马蜂窝评论爬取
`分析网址
https://w.mafengwo.cn/sfe-app/cmt_list.html?busi_type=customize&mdd_id=10183
网址返回的评论数据是json格式。

但是返回的数据进行了字体加密,我们需要对它进行破解。字体反爬的详细步骤我在猫眼电影反爬中有所介绍。
查看器搜索woff:

第一次找到的是带woff的图片,我们需要按enter键继续搜索,直到找到
https://wpstatic.mafengwo.net/msales/salesstatic/css/mfw-comments-font/v1/MFWCOMMENTSV1.woff
下载后用FontCreater打开:

接下来需要把woff文件转化为xml文件来分析规律:
import os
import requests
from fontTools.ttLib import TTFont
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(base_dir)
woff_dir = os.path.join(base_dir, r"D:\PycharmProjects\untitled\爬虫\蜂蜂点评/")
file_name = 'MFWCOMMENTSV1.woff'
xml_name = file_name.replace(file_name.split(".")[-1], "xml")
save_woff = os.path.join(woff_dir, file_name)
save_xml = os.path.join(woff_dir, xml_name)
'''
resp = requests.get(url=url)
with open(save_woff, "wb") as f:
f.write(resp.content)
f.close()
'''
font = TTFont('MFWCOMMENTSV1.woff')
print(font.getGlyphOrder())
font.saveXML(save_xml) # 转换为xml文件
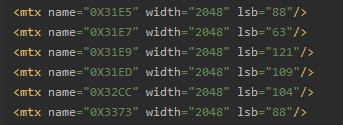
分析发现lsb相同的对应的文字相同,这样我们就可以获得字体和编码对应的字典:
#-*-coding:utf-8 -*-
from fontTools.ttLib import TTFont
font = TTFont('MFWCOMMENTSV1.woff')
name = font.getGlyphOrder()[13:]
name1 = []
for i in name:
name1.append(i.lower())
print(name1)
b = []
dict = {}
for i in name:
ls = font['hmtx'][i][1]
b.append(ls)
ocr = u'开好值下选让客每次持下最谢续待供可选谢方非推师荐务有机上人真体理你一品行服评值务开行品风就还加合机亲排加一得来感选还在一朋持客傅玩评是路人导期很工再多非我大次活力还是机个说友美价间我客很给傅特为活旅务理与傅感出作感给出一美续风店祝提祝谢不店以行谢验还认上我也工小酒价上来认服出去作再哦安团感理愉供不朋讲没得我是合生意团位价美别团荐快就美去了方谢没司就工评解景支作非一每风非美没到行对就常期常还谢地您客酒人提得非能继时谢路可快这了好服续的旅路对验感行与个景会您意提定生行和谢供会定常您师感您快次程多的旅一品待亲能很力满景可希努好这位来一心您一推肯讲常真人很不友程肯游很这评师支会别和定谢景开次好好让下能以希非游人游也是一体更以继位推常哦亲常努次们最望每谢谢愉都也间是产你次更荐有满说感解到肯可希值服生与游错有认点可产大择好方景次一司就可景导都朋路你说最店间一望酒谢真次哦路小旅心点人们好的合别的时谢产您意旅活解不我到再游客排司持是不谢错验望是排是就待次您行多错讲点服评次美和在了努更特玩支安客特加您安继次都感路的评大您在还择地有对很不为玩择心愉有一次祝的是游好行个们我力地为旅期导程体行时友服给小好感有满谢让去'
b1 = list(ocr)
print(b1)
for i in range(len(b)):
dict[b[i]] = b1[i]
print(dict)
dict1 = {}
for i in range(len(name1)):
dict1[name1[i]] = b1[i]
print(dict1)
内容解码测试
#-*-coding:utf-8 -*-
import re
from fontTools.ttLib import TTFont
font = TTFont('MFWCOMMENTSV1.woff')
name = font.getGlyphOrder()[13:]
name1 = []
for i in name:
name1.append(i.lower())
print(name1)
b = []
for i in name:
ls = font['hmtx'][i][1]
b.append(ls)
ocr = u'开好值下选让客每次持下最谢续待供可选谢方非推师荐务有机上人真体理你一品行服评值务开行品风就还加合机亲排加一得来感选还在一朋持客傅玩评是路人导期很工再多非我大次活力还是机个说友美价间我客很给傅特为活旅务理与傅感出作感给出一美续风店祝提祝谢不店以行谢验还认上我也工小酒价上来认服出去作再哦安团感理愉供不朋讲没得我是合生意团位价美别团荐快就美去了方谢没司就工评解景支作非一每风非美没到行对就常期常还谢地您客酒人提得非能继时谢路可快这了好服续的旅路对验感行与个景会您意提定生行和谢供会定常您师感您快次程多的旅一品待亲能很力满景可希努好这位来一心您一推肯讲常真人很不友程肯游很这评师支会别和定谢景开次好好让下能以希非游人游也是一体更以继位推常哦亲常努次们最望每谢谢愉都也间是产你次更荐有满说感解到肯可希值服生与游错有认点可产大择好方景次一司就可景导都朋路你说最店间一望酒谢真次哦路小旅心点人们好的合别的时谢产您意旅活解不我到再游客排司持是不谢错验望是排是就待次您行多错讲点服评次美和在了努更特玩支安客特加您安继次都感路的评大您在还择地有对很不为玩择心愉有一次祝的是游好行个们我力地为旅期导程体行时友服给小好感有满谢让去'
b1 = list(ocr)
dict = {}
for i in range(len(name1)):
dict[name1[i]] = b1[i]
print(dict)
text = '偶然ꕣ遇见斑马'
text = text.replace('&#x', '0x')
print(text.replace('0x31ba', '的'))
for i in dict:
if i in text:
text = text.replace(i, dict[i])
print(re.sub(';', '', text))
print(dict['0xe571'])

