EAST源码解析(写在一篇里)
参考文章:
https://blog.csdn.net/qq_41576083/article/details/88077185
https://www.cnblogs.com/lillylin/p/9954981.html
https://zhuanlan.zhihu.com/p/71182747
源码地址:
https://github.com/argman/EAST
目录
一,icdar.py数据预处理部分
1.1 数据集格式
1.2 数据预处理
二,model.model()网络结构搭建,特征图生成
三,model.loss()损失函数
3.1 分类损失:
3.2 回归损失:
该方法利用多层卷积神经网络提取图像特征,再利用该特征分别进行两个任务,像素点的分类,以及对应像素点的框的回归。最后将两个任务结果结合起来,并用非极大值抑制NMS来得到最终检测结果。East的亮点在于:能检测任意角度的文字,速度快,在ICDAR2015数据集上效果佳。适用于日常的网络图片的文字检测。
EAST源码主要包含3个功能模块:
- icdar.py此部分主要是对数据进行预处理;
- model.model()函数,该函数在model.py中,主要是完成网络结构搭建,特征图的生成;
- model.loss()函数,该函数在model.py中,主要是计算损失。
- 其他代码说明:
文件名 文件功能/函数说明 data_util.py 训练数据generator类封装(与数据并行、多线程相关) eval.py 测试函数 model.py 整个网络结构搭建、损失函数实现 icdar.py 训练GroundTruth生成、数据处理、大部分工具函数实现 multigpu_train.py 训练函数(主要涉及与tf相关的训练框架) nets/ 包括resnet相关的网络结构搭建 lanms/和local_aware_nms.py 与NMS相关的python函数、CPP源函数及编译相关
下面只对关键的前3个代码进行解析,其他部分就不做详细解析了。
一,icdar.py数据预处理部分
1.1 数据集格式
icdar2015的数据集格式如下:
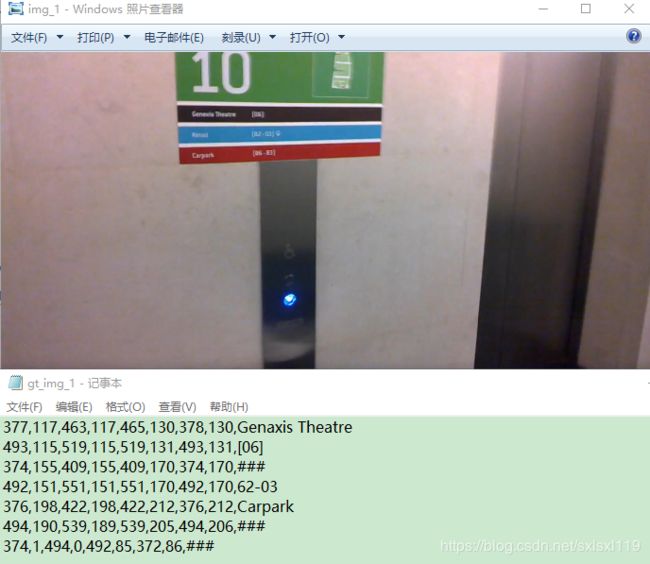
总共有1000张图,每张图对应1个txt,txt中每一行的前8个数字分别是文本框的左上x1,左上y1,右上x2,右上y2,右下x3,右下y3,左下x4,左下y4。最后一列有的是英文有的是数字,有的是###,不是###的表示文本框里面的内容,因为该数据集是英文的,所以基本上是英文和数字。是###的表示标记的文本比较模糊,难以辨认。
需要注意的一点是,网上有的代码是说图片和文本的名字是一样的,但是我下载的这个图片名是img_1,而文本名是gt_img_1.这个问题需要解决一下。要么将文本的名称改成和图片一样的,要么改代码。我是改了代码,在icdar.py的generator()函数中,将以下代码修改一下:
for i in index:
try:
im_fn = image_list[i] # 获取当前索引图像全路径
im = cv2.imread(im_fn) # 读取图像
# print im_fn
h, w, _ = im.shape # 获取图像宽、高、通道数
txt_fn = im_fn.replace(os.path.basename(im_fn).split('.')[1], 'txt') # 替换成图像对应的txt全路径
txt_fn = txt_fn.replace("\\", "//")
temp=txt_fn.split('//')[-1] # 2020.01.07
txt_fn=txt_fn.replace(temp, "gt_"+temp)1.2 数据预处理
GroundTruth生成
点的分类任务,实际上是一个图像分割的任务。训练的时候,文字区域所在部分表示1,非文字的背景部分表示0,这样就能得到分类任务的groundTruth。为了对边界像素点可以更好的分类,这个方法对原有的检测框做了一点收缩,如图中黄色虚线框收缩成绿色框,这样边界像素点可以分类得更准确。
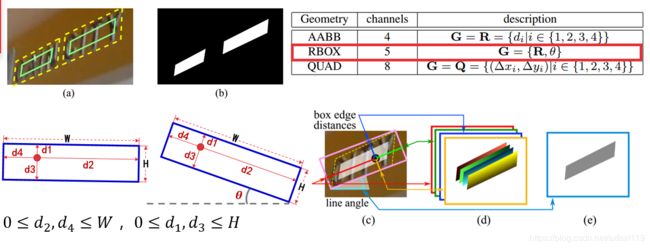
对于框的回归,首先需要确定的是如何来表示一个框。该方法提出了两种方式,
- 一种是用四边形的4个顶点,每个顶点有x和y两个坐标,故8个坐标来表示,称为QUAD。这种表示方式模型的学习难度比较大。
- 第二种表示方式RBOX。我们知道,对于任意一个固定点,如果确定该点到四条边的距离,那么就可以确定一个矩形框。如果再加上角度信息,那么这五个参数d1,d2,d3,d4,以及theta就能唯一确定一个带角度的矩形框。该方法正是采用这个方式得到框回归的GroundTruth。比如图中d图表示每个点的四个距离,e图表示对应的angle。
代码解析:
在icdar.py的generator()函数中进行数据预处理的相关操作。
- 先是读取图像,
im = cv2.imread(im_fn)- 再读取文本标记信息,
text_polys, text_tags = load_annoataion(txt_fn)- 检查文本多边形是否在相同方向上,并过滤一些无效的多边形
text_polys, text_tags = check_and_validate_polys(text_polys, text_tags, (h, w))- 随机缩放图像,扩充数据集
