【数据分析案例】英雄联盟美服10000条排位数据分析
英雄联盟美服10000条排位数据分析
英雄联盟是2009年美国拳头游戏开发一款红蓝双方互相对抗的MOBA游戏,每队有5名队员,通过击杀敌方小兵、推塔、击杀敌方英雄,以最终摧毁敌方主堡作为胜利的游戏。
一、数据来源
本次的数据来源是kaggle。
链接地址:https://www.kaggle.com/bobbyscience/league-of-legends-diamond-ranked-games-10-min
从数据来源者描述中可以得知,本次数据是通过拳头数据API获得的。数据包括钻一到大师分段的SOLO Q排位每场的前10分钟数据。总共有接近10000条比赛数据。这些数据值得分析的原因也在于召唤师段位较高,数据较为稳定。低段位比赛由于玩家水平较低,数据波动会大很多。
这里需要介绍一下英雄联盟的排位中队友和对手的匹配机制:
匹配系统的目的如下,优先级从高到低:
1.保护新手不被有经验的玩家虐;让高手局中没有新手。
2.创造竞技和公平的游戏对局,使玩家的游戏乐趣最大化。
3.无需等待太久就能找到对手进入游戏。
4. 匹配系统尽其所能的匹配水平接近的玩家,玩家的水平是来自他们在此之前赢了谁以及他们对手的水平。
数据包括:
最终比赛结果,一血击杀方,蓝色方击杀数,蓝色方死亡数,蓝色方助攻数,蓝色方控制守卫数量,蓝色方排眼数,蓝色方精英怪击杀数,蓝色方小兵击杀数,蓝色方推塔数,蓝色方龙击杀数,蓝色方获得金币数,蓝色方获得经验,蓝红双方金币差,蓝红双方经验差,以及红色方相对应的一些数据。
二、探索的问题
从上面的数据可以看出英雄联盟中有很多的游戏元素,这些游戏元素都在影响比赛进程,最终决定比赛结果。比如一血的击杀可以给队伍带来更多的金币,影响兵线。比如更多的助攻代表着更加团队的打法。如果一场比赛中击杀很少,那比赛可能会陷入互相发育的无聊阶段,此时小兵的击杀数会和防御塔摧毁数量会影响金币进而影响装备。等等。。。
从这些数据中我要探索的问题是:
-
前10分钟的平均数据是什么样的,从平均数据中推测钻一到大师分段前10分钟比赛时会出现的情况。
-
随着比赛场次的增加以及玩家对游戏版本理解的深入,游戏数据平均值是否发生波动?这些波动反应了召唤师们对游戏理解的哪些改变?
以及最终的目标:
哪些数据会影响比赛结果,是正向相关还是负向相关?是否能从前10分钟比赛数据预测最终的比赛结果?预测的准确率是多少?
三、数据探索
在进行数据探索之前,首先要考虑这些数据的均值等是否能代表全部数据的真实情况。
举个简单的例子,这10000条数据是否都是在同一游戏版本中进行的。如果发生过版本变动,那么其中一个版本的数据并不能代表另一个版本的真实情况。同样,如果数据不是发生在同一版本中,预测比赛结果也就无从谈起。
