t.job_salary from (select salary(job_salary) as job_salary,count(1) as c from recruitment.clean
group by job_salary HAVING job_salary!="查询失败") as t;
(row_number() over(partition by 1 )是hive的自增函数,目的是使行键不重复
order by job_salary 是对salary字段进行排序
recruitment.clean 是数据清洗后导入到hive的表
hiveql语句结果部分截图如下:

hiveql语句具体用法可以百度查找,这里只做流程介绍与方法应用,不做详细分析
3.数据导入(数据保存到hbase)
创建hive与hbase的数据关联表
CREATE TABLE recruitment.jobs_salary(
rowkey string,salary string
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:job_salary")
TBLPROPERTIES ("hbase.table.name" = "hbase_jobs");
rowkey string,salary string这两个字段对应hbase中的:key,info:job_salary,也就是行键与info列族下的job_salary列
使用hiveql导入hbase表
insert overwrite TABLE recruitment.jobs_salary
select rowkey(row_number() over(partition by 1 order by job_salary),"jobs_salary") as rowkey,
t.job_salary from (select salary(job_salary) as job_salary,count(1) as c from recruitment.clean
group by job_salary HAVING job_salary!="查询失败") as t;
注意:有其他数据需要插入到同一张hbase表,只需要在新建一张关联表,但是需要添加关键词external,也就是CREATE external TABLE,导入数据到不同hbase列时,只需修改对应的列族与列
到此,我们可以在hbase shell中查看自己刚建立的表与数据,接下来就是java web获取hbase的数据,再将数据可视化出来
4.数据可视化(获取hbase数据进行展示)
连接habse
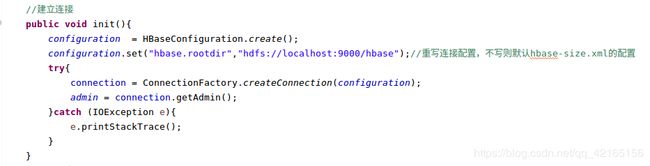
获取数据
Scan scan = new Scan();
//定义过滤器,单列值过滤器
SingleColumnValueFilter singleColumValueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"),
Bytes.toBytes("job_salary"),
CompareFilter.CompareOp.EQUAL,new BinaryComparator(tag_from_user.getBytes()));
QualifierFilter qualifierFilter1 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(one_qualifier)));
//将过滤器添加到过滤列表中
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL);
filterList.addFilter(singleColumValueFilter);
scan.setFilter(filterList);
获取hbase数据,用的是hbase的过滤器功能,过滤后获取指定的数据,再将数据转换为展示所需要的数据格式,例如,用echart进行展示,则数据格式一般都是josn格式,具体看百度echarts教程最后进行数据的展示
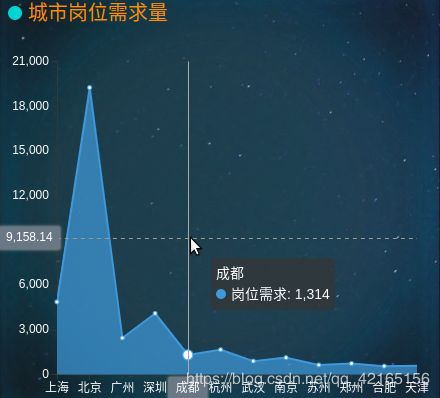
展示结果

数据分析流程到此结束,有更好的做法或是对以上流程有任何不懂的,欢迎评论留言