# 随机缩放图像,扩充数据集
rd_scale = np.random.choice(random_scale) #random_scale=np.array([0.5, 1, 2.0, 3.0]
im = cv2.resize(im, dsize=None, fx=rd_scale, fy=rd_scale)
text_polys *= rd_scale # 文本框也要跟着缩放- 下面是根据产生的随机数分别对数据进行处理
产生的随机数小于3./8时,生成背景图,作为负样本
if np.random.rand() < background_ratio: # 如果产生的随机数小于background_ratio=3./8,生成负样本?
# 从图像中随机裁剪一个区域,扩充数据集, 注意这里的crop_background=True
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=True)
if text_polys.shape[0] > 0: # 如果随机生成的背景框中包含文本框,则忽略
# cannot find background
continue
# 如果随机生成的背景框中不包含文本框,执行以下操作
# 填充并调整图像大小
new_h, new_w, _ = im.shape # 表示生成的不包含文本的背景框
max_h_w_i = np.max([new_h, new_w, input_size]) # 选择三者中最大的值
im_padded = np.zeros((max_h_w_i, max_h_w_i, 3), dtype=np.uint8) # 生成一个全0矩阵
im_padded[:new_h, :new_w, :] = im.copy() # 将图拷贝在全0矩阵上
im = cv2.resize(im_padded, dsize=(input_size, input_size)) # 将其缩放成指定大小
score_map = np.zeros((input_size, input_size), dtype=np.uint8) # 生成空0的得分图
geo_map_channels = 5 if FLAGS.geometry == 'RBOX' else 8 # 根据不同的类型,确定通道数
geo_map = np.zeros((input_size, input_size, geo_map_channels), dtype=np.float32) # 生成全0的多边形图
training_mask = np.ones((input_size, input_size), dtype=np.uint8) # 训练mask,全为1产生的随机数大于3./8时,对图片随机裁剪并按相同方法对标记框进行裁剪,同时生成四边形的最小外接矩形:
else: # 如果产生的随机数大于background_ratio=3./8,
# 从图像中随机裁剪一个区域,扩充数据集 , 注意这里的crop_background=False
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=False)
if text_polys.shape[0] == 0:
continue
h, w, _ = im.shape
# 将图像填充到训练输入尺寸或图像的较长边
new_h, new_w, _ = im.shape
max_h_w_i = np.max([new_h, new_w, input_size]) # 选择三者中最大值
im_padded = np.zeros((max_h_w_i, max_h_w_i, 3), dtype=np.uint8) # 生成全0图
im_padded[:new_h, :new_w, :] = im.copy() # 将图像拷贝在全0图上
im = im_padded
# resize the image to input size
new_h, new_w, _ = im.shape # 新图的尺寸
resize_h = input_size
resize_w = input_size
im = cv2.resize(im, dsize=(resize_w, resize_h)) # 缩放到指定尺寸
resize_ratio_3_x = resize_w/float(new_w) # 缩放比例
resize_ratio_3_y = resize_h/float(new_h)
text_polys[:, :, 0] *= resize_ratio_3_x # 坐标x乘以缩放比例
text_polys[:, :, 1] *= resize_ratio_3_y
new_h, new_w, _ = im.shape # 最终新图的尺寸
score_map, geo_map, training_mask = generate_rbox((new_h, new_w), text_polys, text_tags)其中有两个主要的功能函数一个是crop_area():
crop_area()从图像中随机裁剪一个区域,扩充数据集, 随机数小于3./8时crop_background=True,生成背景框,
大于3./8时crop_background=False,随机裁剪图像,并同步裁剪文本标记框另一个是generate_rbox()(产生四边形的最小外接矩形):
generate_rbox这个函数,对于整个训练数据生成非常重要。它的功能是把一个任意四边形转成包含四个顶点的最小外接矩形。