在原始数据中包含了每场比赛的唯一id(gameId),观察比赛id可以得知这些id在原始数据中是是乱序,但是id前三位数之间的差距不大。例如连续三行数据的id可能是:
450xxxxxxx
447xxxxxxx
449xxxxxxx
由此可以推测出两种可能性:
- 原始表中的数据顺序并不是真实比赛发生的时间顺序,比赛id前三位排序后可能是真实的比赛时间顺序。
- 原始表的顺序就是真实比赛发生的时间顺序,游戏id并没有太大的参考意义。
假设以比赛id是真实的时间顺序
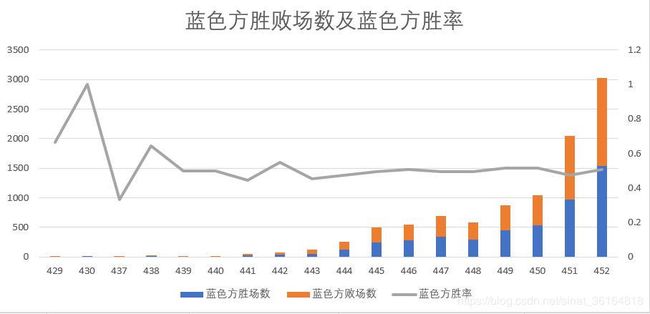
从下方蓝色方胜败场数图中可以看出比赛id为42XXXX,43XXXX,44XXXXXX,45XXXX 之间的比赛总数量相差很大,不应该为不同版本之间的差异。
并且10000场比赛对于英雄联盟美服来讲也并不是特别大量的比赛场次。
因此暂推测比赛数据发生在同一游戏版本中,并且原始数据表的顺序即为真是比赛时间发生顺序。 ▼
那么要探索的问题:
一、前10分钟的平均数据是什么样的,从平均数据中推测钻一到大师分段前10分钟比赛时会出现的情况。
对这些数据进行汇总:

从上表中可以得知:
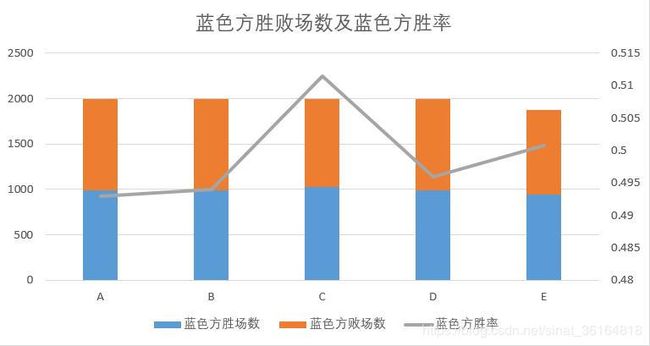
- 蓝色方胜率49.9%。从游戏地图设置上,红蓝双方相对公平性。同样由于游戏平衡性较好,因此从平均值来看红蓝双方的数据相差不大,因此本表中仅体现蓝色方数据。
- 10分钟时单方击杀数为6.2个,助攻数为6.6个,平均每击杀助攻数1.1。说明游戏前期(对线期)击杀主要来自于单杀或小规模团战或2人协作击杀对面单人,而非大规模团战。
- 蓝红双方经济差平均为14.4。这里要说明,当蓝色方金币数比红色方高时,该数值为正值;当红色方金币数比蓝色方高时,该数值为负数。该数据平均值代表了游戏对蓝红双方是否公平,14.4平均经济差值在游戏中已足够小,说明游戏总体公平。
同样,对所有经济差取绝对值后再平均,代表了游戏中10分钟时双方经济差的平均水平。
计算后得到经济差绝对值平均数:1931.59。说明在10分钟时领先的一方相当于每人领先对面敌方一个小件装备,如果考虑经济大部分集中在双C位,那么相当于双C每人领先对面半件大装备。 - 平均控制守卫数是22.2个,破坏对方控制守卫数是2.8个。前期真眼和扫描眼比较少,破坏对方控制守卫数比较少可以理解。
- 平均等级为6.9级,考虑到C位经验领先与辅助等位置,因此10分钟时基本是全员刚有大招的时候。由此推测10分钟前在平稳的对线期,10分钟后团长将变多。
- 全队小兵击杀数(补刀)平均值数是216个,分均补刀21.6个。这在英雄联盟全部玩家中算是比较高的水平,不愧是钻1到大师的水平。
二、随着服务器中比赛场次的增加以及玩家对游戏版本理解的深入,游戏数据是否发生波动?这些波动反应了召唤师们对游戏理解的哪些改变?
