爬取时光网电影信息
要求:
通过时光网爬取每年评分在7-10分之间的电影信息(电影名/链接/评分)
第一步 寻找URL
时光网的分类查询页面:http://movie.mtime.com/movie/search/section/#
时光网的页面是通过AJAX异步加载的,在浏览器上关闭JAVASCRPIT 会发现网页变成如下的样子(图1),如果直接用request对上面的URL进行请求,只能得到这个页面的HTML代码,但是这个页面是没有分类查询的任何功能和信息的。
图1

要找到分类查询真正请求的URL 需要去审查元素中的NETWORK中寻找。
在网页内筛选后(我这里按2015年 评分7-10分进行筛选)。在NETWORK中刷新后得到响应文件,可以看到下面红圈中(图2)都是筛选结果的电影海报图片。
图2

在这些JPG上面有一个叫search.msc?..的文件,点进去粗略地看了下response,能看到电影名称,感觉应该就是这个文件了。再进一步查看这个文件请求的URL(图3),很长一段,直接在浏览器中访问这个链接(图4) 又获得一大段HTML代码。可以看到这段代码里有我们需要的所有信息了(电影名称/链接/评分/年代),所以这才是我们需要用request进行请求的URL
图3
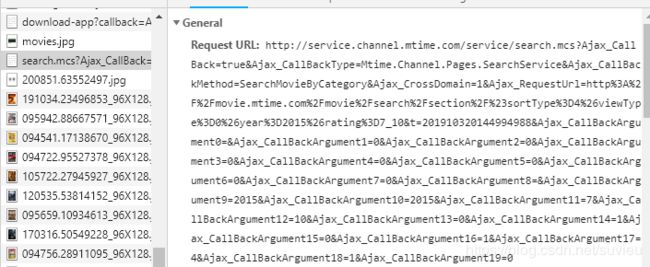
图4

第二步 解析页面
接下来就是对这段代码进行解析了;因为这段HTML 代码拿回来其实是以字典形式的文本呈现的,所以我还是用正则表达式去抓我们需要的信息。这里的正则表达式并不难,需要注意的是评分是分整数和小数的。把抓取到的内容都放在movie_info变量中,再把movie_info放到movie_list列表中
import re
name_pattern = re.compile(r'(\d)<[\s\S]*?class=total2>(.*?)<[\s\S]*?span class=\\"c_666\\">\((.*?)\)<')
movie_info=name_pattern.findall(response)
movie_list.extend(movie_info)
第三步 实现翻页
虽然URL很长,但大部分都是不变的,主要还是通过比较不同页的URL之间的区别,找到控制页码/年代/评分的参数,在后续写for循环的时候用变量替换。具体区别如下

黄色标注是固定不变的,蓝色部分是相关参数,year/rating/pageindex/t分别代表了年代/评分/页数/请求的时间,后面灰色部分看augument就知道也是参数,一共20个参数,其中也有代表年代/评分/页数的参数(图中标蓝的部分),在翻页时需要同步更改,具体每个AUGMENT控制了哪个变量在我不断的尝试下终于弄清了大部分,具体如下,
Ajax_CallBackArgument2: 国家/地区,如美国275,中国138
Ajax_CallBackArgument3: 类型
Ajax_CallBackArgument4:分级
Ajax_CallBackArgument5:对白语言
Ajax_CallBackArgument6:色彩
Ajax_CallBackArgument7:声音
Ajax_CallBackArgument9:起始年份
Ajax_CallBackArgument10:截止年份
Ajax_CallBackArgument11:评分下限
Ajax_CallBackArgument12:评分上限
Ajax_CallBackArgument14:中文名首字母
Ajax_CallBackArgument16: 英文名首字母
Ajax_CallBackArgument17:排序方法·
Ajax_CallBackArgument18:页数
我觉得很很奇怪,为什么同一个变量要在两个地方进行控制呢?后来我发现即使URL少了蓝色的部分(year%3D2015%26rating%3D7_10&t=201910320473241565),似乎也不影响请求,不过我后面的代码还是先留着了。
找到了翻页的规律,我们只要在URL对应的位置换成变量就行了,
还有个问题是我怎么知道这一页是最后一页呢?查看最后一页的URL,发现最后一页有一行特有的HTML代码下一页,所以只要加一个if语句,如果正则表达式能抓到这段,就说明时最后一页,那么就终止循环。
next_pattern = re.compile(r'下一页')
next = next_pattern.search(response)
if next != None:
break
第四步 保存到excel
等全部循环完了以后,把movie_list导入进pandas中,
movie_df=pd.DataFrame(movie_list,columns=['电影名称','链接','得分—整数','得分—小数','年份'])
在pandas中对数据进行整合,因为一开始抓取的整数和小数其实是文本格式,所以先要转化成数字格式
movie_df[['得分—整数','得分—小数']] = movie_df[['得分—整数','得分—小数']].apply(pd.to_numeric)
把整数和小数相加,得出总评分,
movie_df['评分']=movie_df['得分—整数']+movie_df['得分—小数']
final_df = movie_df[['年份','电影名称','链接','评分']]
最后导出为csv文件,mode a为不覆盖原来的内容导入
final_df.to_csv('movie.csv',encoding='utf_8_sig',index=False,mode='a')
大功告成!
-------------------------------------------------------------------------------------------------------------
如何对接MYSQL数据库
首先在MYSQL里创建一个数据库,新建一个名为“MTIME”的表。