该方法首先是以四边形的任意两个相邻的边为基础,求出包含四个顶点的最小平行四边形,总共有4个,然后选择面积最小的平行四边形,将其转换为矩形。这个最小外接矩形在opencv里就用一个函数就可以了,这里是自己动手实现的。

- 单个平行四边形生成
这里我们假设要求的是以边(p0, p1)和边(p1, p2)作为参考边的平行四边形。边(p0, p1)设为edge,边(p1, p2)设为forward_edge,边p0和p3设为backward_edge。首先第一步,先求出点p2和p3到边edge的距离,求出比较大的那个点,图中p2距离更远,因此选择p2。然后过点p2做一条平行于边edge的直线,该边我们定义为edge_opposite。现在,我们就有了平行四边形的三条边,接下来了来画最后一条边。采用同样的方法对比点p0和p3到直线forward_edge的距离,选择距离更远的点,图中是p3,然后过点p3做直线平行于forward_edge,最后这条直线称为forward_opposite。到这里,四条边都画出来了,分别是edge,forward_edge,edge_opposite,和forward_opposite,最后根据直线的交点更新4个顶点位置。

- 对应代码说明
这里点、边的定义和刚才图中讲解的是一一对应的。Fit_line函数表示根据两点求直线,point_dist_to_line表示的是点到直线的距离。这个if条件判断的就是点p2还是p3到边(p0, p1)的距离哪个更大,然后取更大的点,过该点画平行直线,即为edge_opposite。
# 拟合ax+by+c=0
edge = fit_line([p0[0], p1[0]], [p0[1], p1[1]]) # 边(p0, p1)设为edge
backward_edge = fit_line([p0[0], p3[0]], [p0[1], p3[1]]) # 边p0和p3设为backward_edge
forward_edge = fit_line([p1[0], p2[0]], [p1[1], p2[1]]) # 边(p1, p2)设为forward_edge
#首先第一步,先求出点p2和p3到边edge的距离 通过另外两个点到edge的距离大小来决定edge对应的平行线应该过p2还是p3(选距离大的)
if point_dist_to_line(p0, p1, p2) > point_dist_to_line(p0, p1, p3): # 点到直线距离
# 然后过点p2做一条平行于边edge的直线,该边我们定义为edge_opposite
if edge[1] == 0:
edge_opposite = [1, 0, -p2[0]]
else:
edge_opposite = [edge[0], -1, p2[1] - edge[0] * p2[0]]
else: # 然后过点p3做一条平行于边edge的直线,该边我们定义为edge_opposite
# 经过p3 - after p3
if edge[1] == 0:
edge_opposite = [1, 0, -p3[0]]
else:
edge_opposite = [edge[0], -1, p3[1] - edge[0] * p3[0]]
# move forward edge下面这段代码介绍的是刚才画最后一条边的方法。同样是判断点p0和点p3到边(p1,p2)的距离,取大的那个点,图中是p3,过p3画平行于边(p1,p2)的直线,最后根据直线的交点更新p0和p3,最终新的p0,p1,p2,和p3形成了最后的平行四边形。
new_p2 = line_cross_point(forward_edge, edge_opposite) # 求两条直线的交点
# 求p0,p3到直线p1-new_p2的距离,根据距离大的点画最后一条直线
if point_dist_to_line(p1, new_p2, p0) > point_dist_to_line(p1, new_p2, p3):
# across p0
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p0[0]]
else:
forward_opposite = [forward_edge[0], -1, p0[1] - forward_edge[0] * p0[0]]
else:
# across p3
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p3[0]]
else:
forward_opposite = [forward_edge[0], -1, p3[1] - forward_edge[0] * p3[0]]
new_p0 = line_cross_point(forward_opposite, edge)
new_p3 = line_cross_point(forward_opposite, edge_opposite)
fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0])generate_rbox()函数整体代码:
def generate_rbox(im_size, polys, tags):
h, w = im_size
poly_mask = np.zeros((h, w), dtype=np.uint8) # mask 全0
score_map = np.zeros((h, w), dtype=np.uint8) # 得分map 全0
geo_map = np.zeros((h, w, 5), dtype=np.float32) # 坐标 全0
