Experiment Two
Data processing:
采用Seeta Face的人脸检测和对齐方法重新获取样本, 并且缩放到2272773尺度,重新进行训练
AdienceBenchmark.png
训练测试样本示例
Val_Accuracy.png
Train_Loss.png

Test_Accuracy.png
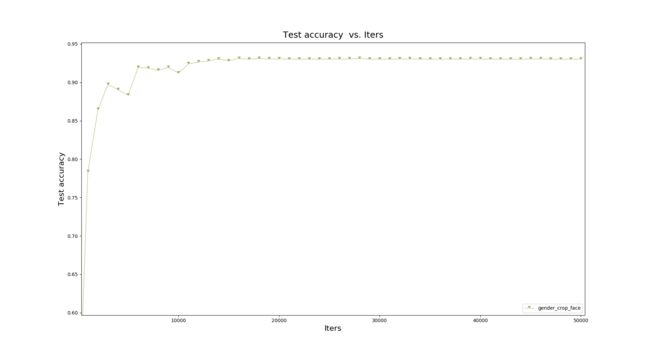
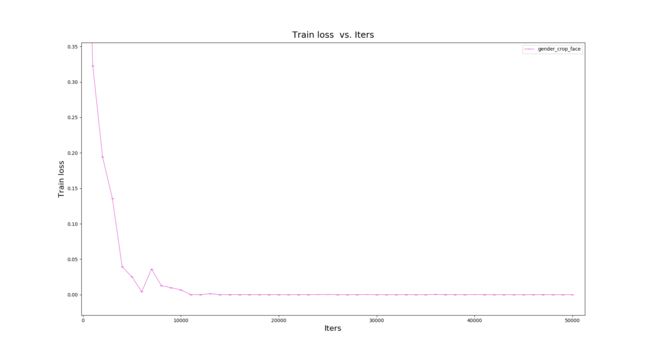
验证集准确率为92%,相比与加入背景信息样本稍有降低,下降2%.
测试集测试准确率为85.6%相比于加入背景信息样本稍有降低,下降3%.
[问题分析]
- Adience数据库中同一个人样本过多(重复样本), 只是相应的姿态, 背景光照信息进行变化,并且训练时候进行mirror操作,更加增加了重复率.
增加样本多样性, 采用不同现实环境中的性别库进行训练,
- 人脸尺寸往往不会非常大,如果进行尺度变化比较大的话,对原图像的清晰度非常有影响,进而对最终的识别效果产生影响.
选择更精简的网络结构进行训练(4848 或 6464)
- 人脸性别往往与一些脸部特征息息相关,比如胡子等特征就可以有很大的可能性去判断其性别.
加入其他属性进行多任务辅助学习,让性别识别更加准确.
实验三
Step1: 数据库选择
收集公开库性别数据
CelebA
LFWA
AFLW
私有数据集 Dalian
利用Face++API 进行人脸检测和属性预测
Step2:数据处理
形成头部区域并带有一些背景

Demo.png

Left_demo.png

Right_demo.png