一、搜索引擎篇-揭开es神秘的面纱
一、es是什么?
elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库lucene。
二、lucene是什么?
最受欢迎的java开源全文搜索引擎开发工具包。 提供了完整的查询引擎和索引引擎, 部分文本分词引擎。
三、es中shard是什么?
一个index可能存储大量的数据,以至于一台集齐放不下,即使能承载,用单机查询全量数据,也相当耗时。为了解决这个问题,es将index中的数据分成多份,每一份叫一个shard。
四、es中replica是什么?
replica即为shard的备份, 每个shard可以有多个replica, 其中一个是primary shard, 剩余的是replica shard。replica除可以起到容错的作用外, 还可以提高查询并发度。
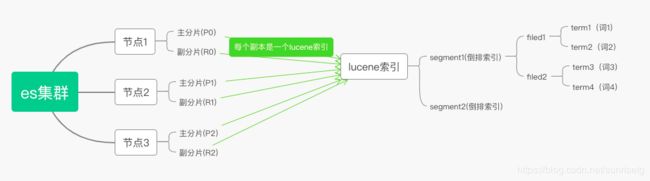
五、lucene在es中的作用?
es的每个副本实际上是一个lucene index实例。
六、es集群结构:

索引的六个分片被均匀分配到集群的三个节点中
1、名词解释:
node代表机器节点
P代表primary shard 主分片
R代表replica shard 副分片
2、分片分配规则:
2.1、让节点间均匀存储。
2.2、保证不把主分片和副分片分配到同一个节点,避免单个节点故障引起数据丢失。
3、集群容灾:
分布式系统难免出现故障,当节点异常时,es会自动处理异常节点。
3.1、主节点异常:
集群会重新选举主节点
3.2、主分片异常:
将副分片提升为主分片
七、为什么需要搜索引擎?
数据库适合结构化数据的精确查询,而不适合半结构化、 非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
结构化数据:用表、字段表示的数据
半结构化数据: xml、html
非结构化数据: 文本、 文档、 图片、 音频、 视频等
八、搜索引擎如何做到?
1、为什么称为倒排索引?
原名Inverted index, 失败地翻译成了倒排索引, 正确翻译为: 反向索引

2、索引可以合并在一起吗?
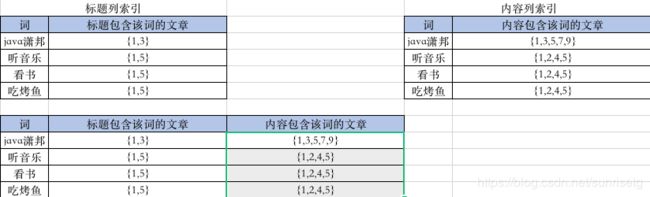
3、反向索引的记录数会不会很大?
《牛津词典》 收词41万
《现代汉语规范词典》 收录字数13000多个, 收录词数72000多个
结论: 量不会很大, 100万以内; 通过这个索引找文章会很快。
4、如何建立这样一个索引?

5、java开源中文分词器有哪些?
常用中文分词器有: IKAnalyzer mmseg4j
6、分词时能不能统计出词的出现次数、 位置?

九、搜索
1、如何做才能快速查询到与“火锅” 有关的新闻?
使用分词器对数据进行分词, 建立反向索引
2、有了反向索引了, 如何进行搜索?
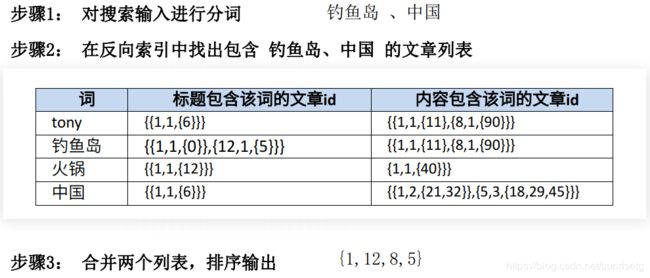
3、合并后列表该如何排序?
我们希望最相关的排在最前面
4、相关性如何度量?
人可以通过读内容判定相关性,机器不懂人言,得需要一套能评估相关性的模型
5、如何根据次数建立一个相关性评估模型?
规则1:统计出现次数,根据次数从高到底排序
规则2:加入权重,标题权重10,内容权重1,计算权重得分,从高到底排序