# mask used during traning, to ignore some hard areas
training_mask = np.ones((h, w), dtype=np.uint8) # mask 全1
for poly_idx, poly_tag in enumerate(zip(polys, tags)):
poly = poly_tag[0] # [[x1,y1],[x2,y2],[x3,y3],[x4,y4]]
tag = poly_tag[1] # 文本label, bool类型,True/False
# 对每个顶点,找到经过他的两条边中较短的那条
r = [None, None, None, None] # r中每个值就是经过该点两条边中较短那条边的值
for i in range(4):
# linalg = linear(线性)+algebra(代数),norm则表示范数。默认为二范数
r[i] = min(np.linalg.norm(poly[i] - poly[(i + 1) % 4]), # 就是根据两点坐标求出两点间距离 d=sqrt((x1-x2)^2+(y1-y2)^2)
np.linalg.norm(poly[i] - poly[(i - 1) % 4]))
# 对原始标记框进行0.3倍边长的缩放,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
shrinked_poly = shrink_poly(poly.copy(), r).astype(np.int32)[np.newaxis, :, :]
# score_map是框类像素均为1,poly_mask则按文字框个数递增填充
cv2.fillPoly(score_map, shrinked_poly, 1) # 将相应部分填充为1
cv2.fillPoly(poly_mask, shrinked_poly, poly_idx + 1)
# if the poly is too small, then ignore it during training
# 如果文本框标签太小或者txt中没具体标记是什么内容,即*或者###,则加掩模,训练时忽略该部分
poly_h = min(np.linalg.norm(poly[0] - poly[3]), np.linalg.norm(poly[1] - poly[2]))
poly_w = min(np.linalg.norm(poly[0] - poly[1]), np.linalg.norm(poly[2] - poly[3]))
if min(poly_h, poly_w) < FLAGS.min_text_size: # 4条边中最小的边小于最小txt的尺寸,
cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0) # 将标记为*或者###的文本框掩模置0
if tag:
cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0)
# 当前新加入的文本框区域像素点
xy_in_poly = np.argwhere(poly_mask == (poly_idx + 1))
# if geometry == 'RBOX':
# 对任意两个顶点的组合生成一个平行四边形 - generate a parallelogram for any combination of two vertices
# 对于四个顶点,确定两个顶点组成的一条边,再结合剩下的两个点可以得到两个包含这四个点的平行四边形
# 这里就是遍历两个顶点的组合,生成8个平行四边形
fitted_parallelograms = []
for i in range(4):
# 选中p0和p1的连线边,生成两个平行四边形
p0 = poly[i]
p1 = poly[(i + 1) % 4]
p2 = poly[(i + 2) % 4]
p3 = poly[(i + 3) % 4]
# 拟合ax+by+c=0
edge = fit_line([p0[0], p1[0]], [p0[1], p1[1]]) # 边(p0, p1)设为edge
backward_edge = fit_line([p0[0], p3[0]], [p0[1], p3[1]]) # 边p0和p3设为backward_edge
forward_edge = fit_line([p1[0], p2[0]], [p1[1], p2[1]]) # 边(p1, p2)设为forward_edge
#首先第一步,先求出点p2和p3到边edge的距离 通过另外两个点到edge的距离大小来决定edge对应的平行线应该过p2还是p3(选距离大的)
if point_dist_to_line(p0, p1, p2) > point_dist_to_line(p0, p1, p3): # 点到直线距离
# 然后过点p2做一条平行于边edge的直线,该边我们定义为edge_opposite
if edge[1] == 0:
edge_opposite = [1, 0, -p2[0]]
else:
edge_opposite = [edge[0], -1, p2[1] - edge[0] * p2[0]]
else: # 然后过点p3做一条平行于边edge的直线,该边我们定义为edge_opposite