然后导入pymysql模块,对接MYSQL 数据库,插入数据即可,注意这里一定要写db.commit()才会真正实现数据导入
import pymysql
def Insert(VALUE):
db = pymysql.connect(host="localhost", user="Simon",password= "******",port=3306, db='movie')
cursor = db.cursor()
sql = "INSERT INTO MTIME(NAME,LINK,POINT,POINT2,YEAR) VALUES (%s,%s,%s,%s,%s)"
cursor.execute(sql,VALUE)
db.commit()
db.close()
附上完整代码:
我暂时没有大批量爬虫的需求,一年一年爬就可以,所以我用了input输入需要爬取的年份和分数区间,
import requests
import re
import pandas as pd
import time
from lxml import html
start=time.time()
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Mobile Safari/537.36'}
year = input("请输入想查询的年份")
low_point = input("请输入想查询的评分下限(只能输入整数)")
high_point = input("请输入想查询的评分上限(只能输入整数)")
movie_list=[]
url1='http://service.channel.mtime.com/service/search.mcs?Ajax_CallBack=true&Ajax_CallBackType=Mtime.Channel.Pages.SearchService&Ajax_CallBackMethod=SearchMovieByCategory&Ajax_CrossDomain=1&Ajax_RequestUrl=http%3A%2F%2Fmovie.mtime.com%2Fmovie%2Fsearch%2Fsection%2F%23year%3D'
url2 = year +'%26rating%3D'+low_point+'_'+high_point
url3 = '&t=201910311343539916&Ajax_CallBackArgument0=&Ajax_CallBackArgument1=0&Ajax_CallBackArgument2=0&Ajax_CallBackArgument3=0&Ajax_CallBackArgument4=0&Ajax_CallBackArgument5=0&Ajax_CallBackArgument6=0&Ajax_CallBackArgument7=0&Ajax_CallBackArgument8=&Ajax_CallBackArgument9='+year +'&Ajax_CallBackArgument10='+year+'&Ajax_CallBackArgument11='+low_point+'&Ajax_CallBackArgument12='+high_point+'&Ajax_CallBackArgument13=0&Ajax_CallBackArgument14=1&Ajax_CallBackArgument15=0&Ajax_CallBackArgument16=1&Ajax_CallBackArgument17=4&Ajax_CallBackArgument18={}&Ajax_CallBackArgument19=0'
url=url1+url2+url3
print(url)
n=0
while True:
n=n+1
print('正在爬去第{}页'.format(n))
print(time.strftime("%H:%M:%S", time.localtime(time.time())))
response = requests.get(url.format(n),headers=headers).text
name_pattern = re.compile(r'(\d)<[\s\S]*?class=total2>(.*?)<[\s\S]*?span class=\\"c_666\\">\((.*?)\)<')
movie_info=name_pattern.findall(response)
movie_list.extend(movie_info)
next_pattern = re.compile(r'下一页')
next = next_pattern.search(response)
if next != None:
break
time.sleep(4)
for item in movie_list:
Insert(item)
总结
爬虫本身,写正则表达式并不难,主要是前期找到正确的URL 分析URL找规律花了点时间。另外,爬取过程中遇到了时光网的反爬措施,让我输入验证码,不过似乎在我输入了验证码后还可以继续进行爬虫。
问题&待改进
Q1. 最后导入进CSV还不够完美,虽然不会覆盖原来的内容,但每次导入会把列名一起导入进去
Q2. 如何实现和MYSQL数据库的对接?
A:10-5解决