python爬虫task3
1,安装selenium并学习
1.1,安装selenium和ChromeDriver
具体查看链接关于Chromedriver如何配置环境变量问题解决!!!!
注:如果按教程配置完成后,一直提示版本错误,或未安装可以重启电脑。(巨坑)
1.1,一般操作:
from selenium import webdriver # 启动浏览器需要用到
from selenium.webdriver.common.keys import Keys # 提供键盘按键支持(最后一个K要大写)
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\\chromedriver.exe")
driver.get("http://www.python.org") # 这个时候chromedriver会打开一个Chrome浏览器窗口,显示的是网址所对应的页面
element = driver.find_element_by_name("q")
element.send_keys("some text") # 往一个可以输入对象中输入“some text”
element.send_keys(Keys.RETURN) # 模拟键盘回车
#一般来说,这种方式输入后会一直存在,而要清空某个文本框中的文字,就需要:
element.clear() # 清空element对象中的文字
driver.close() # 关闭浏览器一个Tab
# or
driver.quit() # 关闭浏览器窗口1.2,实战:模拟登陆163邮箱
from time import sleep
from selenium import webdriver
'''
email是邮箱信息;
password是密码信息
'''
def login(email, password):
URL = "http://mail.163.com/"
browser = webdriver.Chrome()
browser.get(URL)
sleep(5)
browser.switch_to.frame(0)
input_email = browser.find_element_by_name("email") #获取填邮箱的input
input_email.send_keys(email) #填入邮箱信息
input_name = browser.find_element_by_name("password") #获取密码的input
input_name.send_keys(password) #填入密码信息
button_login = browser.find_element_by_id("dologin") #获取登录按钮
button_login.click() #点击登录按钮
if __name__ == '__main__':
email = input("请输入你的邮箱账号:(可省略后缀)")
password = input("请输入你的密码:")
login(email, password)2,IP代理
2.1,什么是IP
互联网协议地址,缩写为IP地址,是分配给用户上网使用的网际协议的设备的数字标签。
2.2 为什么会出现IP被封
网站为了防止被爬取,会有反爬机制,对于同一个IP地址的大量同类型的访问,会封锁IP,过一段时间后,才能继续访问
2.3 如何应对IP被封的问题
常用3种方法:
1,修改请求头,模拟浏览器去访问
2,采用代理IP并轮换
3,设置访问时间间隔
2.4,获取代理IP地址
from bs4 import BeautifulSoup
import requests
import time
def get_html(url):
# 申请请求头
headers = {'user-agent': 'chrome/74.0.3729.157'}
# get()请求
r = requests.get(url, headers=headers)
# 防止乱码
r.encoding = 'utf-8'
# 状态符判断
if r.status_code == 200:
return r.text
return None
# 获取ip地址
def get_ip(text):
proxy_ip_list = []
soup = BeautifulSoup(text, 'html.parser')
proxy_ips = soup.find(id='ip_list').find_all('tr')
for proxy_ip in proxy_ips:
if len(proxy_ip.select('td')) >= 8:
ip = proxy_ip.select('td')[1].text
port = proxy_ip.select('td')[2].text
protocol = proxy_ip.select('td')[5].text
if protocol in ('HTTP', 'HTTPS', 'http', 'https'):
proxy_ip_list.append("{}{}{}{}{}".format(protocol,"://",ip,":",port))
return proxy_ip_list
# 检查IP是否有效
def check_ip(ip):
url = 'http://www.baidu.com'
headers = {'user-agent': 'chrome/74.0.3729.157'}
ips = {}
if ip.startswith(('HTTPS', 'https')):# 用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
ips['https']=ip
else:
ips['http'] = ip
try:
r = requests.get(url, headers=headers, proxies=ips, timeout=3) # 超时处理
r.raise_for_status()
r.encoding = r.apparent_encoding
if r.status_code == 200:
print('有效代理IP:' + ip)
return True
else:
print('无效代理IP:' + ip)
return False
except:
print('无效代理IP:' + ip)
return False
if __name__ == "__main__":
url = 'https://www.xicidaili.com/'
text = get_html(url)
proxy_ip_list = get_ip(text)
print(proxy_ip_list)
ip_use_list = []
for ip in proxy_ip_list:
result = check_ip(ip)
if (result):
ip_use_list.append(ip)
print("有效代理IP")
print(ip_use_list)3,session和cookie
3.1,动态网页和静态网页
静态网页
静态网页就是我们上一篇写的那种 html 页面,后缀为 .html 的这种文件,直接部署到或者是放到某个 web 容器上,就可以在浏览器通过链接直接访问到了,常用的 web 容器有 Nginx 、 Apache 、 Tomcat 、Weblogic 、 Jboss 、 Resin 等等,很多很多。举个例子:https://desmonday.github.io/,就是静态网页的代表,这种网页的内容是通过纯粹的 HTML 代码来书写,包括一些资源文件:图片、视频等内容的引入都是使用 HTML 标签来完成的。它的好处当然是加载速度快,编写简单,访问的时候对 web 容器基本上不会产生什么压力。但是缺点也很明显,可维护性比较差,不能根据参数动态的显示内容等等。有需求就会有发展么,这时动态网页就应运而生了
动态网页
大家常用的某宝、某东、拼夕夕等网站都是由动态网页组成的。
动态网页可以解析 URL 中的参数,或者是关联数据库中的数据,显示不同的网页内容。现在各位同学访问的网站大多数都是动态网站,它们不再简简单单是由 HTML 堆砌而成,可能是由 JSP 、 PHP 等语言编写的,当然,现在很多由前端框架编写而成的网页小编这里也归属为动态网页。
说到动态网页,各位同学可能使用频率最高的一个功能是登录,像各种电商类网站,肯定是登录了以后才能下单买东西。那么,问题来了,后面的服务端是如何知道当前这个人已经登录了呢?