# 经过p3 - after p3
if edge[1] == 0:
edge_opposite = [1, 0, -p3[0]]
else:
edge_opposite = [edge[0], -1, p3[1] - edge[0] * p3[0]]
# move forward edge
# 第一个平行四边形保留p1和p2的连线
new_p0 = p0
new_p1 = p1
new_p2 = p2
new_p3 = p3
new_p2 = line_cross_point(forward_edge, edge_opposite) # 求两条直线的交点
# 求p0,p3到直线p1-new_p2的距离,根据距离大的点画最后一条直线
if point_dist_to_line(p1, new_p2, p0) > point_dist_to_line(p1, new_p2, p3):
# across p0
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p0[0]]
else:
forward_opposite = [forward_edge[0], -1, p0[1] - forward_edge[0] * p0[0]]
else:
# across p3
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p3[0]]
else:
forward_opposite = [forward_edge[0], -1, p3[1] - forward_edge[0] * p3[0]]
new_p0 = line_cross_point(forward_opposite, edge)
new_p3 = line_cross_point(forward_opposite, edge_opposite)
fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0])
# or move backward edge
# 第二个平行四边形保留p0和p3的连线
new_p0 = p0
new_p1 = p1
new_p2 = p2
new_p3 = p3
new_p3 = line_cross_point(backward_edge, edge_opposite)
if point_dist_to_line(p0, p3, p1) > point_dist_to_line(p0, p3, p2):
# across p1
if backward_edge[1] == 0:
backward_opposite = [1, 0, -p1[0]]
else:
backward_opposite = [backward_edge[0], -1, p1[1] - backward_edge[0] * p1[0]]
else:
# across p2
if backward_edge[1] == 0:
backward_opposite = [1, 0, -p2[0]]
else:
backward_opposite = [backward_edge[0], -1, p2[1] - backward_edge[0] * p2[0]]
new_p1 = line_cross_point(backward_opposite, edge)
new_p2 = line_cross_point(backward_opposite, edge_opposite)
fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0])
# 选定面积最小的平行四边形
areas = [Polygon(t).area for t in fitted_parallelograms]
parallelogram = np.array(fitted_parallelograms[np.argmin(areas)][:-1], dtype=np.float32)
# sort the polygon
parallelogram_coord_sum = np.sum(parallelogram, axis=1)
min_coord_idx = np.argmin(parallelogram_coord_sum)
parallelogram = parallelogram[
[min_coord_idx, (min_coord_idx + 1) % 4, (min_coord_idx + 2) % 4, (min_coord_idx + 3) % 4]]
# 得到外包矩形即旋转角
rectange = rectangle_from_parallelogram(parallelogram)
rectange, rotate_angle = sort_rectangle(rectange)
p0_rect, p1_rect, p2_rect, p3_rect = rectange
# 对当前新加入的文本框区域像素点,根据其到矩形四边的距离修改geo_map
for y, x in xy_in_poly:
point = np.array([x, y], dtype=np.float32)
# top
geo_map[y, x, 0] = point_dist_to_line(p0_rect, p1_rect, point) # 点到直线的距离
# right
geo_map[y, x, 1] = point_dist_to_line(p1_rect, p2_rect, point)