原始数据本身是没有时间属性的。为了探寻比赛数据随比赛发生时间(非比赛内时间)的变化,我这里将全部数据按原始数据顺序分为5份,分别标记为“A、B、C、D、E”5个阶段。对数据进行探索。
再次说明,10000场数据量并不是很大,很可能这些数据仅产生在几天内。短时间的数据波动可能并不能真实代表玩家玩法的变化。以下内容为探索。
- 虽然这10000场蓝色方总胜率是49.9%,很接近50%,但将数据分段可以看到大多数时间蓝色方胜率是不足50%的。(虽然差距并不大)▼
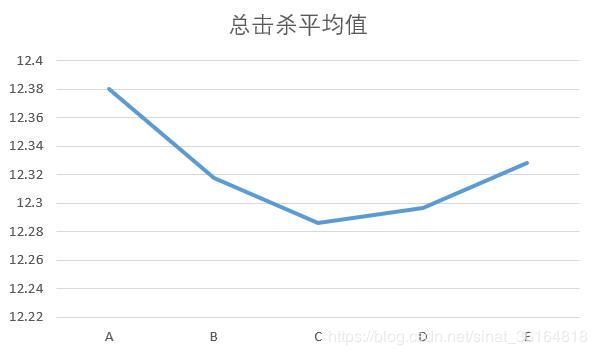
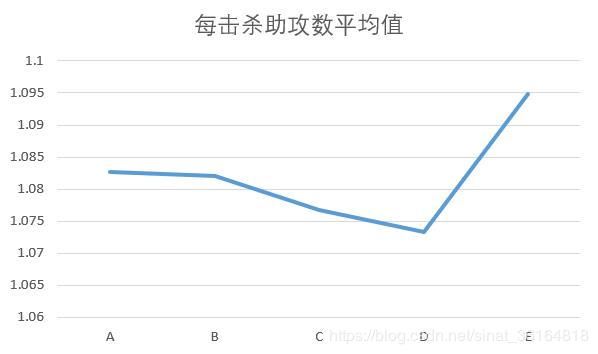
- 总获得金币,击杀,助攻数,每击杀助攻数折线图中可以看出,ABCD四个阶段蓝红双方的对抗是相对减弱的。尤其从每击杀助攻数可以看出,D阶段发生了更少的团战,单杀的比率增加。总金币减少,游戏前期获得装备的也减慢。但在E阶段,召唤师们又开始热衷于击杀和团战。▼


- 推塔情况总体变化不大,每场平均推塔0.1个左右。说明在10分钟时双方基本都不会推掉对方防御塔。防御塔的经济影响可忽略。
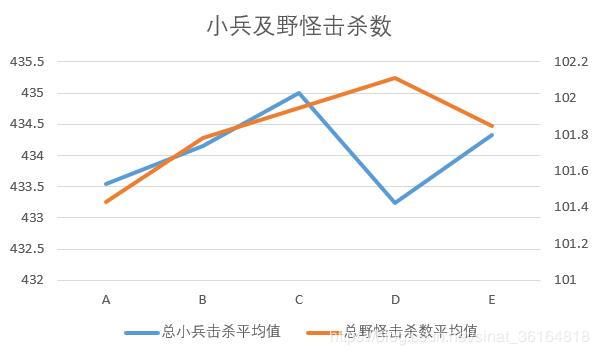
当线上击杀变少,补兵变少的时候。我们的打野在干什么呢?从小兵及野怪击杀图和龙击杀图中可以看出,我们的打野一门心思的在地图上刷野和控龙。也许他们觉得去线上帮助队友拿到优势的策略并不可靠。打野不来帮助线上击杀对面,所以ABCD阶段总击杀和助攻都减小了的数据也就更为合理。▼


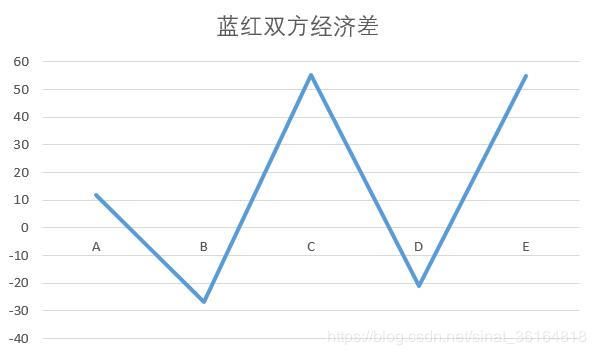
- 影响比赛结果的经济差
从红蓝双方的经济差可以发现,经济差的变化趋势与胜率的变化趋势相似。可以推测,双方经济差是影响比赛结果的关键因素之一。这对下一步预测比赛结果也有重要意义。
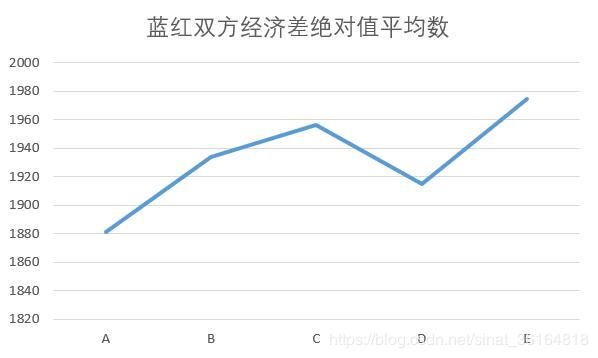