解码成功
二源码
#-*-coding:utf-8 -*-
from urllib import request
import json
from fake_useragent import UserAgent
import urllib.parse
import re
from fontTools.ttLib import TTFont
ocr = u'开好值下选让客每次持下最谢续待供可选谢方非推师荐务有机上人真体理你一品行服评值务开行品风就还加合机亲排加一得来感选还在一朋持客傅玩评是路人导期很工再多非我大次活力还是机个说友美价间我客很给傅特为活旅务理与傅感出作感给出一美续风店祝提祝谢不店以行谢验还认上我也工小酒价上来认服出去作再哦安团感理愉供不朋讲没得我是合生意团位价美别团荐快就美去了方谢没司就工评解景支作非一每风非美没到行对就常期常还谢地您客酒人提得非能继时谢路可快这了好服续的旅路对验感行与个景会您意提定生行和谢供会定常您师感您快次程多的旅一品待亲能很力满景可希努好这位来一心您一推肯讲常真人很不友程肯游很这评师支会别和定谢景开次好好让下能以希非游人游也是一体更以继位推常哦亲常努次们最望每谢谢愉都也间是产你次更荐有满说感解到肯可希值服生与游错有认点可产大择好方景次一司就可景导都朋路你说最店间一望酒谢真次哦路小旅心点人们好的合别的时谢产您意旅活解不我到再游客排司持是不谢错验望是排是就待次您行多错讲点服评次美和在了努更特玩支安客特加您安继次都感路的评大您在还择地有对很不为玩择心愉有一次祝的是游好行个们我力地为旅期导程体行时友服给小好感有满谢让去'
def getdict(path, ocr):
font = TTFont(path)
name = font.getGlyphOrder()[13:]
name1 = []
for i in name:
name1.append(i.lower())
print(name1)
b = []
for i in name:
ls = font['hmtx'][i][1]
b.append(ls)
b1 = list(ocr)
dict = {}
for i in range(len(name1)):
dict[name1[i]] = b1[i]
return dict
print(getdict('MFWCOMMENTSV1.woff', ocr))
headers = {
'Host': 'm.mafengwo.cn',
'User-Agent': UserAgent().random,
'Cookie': '__omc_chl=; __omc_r=; __mfwc=direct; __mfwa=1582281978419.51499.2.1582281978419.1582351514446; __mfwlv=1582351514; __mfwvn=2; __mfwlt=1582351543; mfw_uuid=5e4fb4fa-0fe4-6944-ca84-df50aeabab40; oad_n=a%3A3%3A%7Bs%3A3%3A%22oid%22%3Bi%3A1029%3Bs%3A2%3A%22dm%22%3Bs%3A18%3A%22tongji.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%3A19%3A%222020-02-21+18%3A46%3A18%22%3B%7D; uva=s%3A78%3A%22a%3A3%3A%7Bs%3A2%3A%22lt%22%3Bi%3A1582281978%3Bs%3A10%3A%22last_refer%22%3Bs%3A6%3A%22direct%22%3Bs%3A5%3A%22rhost%22%3Bs%3A0%3A%22%22%3B%7D%22%3B; __mfwurd=a%3A3%3A%7Bs%3A6%3A%22f_time%22%3Bi%3A1582281978%3Bs%3A9%3A%22f_rdomain%22%3Bs%3A0%3A%22%22%3Bs%3A6%3A%22f_host%22%3Bs%3A1%3A%22w%22%3B%7D; __mfwuuid=5e4fb4fa-0fe4-6944-ca84-df50aeabab40; Hm_lvt_8288b2ed37e5bc9b4c9f7008798d2de0=1582281980; PHPSESSID=ipcak5d2nv0bv4iieg4aavp631; Hm_lpvt_8288b2ed37e5bc9b4c9f7008798d2de0=1582351544; __mfwb=ceabeea772de.2.direct'
}
url0 = 'https://m.mafengwo.cn/sales/c/comment/api/list?'
parse = {"spu_id": "", "sales_id": "", "busi_type": "customize", "custom_uid": "", "mdd_id": "10183", "tag_id": "",
"parsed_tag_name": "", "has_img": "", "faq": "", "star": "", "start_date": "", "page_no": "2"}
data = urllib.parse.urlencode(parse)
url = ''.join([url0, data])
print(url)
req = request.Request(url, headers=headers)
html = request.urlopen(req)
jst = json.loads(html.read())
data = jst.get('data')
list1 = data.get('list')
dict = getdict('MFWCOMMENTSV1.woff', ocr)
for i in list1:
text = i.get('content').replace('&#x', '0x')
for j in dict:
if j in text:
text = text.replace(j, dict[j])
print(re.sub(';', '', text))
 以上内容只用于学习
以上内容只用于学习