# down
geo_map[y, x, 2] = point_dist_to_line(p2_rect, p3_rect, point)
# left
geo_map[y, x, 3] = point_dist_to_line(p3_rect, p0_rect, point)
# angle
geo_map[y, x, 4] = rotate_angle
return score_map, geo_map, training_mask最后返回的3个值:
- score_map,
h, w = im_size
score_map = np.zeros((h, w), dtype=np.uint8) # 得分map 全0
cv2.fillPoly(score_map, shrinked_poly, 1) # 将文本相应部分填充为1 - geo_map,
h, w = im_size geo_map = np.zeros((h, w, 5), dtype=np.float32) # 坐标 全0,框内像素点到矩形边的距离+矩形角度...
for y, x in xy_in_poly: point = np.array([x, y], dtype=np.float32) # top geo_map[y, x, 0] = point_dist_to_line(p0_rect, p1_rect, point) # 点到直线的距离 # right geo_map[y, x, 1] = point_dist_to_line(p1_rect, p2_rect, point) # down geo_map[y, x, 2] = point_dist_to_line(p2_rect, p3_rect, point) # left geo_map[y, x, 3] = point_dist_to_line(p3_rect, p0_rect, point) # angle geo_map[y, x, 4] = rotate_angle # 矩形角度
- training_mask
h, w = im_size training_mask = np.ones((h, w), dtype=np.uint8) # mask 全1 tag = poly_tag[1] # 文本label, bool类型,True/False,True表示文本框内容难以识别 ... if min(poly_h, poly_w) < FLAGS.min_text_size: # 4条边中最小的边小于最小txt的尺寸, cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0) # 将标记为*或者###的文本框掩模置0 if tag: cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0)
训练数据预处理部分关键点大概就这些。
二,model.model()网络结构搭建,特征图生成
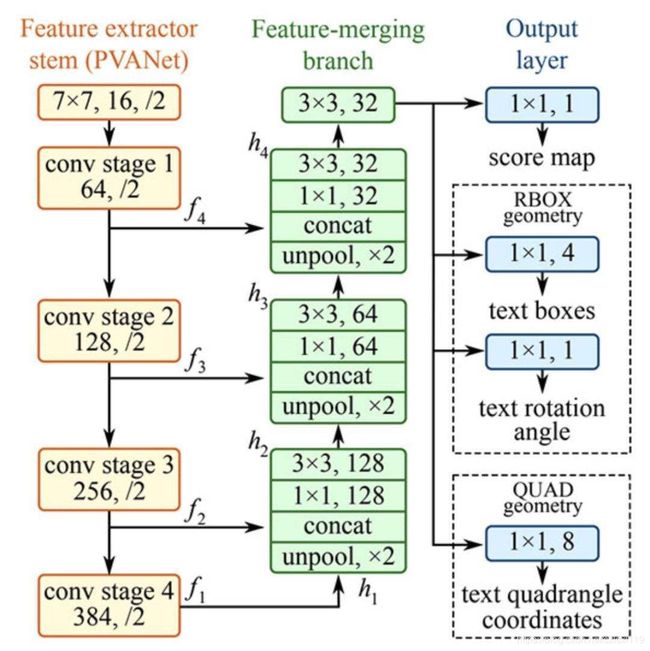
如上图所示,EAST网络结构主要包括3个部分,
第一份是上图左边的黄色区域(Feature extractorstem PVANet),该部分主要运用基本的卷积模块,从原图提取特征图。
该部分在代码中是通过以下代码实现的(具体我就不展开了):
# 先将图片经过resnet_v1网络得到resnet_v1的全部stage的输出,存在end_points里面
logits, end_points = resnet_v1.resnet_v1_50(images, is_training=is_training, scope='resnet_v1_50')第二部分是上图中间绿色区域(Feature-merging branch),主要是将不同大小的特征图进行融合
# **********下面这部分是FCN结构图中间绿色Fearture_merging的部分,上采样并合并特征图*************
f = [end_points['pool5'], end_points['pool4'],
end_points['pool3'], end_points['pool2']] # f=[(?,?,?,2048),(?,?,?,512),(?,?,?,256),(?,?,?,32)]
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
g = [None, None, None, None]
h = [None, None, None, None]
num_outputs = [None, 128, 64, 32] # 输出通道数
for i in range(4):
if i == 0:
h[i] = f[i]
else:
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1) # 第i-1层上采样和第i层合并,再卷积
h[i] = slim.conv2d(c1_1, num_outputs[i], 3) # 3*3卷积核
if i <= 2: # 对0,1,2进行上采样
g[i] = unpool(h[i]) # 上采样
else: # i==3
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))第三部分是上图右边蓝色区域(Output layer),是预测层,包括三个部分,一个是一通道的分类任务输出score map,另两个分别表示检测框。采用RBOX有5个通道,分别对应我们前面提到的d1,d2,d3,d4和角度theta。采用QUAD则表示采用4个点8个坐标来表示四边形,有八个通道。