从蓝红双方经济差绝对值趋势可以看出,“A、B、C、D、E”5个阶段总体双方经济差是拉大的。也就是说在前10分种内随着对版本理解的深入,占得优势的一方会将优势扩大更多。▼
- 暂时不能理解的趋势
从总经验趋势图中可以看出,BCD三个阶段双方总经验和是保持在高位的。但从上面数据也看到,击杀、助攻、每击杀助攻数、小兵击杀数在这几个阶段都是下降的。那这些经验从何而来呢?是因为野怪击杀数和龙击杀数增多么?我保持怀疑。▼

三、哪些数据会影响比赛结果,是正向相关还是负向相关?是否能从前10分钟比赛数据预测最终的比赛结果?预测的准确率是多少?
我们最想知道的还是是否能从前10分钟数据中预测比赛结果。使用机器学习的方法对数据进行分析。在本文中只接单介绍过程。
- 数据清洗及变量转换
查看数据类型和缺失情况。转换部分数据类型及范围以方便机器学习。 - 特征工程
原始数据中记录了很多双方数据,但对胜负影响大的因素并不是蓝色方击杀了几次,红色方击杀了几次,而应该是双方数据的差值。比如哪一方拿到了一血,击杀数差值,助攻数差值,平均经验差值,平均等级差值,小兵击杀数差值等等。
在这一阶段通过组合方式获得更多特征。
例如:蓝色方拿到一血时,蓝色方更容易获胜。蓝色方击杀龙后更容易获胜。(注:1是蓝色方胜或击杀龙或蓝色方拿到一血,0是红色方胜或拿小龙或红色方拿到一血)▼
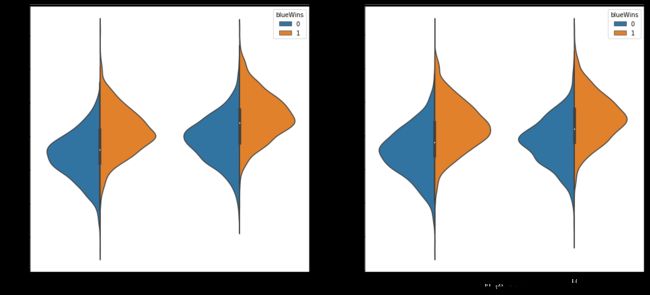
并通过相关系数矩阵简单探索数据相关性。▼

-
输入模型前的一些处理
包括数据正则化,去掉部分无用特征,分割训练数据和测试数据等等。我这里将20%数据分割为测试数据。 -
模型融合
采用Stacking框架融合。第一层使用RandomForest、AdaBoost、ExtraTrees、DecisionTree、KNN、SVM ,一共6个模型。
第二层使用XGBoost对数据进行最终预测。采用准确率accuracy_score方法对预测结果进行评分。
最终评分0.729分。后续有继续优化空间,例如根据特征重要性筛选特征,组合部分特征,参数优化等。▼