http1.0
HTTP1.0的特点是无状态无链接的
无状态就是指 HTTP 协议对于请求的发送处理是没有记忆功能的,也就是说每次 HTTP 请求到达服务端,服务端都不知道当前的客户端(浏览器)到底是一个什么状态。客户端向服务端发送请求后,服务端处理这个请求,然后将内容响应回客户端,完成一次交互,这个过程是完全相互独立的,服务端不会记录前后的状态变化,也就是缺少状态记录。这就产生了上面的问题,服务端如何知道当前在浏览器面前操作的这个人是谁?其实,在用户做登录操作的时候,服务端会下发一个类似于 token 凭证的东西返回至客户端(浏览器),有了这个凭证,才能保持登录状态。那么这个凭证是什么?
那么如何查看自己浏览器的http代理呢?
1,随便进入一个网页
2,按F12
3,按Network
4,name栏随便点一个,看headers的via
例如:
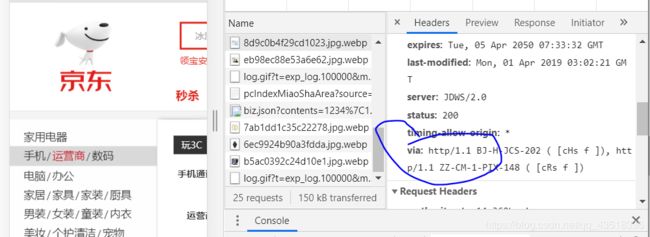
3.2,session和cookies
Session 是会话的意思,会话是产生在服务端的,用来保存当前用户的会话信息,而 Cookies 是保存在客户端(浏览器),有了 Cookie 以后,客户端(浏览器)再次访问服务端的时候,会将这个 Cookie 带上,这时,服务端可以通过 Cookie 来识别本次请求到底是谁在访问。
可以简单理解为 Cookies 中保存了登录凭证,我们只要持有这个凭证,就可以在服务端保持一个登录状态。
在爬虫中,有时候遇到需要登录才能访问的网页,只需要在登录后获取了 Cookies ,在下次访问的时候将登录后获取到的 Cookies 放在请求头中,这时,服务端就会认为我们的爬虫是一个正常登录用户。
4,模拟登录丁香园,并抓取论坛页面所有的人员基本信息与回复帖子内容
import time
import requests
from lxml import etree
from selenium import webdriver
def login():
url = 'https://auth.dxy.cn/accounts/login'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(3)
browser.maximize_window()
time.sleep(3)
compter_em = browser.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/a[2]')
compter_em.click()
username = browser.find_element_by_name('username')
username.send_keys('******')
password = browser.find_element_by_name('password')
password.send_keys('******')
login_em = browser.find_element_by_xpath('//*[@id = "user"]/div[1]/div[3]/button')
login_em.click()
time.sleep(10)
cookie = browser.get_cookies()
cookie_dict = {
i['name']:i['value'] for i in cookie
}
return cookie_dict
def get_content():
url = 'http://www.dxy.cn/bbs/thread/626626#626626'
cookies = login()
headers = {'user-agent':'Chrome/81.0.4044.122'}
response = requests.get(url=url,headers=headers,cookies=cookies)
html = etree.HTML(response.text)
contents = html.xpath('//td[@class="postbody"]')
users = html.xpath('//div[@class="auth"]')
for i in range(0,len(contents)):
content = contents[i].xpath('string(.)').strip()
user = users[i].xpath('string(.)').strip()
print(user+':'+content)
print('~'*100)
if __name__ == "__main__":
get_content()