# **********下面这部分是Output_layer的部分*************
# 这里,我们使用稍微不同的方式进行回归,先使用sigmoid限制回归范围,这也与角度图有关
# 得分
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 文本框坐标
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
# 文本的旋转角度
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2 # angle is between [-45, 45]
# 这里将坐标与角度信息合并输出
F_geometry = tf.concat([geo_map, angle_map], axis=-1)最后返回 F_score, F_geometry
三,model.loss()损失函数
EAST的损失部分包含分类损失和回归损失,具体计算公式如下:

3.1 分类损失:
在实际代码中,分类损失计算代码如下(上图分类损失是用交叉熵,实际代码中使用的是dice损失):
# 分类loss
classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# scale classification loss to match the iou loss part
classification_loss *= 0.01# 分类损失计算
def dice_coefficient(y_true_cls, y_pred_cls,
training_mask):
eps = 1e-5
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask) # 交集
union = tf.reduce_sum(y_true_cls * training_mask) + tf.reduce_sum(y_pred_cls * training_mask) + eps # 并集
loss = 1. - (2 * intersection / union)
tf.summary.scalar('classification_dice_loss', loss)
return loss3.2 回归损失:
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3)
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt) # gt面积
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred) # 预测面积
w_union = tf.minimum(d2_gt, d2_pred) + tf.minimum(d4_gt, d4_pred) # w交集
h_union = tf.minimum(d1_gt, d1_pred) + tf.minimum(d3_gt, d3_pred) # h交集
area_intersect = w_union * h_union # 交集面积
area_union = area_gt + area_pred - area_intersect # 并集面积
L_AABB = -tf.log((area_intersect + 1.0)/(area_union + 1.0)) # (交集面积+1)/(并集面积+1)取对数
# 角度误差函数
L_theta = 1 - tf.cos(theta_pred - theta_gt)
tf.summary.scalar('geometry_AABB', tf.reduce_mean(L_AABB * y_true_cls * training_mask))
tf.summary.scalar('geometry_theta', tf.reduce_mean(L_theta * y_true_cls * training_mask))
# 加权和得到geo los
L_g = L_AABB + 20 * L_theta最后返回:
# 考虑training_mask,较小的文本和难易识别的文本不参与损失计算
return tf.reduce_mean(L_g * y_true_cls * training_mask) + classification_losstraining_mask再回顾:
h, w = im_size
training_mask = np.ones((h, w), dtype=np.uint8) # mask 全1
tag = poly_tag[1] # 文本label, bool类型,True/False,True表示文本框内容难以识别
...
if min(poly_h, poly_w) < FLAGS.min_text_size: # 4条边中最小的边小于最小txt的尺寸,
cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0) # 将标记为*或者###的文本框掩模置0
if tag:
cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0)训练后续...